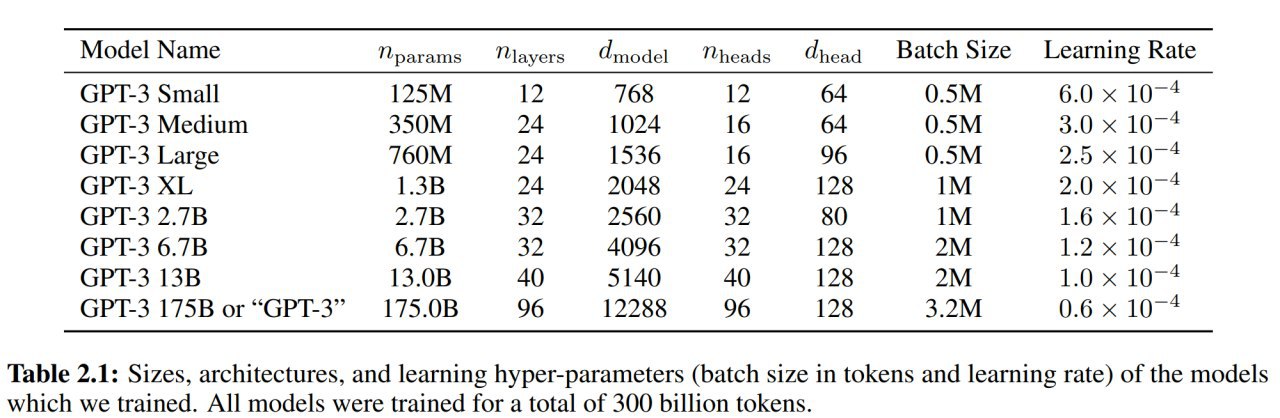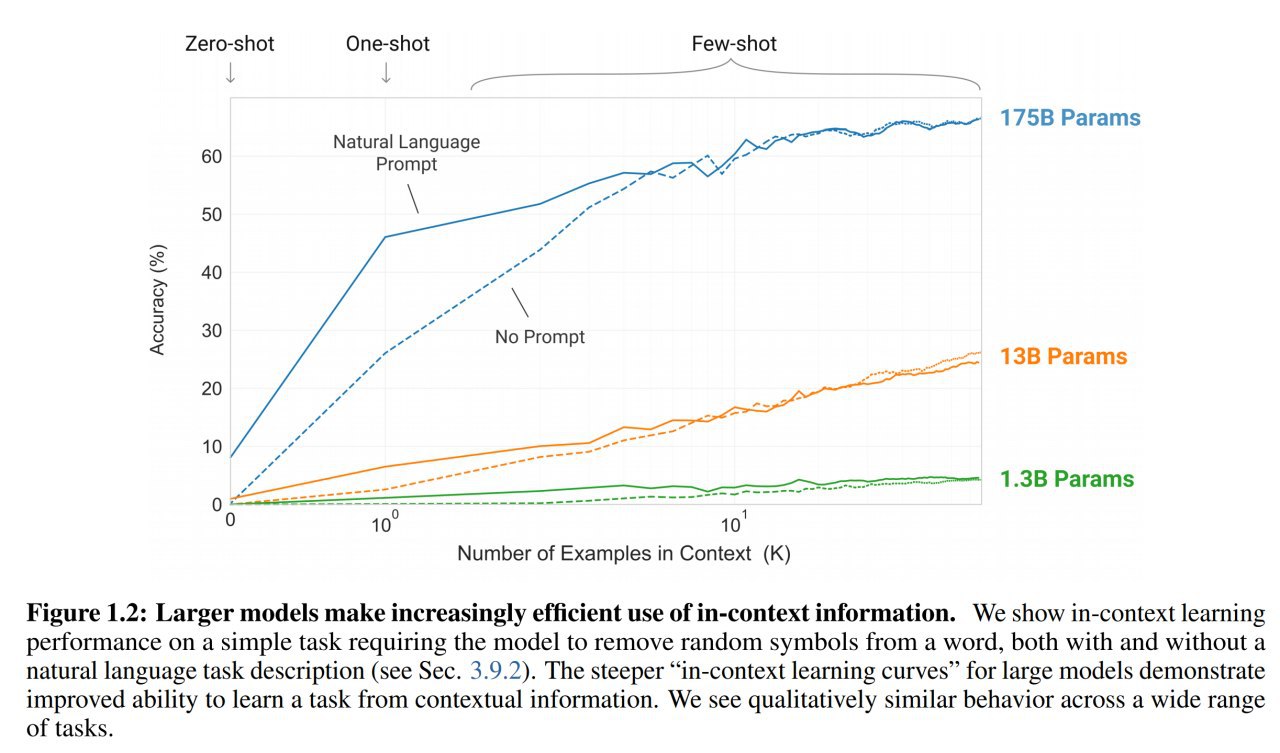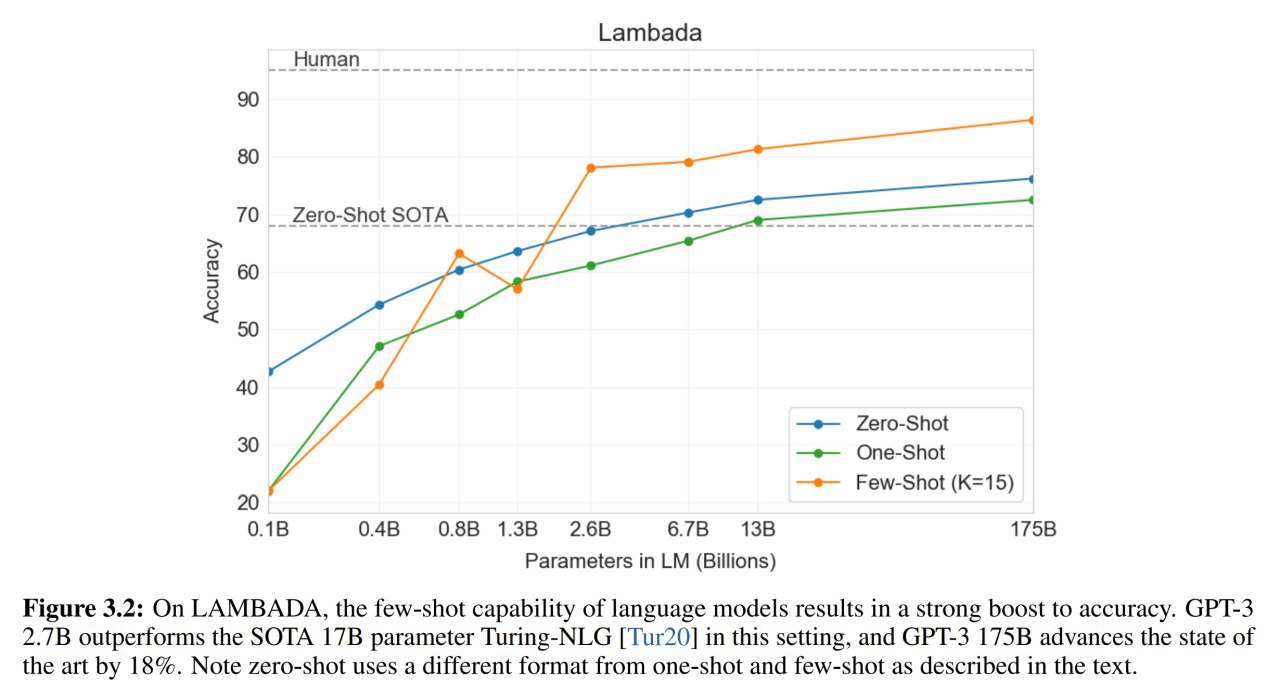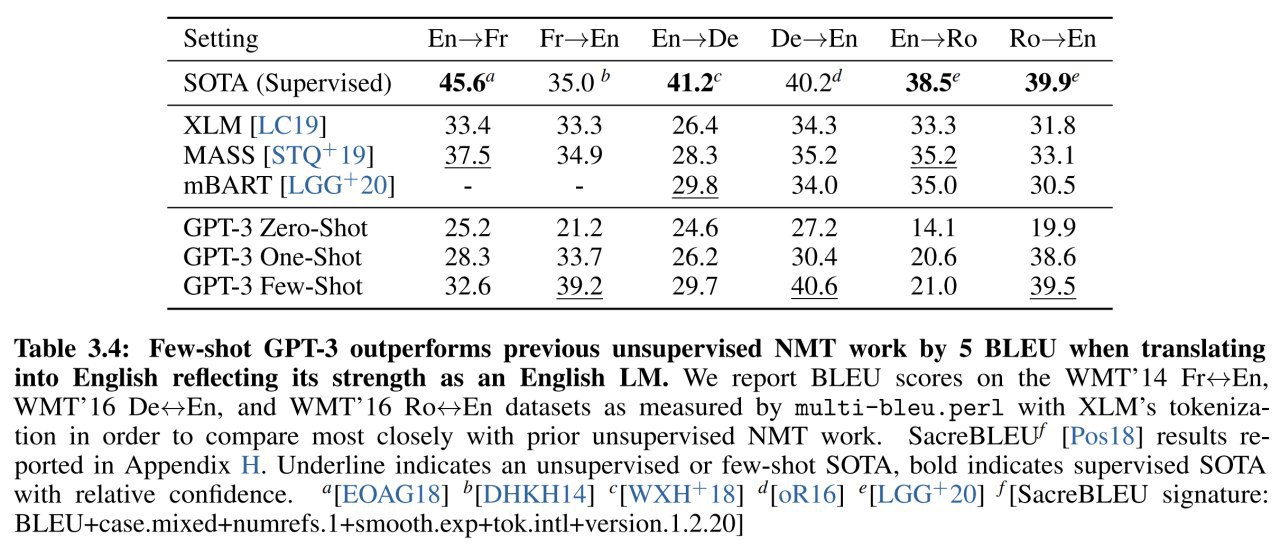

ETC: Encoding Long and Structured Data in Transformers
Joshua Ainslie, Santiago Ontanon, Chris Alberti, Philip Pham, Anirudh Ravula, Sumit Sanghai
Статья: https://arxiv.org/abs/2004.08483
Ещё трансформеры для больших документов, теперь Extended Transformer Construction (ETC) от Гугла. Кстати, гугловый