Contrastive Code Representation Learning
Paras Jain, Ajay Jain, Tianjun Zhang, Pieter Abbeel, Joseph E. Gonzalez, Ion Stoica
Статья:
https://arxiv.org/abs/2007.04973Код:
https://github.com/parasj/contracode Про большие модели продолжу в следующий раз, а сейчас расскажу про ещё один кейс использования contrastive learning, но теперь для задачи работы с кодом! Благо вышла свежая работа от команды из Беркли.
Как и в случае SimCLR, идея в том, чтобы в режиме self-supervised с применением contrastive loss выучить какие-то интересные представления для кода, на которых потом можно файнтюнить интересные и полезные задачи -- суммаризацию кода, предсказание типов, автокомплит, определение ошибок и т.д.
Потенциал идеи огромен. Как минимум появятся более удобные тулы, позволяющие программистам удобнее и быстрее создавать надёжный код. Как максимум, генерация неотличимого от человеческого кода может стать обычным делом, как сейчас происходит с языком. Кстати, если вы ещё не видели примеры, как GPT-3 (зафайнтюненый на гитхабе) умеет писать питоновский код по текстовому описанию функций (
https://www.youtube.com/watch?v=fZSFNUT6iY8) или отвечает на вопросы телефонного интервью по Ruby (
https://twitter.com/lacker/status/1279136788326432771, этот вроде дефолтный), гляньте, это просветляет.
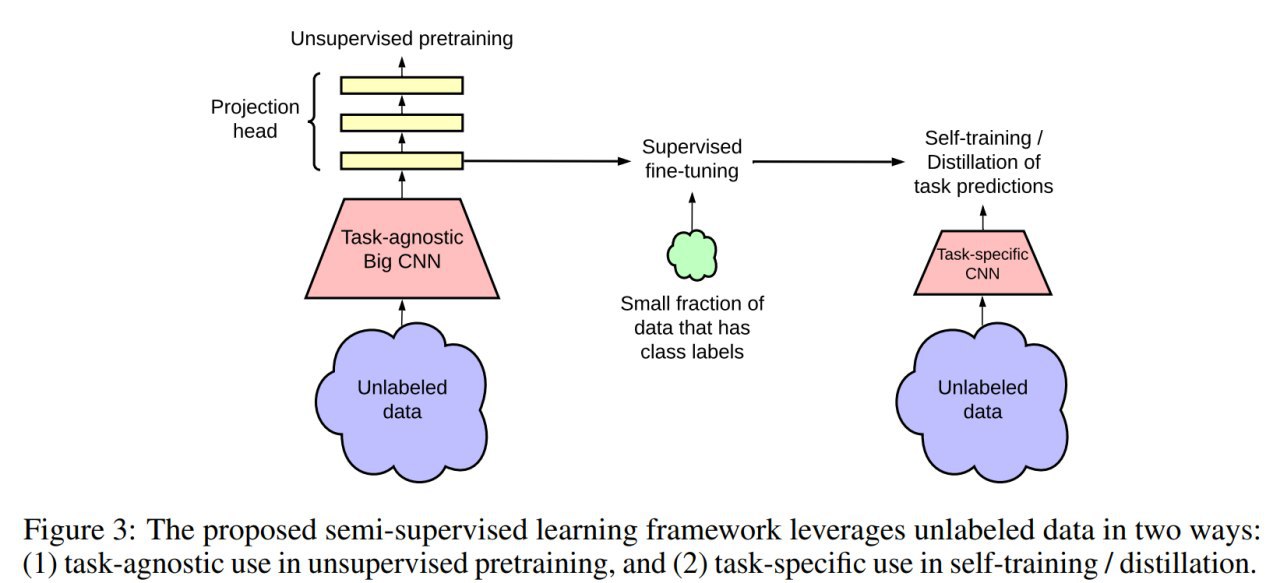
Проблема с кодом -- это отсутствие больших размеченных датасетов. Можно, конечно, заходить со стороны генерации данных, но получается несколько однобоко, по сравнению с реальным кодом. Есть неразмеченные, и с ними надо что-то делать. Self-supervised pre-training как раз подходящий инструмент для этого.
