AlgebraNets
Jordan Hoffmann, Simon Schmitt, Simon Osindero, Karen Simonyan, Erich Elsen
Статья: https://arxiv.org/abs/2006.07360
Очень прикольная работа от DeepMind. Из серии “А что, так можно было?!”.
Все привыкли, что нейросети работают над полем вещественных чисел — входы, выходы, веса, активации — всё вещественное. Но как говорил нам Кантор, «сущность математики заключена в её свободе». Алгебра вещественных чисел — не единственная возможная алгебра и, что, если есть другие полезные алгебры для работы нейросетей? А они есть!
И в общем подходы уже были: с комплексными числами — Deep Complex Networks (https://arxiv.org/abs/1705.09792), Complex Gated Recurrent Neural Networks (https://arxiv.org/abs/1806.08267), Harmonic Networks (https://arxiv.org/abs/1612.04642), Complex Transformer (https://arxiv.org/abs/1910.10202), да и вообще давно уже дофига всего было (https://www.worldscientific.com/worldscibooks/10.1142/5345); с кватернионами — Deep Quaternion Networks (https://arxiv.org/abs/1712.04604), Quaternion Recurrent Neural Networks (https://arxiv.org/abs/1806.04418); и с октонионами — Deep Octonion Networks (https://arxiv.org/abs/1903.08478).
Теперь более общее решение — давайте заменим алгебру действительных чисел другими ассоциативными алгебрами: скаляры — кортежами (tuple), а вещественное умножение на умножение кортежей.
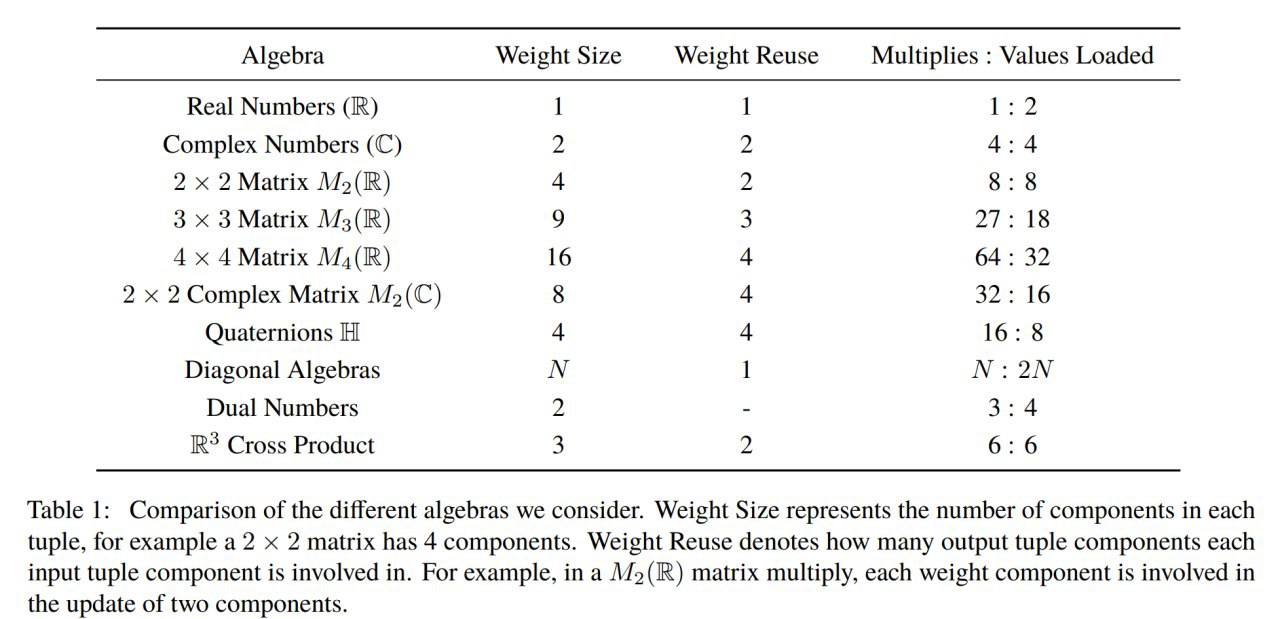
В качестве альтернативных алгебр предлагаются: комплексные числа, квадратные матрицы вещественных чисел размера 2, 3 и 4, квадратные комплексные матрицы размера 2, кватернионы, диагональные алгебры, дуальные числа и алгебра трёхэлементных векторов с векторным произведением.