же Reformer тоже умеет с длинными последовательностями работать, и он теперь есть в Huggingface (https://twitter.com/huggingface/status/1263850138595987457).
Но ETC это больше, чем просто “длинный” трансформер, а ещё и новый механизм, совмещающий локальное и глобальное внимание. Он же позволяет и добавлять структурированные данные. Выглядит полезно, let’s dive in.
Первичная проблема всё та же -- квадратичная сложность внимания и как следствие короткий attention span ванильных (да и многих приперчённых) трансформеров. 512 токенов это как-то очень мало.
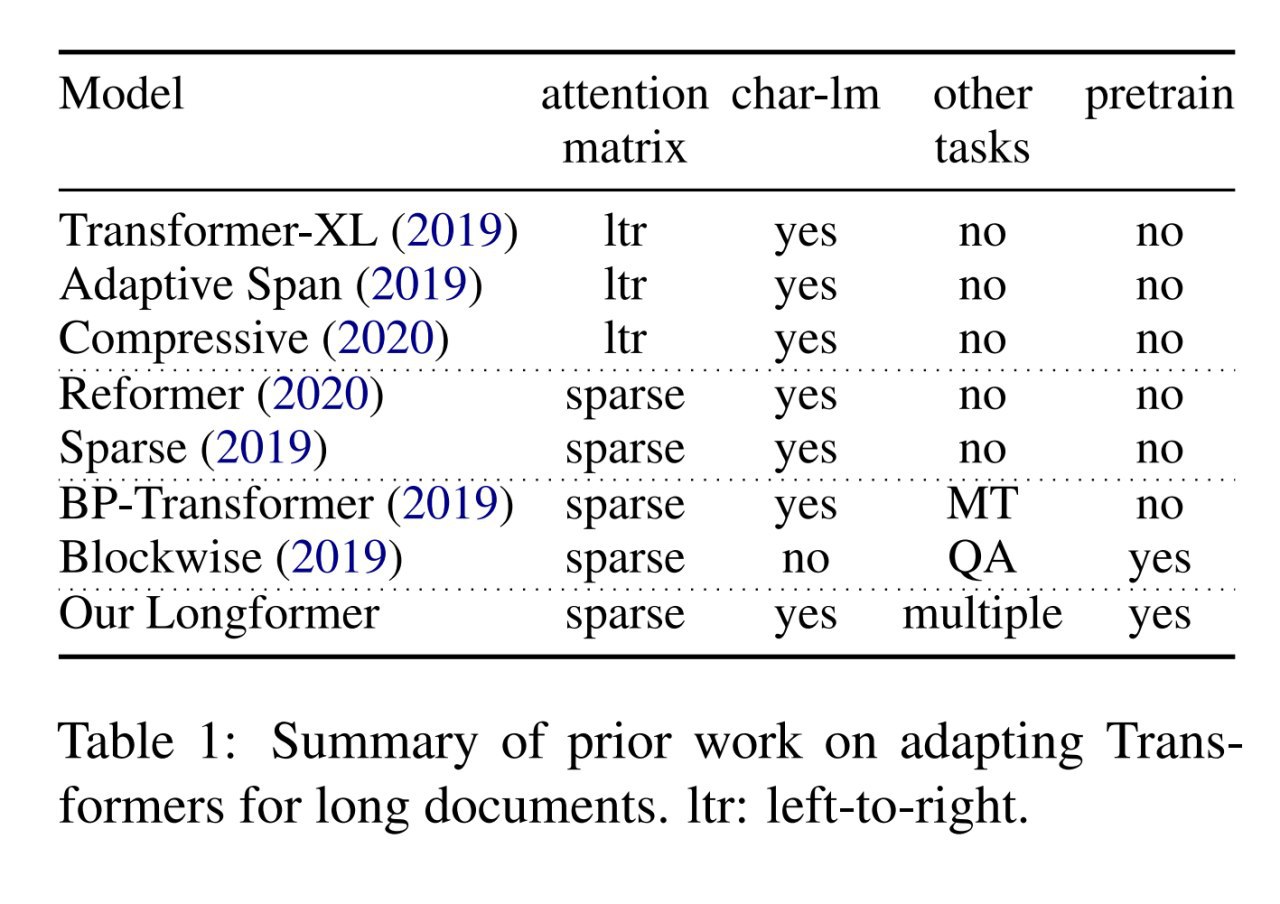
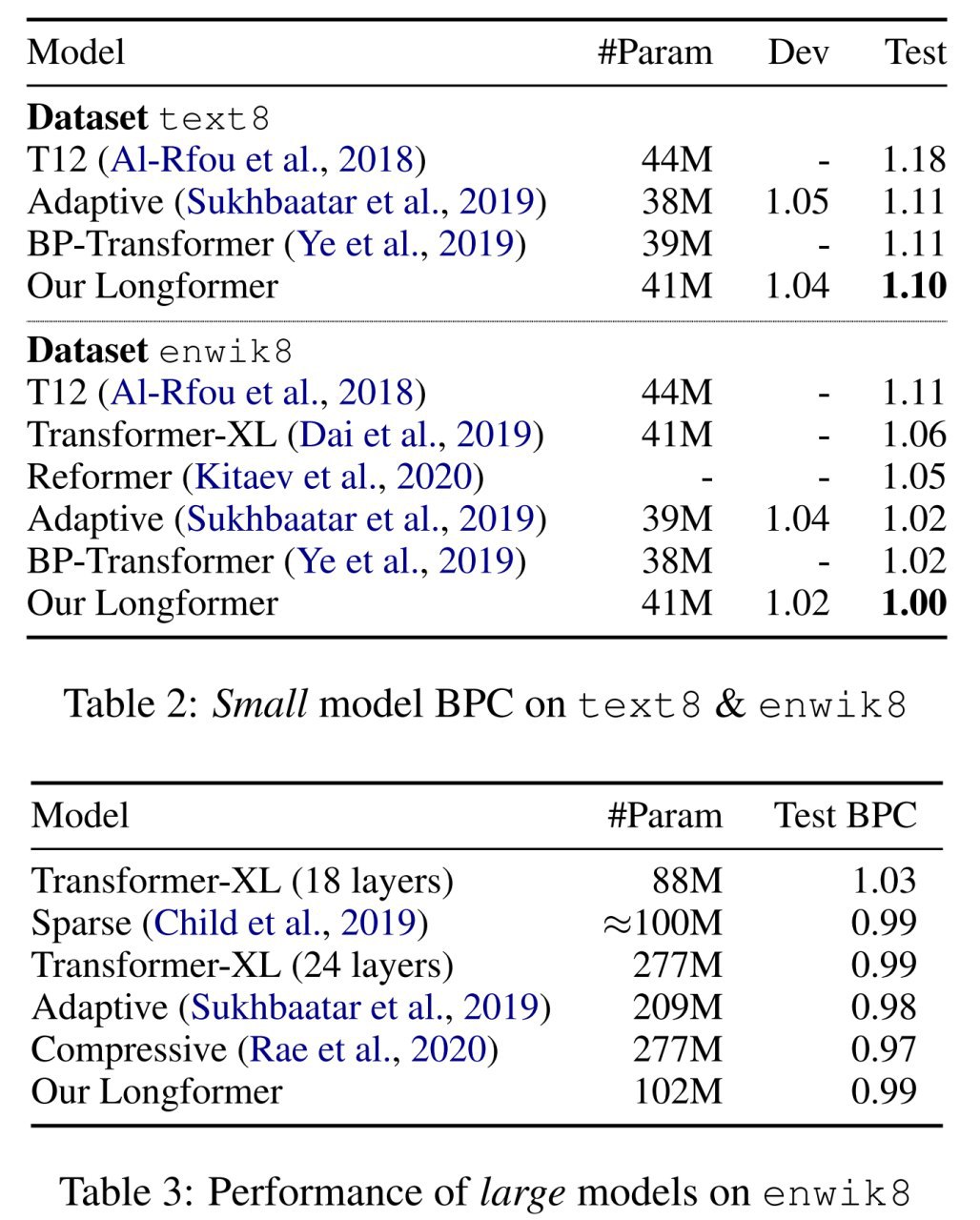
Подходов к этому много, мы уже перечисляли часть в предыдущих постах по теме. В работе есть наглядная картинка про кучку наиболее известных.
В работе выбран подход замены механизма внимания на более гибкий. В этом смысле работа находится в той же группе, что и Longformer из предыдущего поста, и идейно сильно на неё похожа.