Уже были заходы на прикрутить берт к коду, например, CodeBERT (
https://arxiv.org/abs/2002.08155) или CuBERT (
https://arxiv.org/abs/2001.00059), были и другие заходы на эмбеддинги для кода (code2vec, code2seq и т.п.), но, кажется, результат пока не очень.
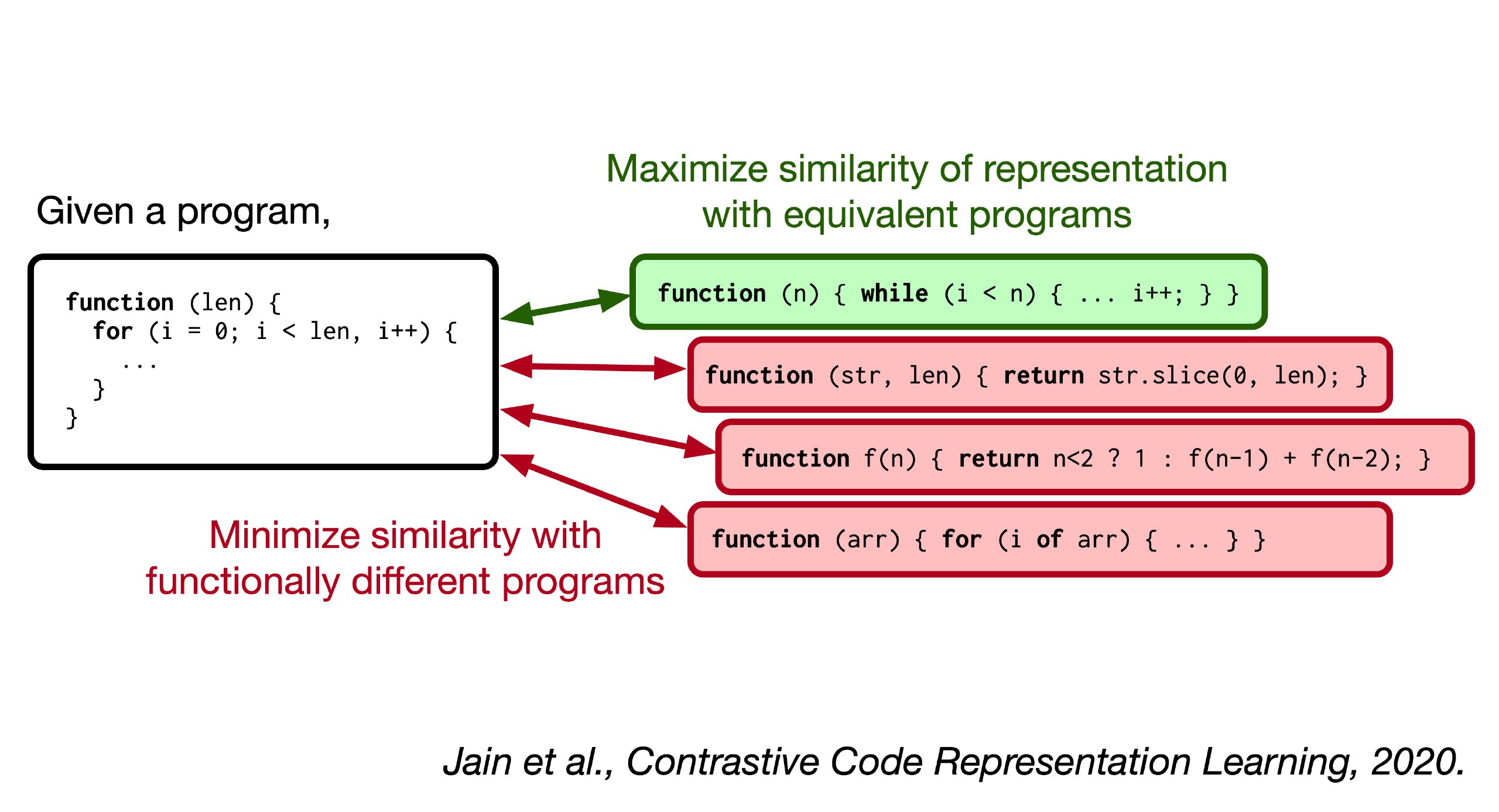
Авторы исходят из посылки, что программы с одинаковой функциональностью должны обладать одинаковыми репрезентациями (а с разной, соответственно, разными). Уже попахивает contrastive learning.