Зачем вообще туда копать? Ради большей эффективности по параметрам (их может потребоваться меньше, чем у вещественных альтернатив) или по вычислениям (например, количество операций на каждое загруженное значение может быть разным и это может быть важно при оптимизации под конкретное железо). Для вещественных чисел на каждые два загруженных числа одно умножение, у комплексных уже на каждые 4 загруженных значения 4 умножения, у 4x4 вещественных матриц на 32 значения 64 умножения. Может сыграть для задач, где производительность ограничена пропускной способностью шины ускорителя.
Ну и вообще это открывает другое измерение в поиске новых архитектур и правильных inductive biases.
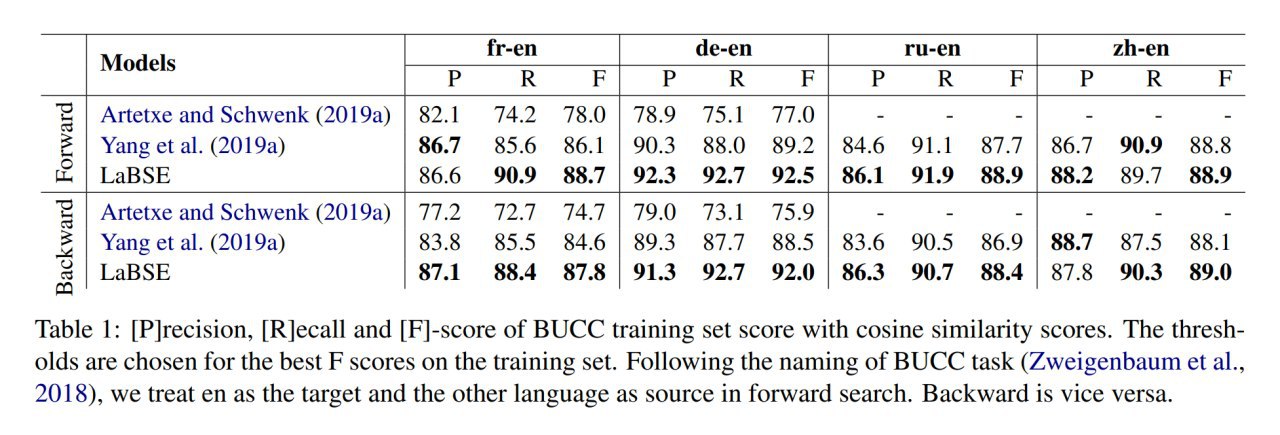
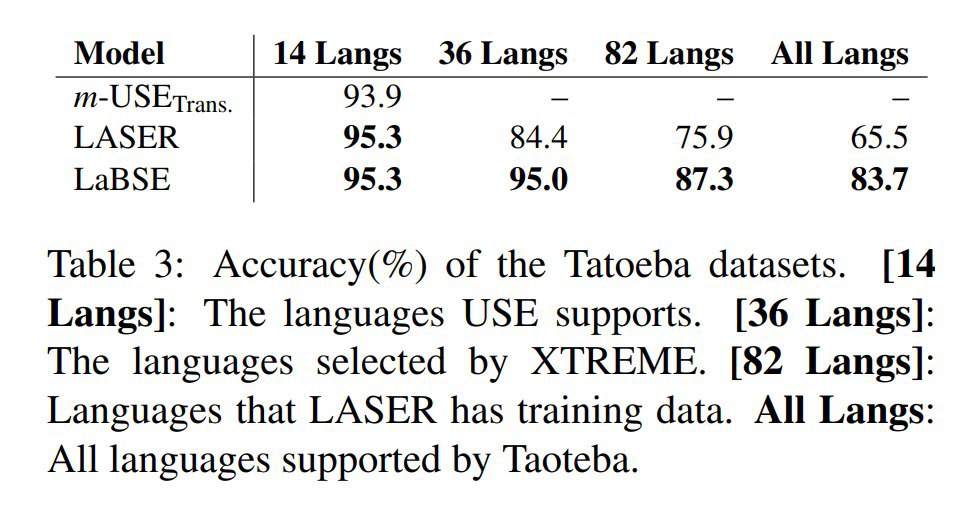
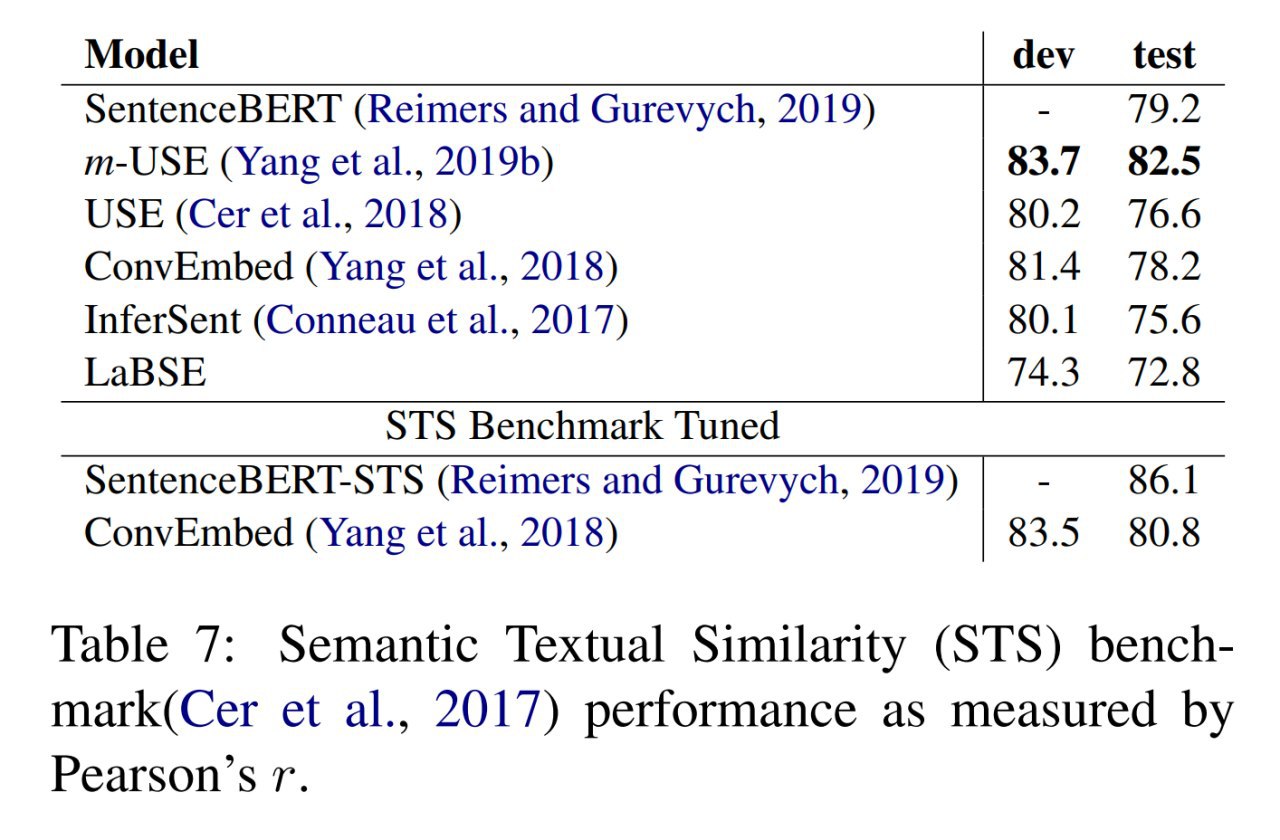
Всё это добро проверяют на больших моделях на ImageNet, Enwik8 и WikiText. Результаты интересные.