В работе рассматривают только энкодер трансформера, декодер оставляют для будущих работ.
Какие изменения относительно ванили.
1. Относительное позиционное кодирование.
Уже было в работе Peter Shaw “Self-Attention with Relative Position Representations” (https://arxiv.org/abs/1803.02155), показало свою эффективность, странно, что ещё не пришло всюду.
Если в двух словах, то задаётся окно в C позиций, заводится 2C+1 (влево-вправо) меток относительных позиций которыми метятся рёбра (граф по сути) между парами входных токенов, для каждой метки выучивается свой эмбеддинг, который модифицирует механизм внимания.
Плюс подхода в том, что не затачиваемся на абсолютные позиции и вообще не привязаны к размеру входа. И на самом деле можно вообще разные графы и отношения кодировать, если хочется.
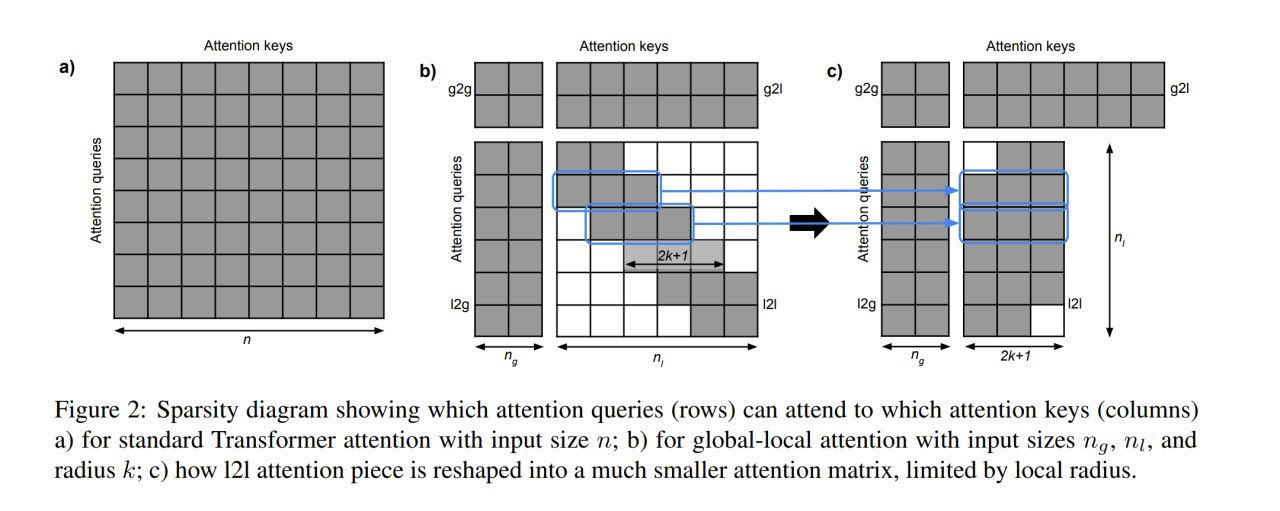
2. Глобально-локальное внимание.
Вход трансформера разбивается на две последовательности: global input (небольшое количество дополнительных токенов) и long input (обычный вход, с которым будет работать трансформер), которые обрабатываются отдельно.
Внимание соответственно разделяется на 4 отдельных куска:
- global-to-global (g2g)
- global-to-long (g2l)
- long-to-global (l2g)
- long-to-long (l2l)
Самая жирная часть -- это l2l, внимание в ней ограничиваем радиусом k (то есть окном размера k, как в Longformer). Остальные куски внимания неограничены (каждый токен может смотреть на любой другой).
Если k=1 и размер глобального внимания тоже 1, то получаем Star-Transformer (https://arxiv.org/abs/1902.09113), весьма интересную, но почему-то малоизвестную модель.
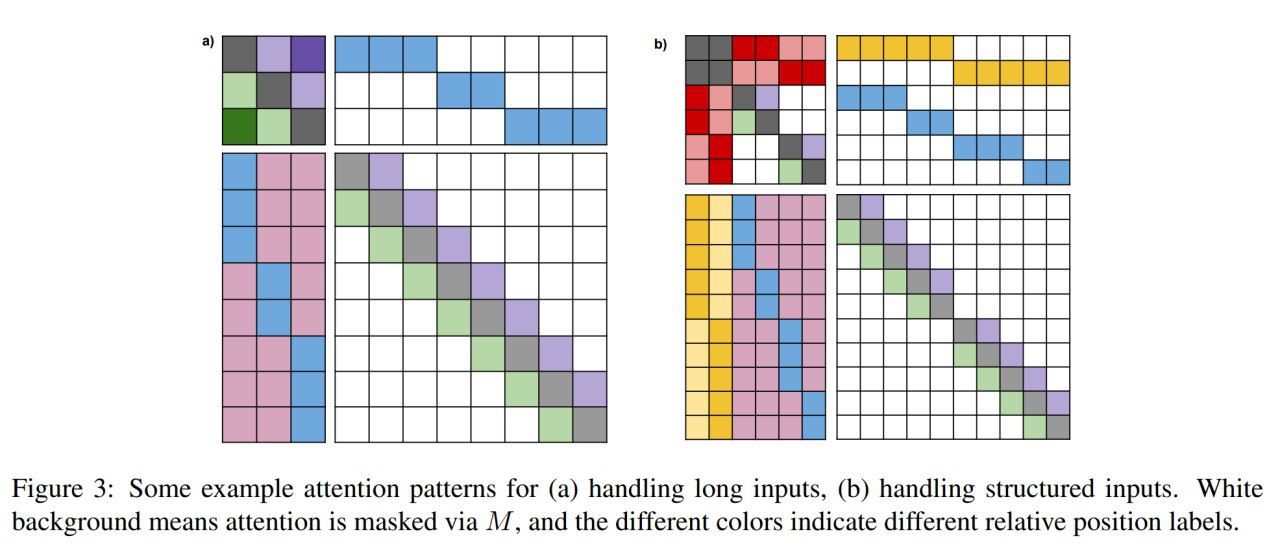
Для пущей гибкости для всех этих вниманий заводим отдельные булевые матрицы, чтобы можно было более тонко контролировать кто на что смотрит (по сути вводить inductive bias или задавать структуру задачи).
Также ради оптимизации и ускорения эти 4 части внимания внутри представляются двумя кусками.
Собственно работа с длинными последовательностями устроена так. Входные токены (например, word pieces) кладутся в длинный вход. Дальше, в зависимости от структуры входа подразумевается какое-то его разбиение на сегменты (предложения, например, или параграфы). Кладём на каждый сегмент один сегментный токен в глобальный вход, используя относительные позиционные эмбеддинги, чтобы эти сегменты между собой упорядочить. Ну и вообще с этими относительными метками можно по-разному играть, а в матрицы добавлять всякие маски, если надо. Богато.
Можно также вводить в модель структурированные данные: порядок между предложениями, иерархию, и в общем что придумаете и что можно закодировать в виде графа.
3. Предобучение модели
Делается через стандартный Masked Language Model (MLM) как в берте + Contrastive Predictive Coding (CPC) вместо Next Sentence Prediction (NSP), от которого уже много где отказались.