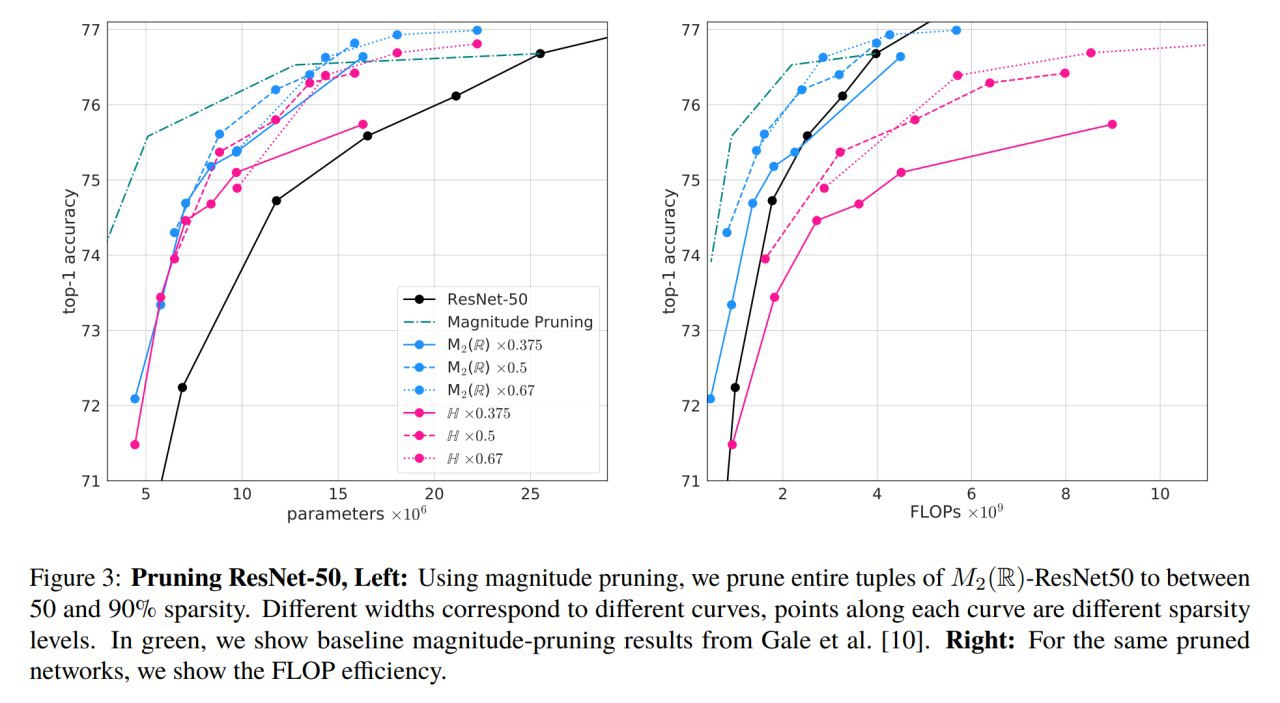
На ImageNet получают более эффективные по параметрам ResNet и MobileNet, требующие не больше FLOPS по сравнению с бейзлайном. Есть также интересные результаты прунинга модифицированных ResNet, которые получаются более вычислительно эффективными. Transformer-XL на Enwik8 требует меньше параметров для того же качества. Модифицированный GRU также весьма эффективен.
Особенный фаворит из алгебр — это квадратные вещественные матрицы размера 2, они лучше всех ранее рассмотренных алгебр, и по FLOPSам не уступают вещественным числам.
В общем интересное направление. Достойно продолжения.