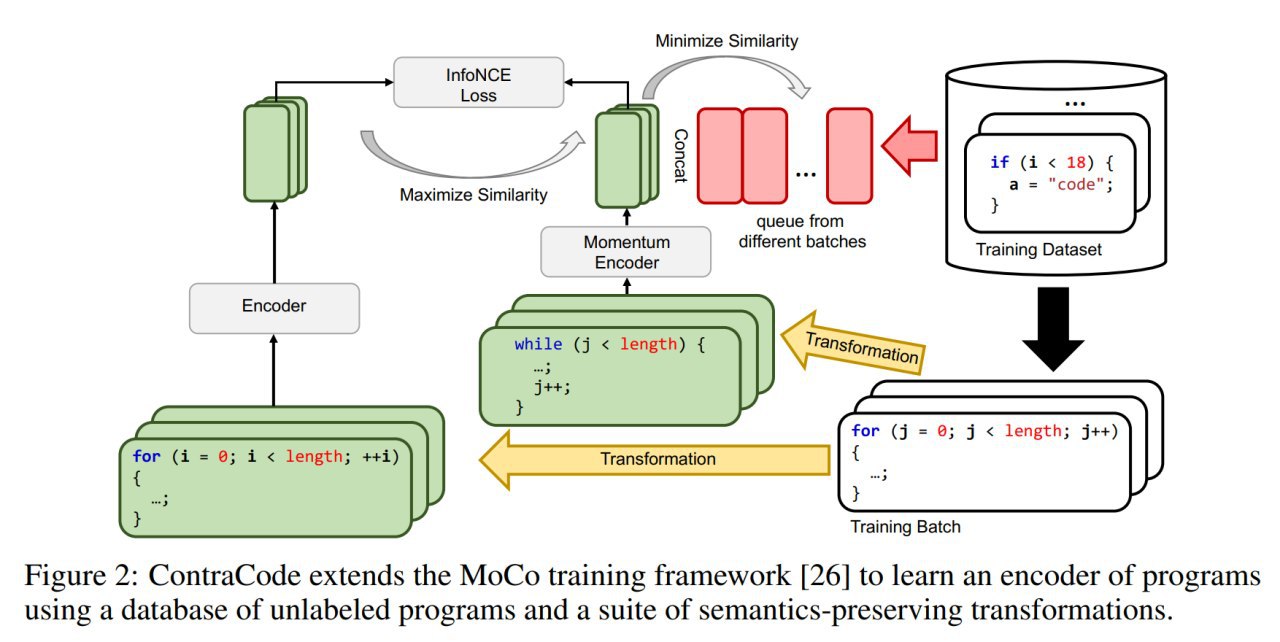
По имеющимся программам определить их эквивалентность не очень-то просто (в общем случае, конечно, вообще нельзя), но можно попробовать нагенерить вариантов различными модификациями имеющихся программ (типа аугментация для кода). Авторский подход под названием ContraCode использует это для выучивания интересных репрезентаций через contrastive learning.
Для генерации эквивалентных вариантов используют переименование переменных, переформатирование кода, обфускацию, вставку и удаление мёртвого кода, сворачивание констант, конвертацию типов (например, true в 1), плюс ещё subword regularization (влияет на токенизацию, но в целом это кажется не про модификацию кода) и сэмплирование строк (например, выбирают 90% строк, что конечно приводит к не-эквивалентности, но зато работает как регуляризация).
На этих вариантах делают contrastive pre-training, минимизируя InfoNCE loss (
https://arxiv.org/abs/1807.03748), который определяет близость программ через скалярное произведение их эмбеддингов. Позитивные пары берутся из пар эквивалентных программ (полученных трансформацией), негативные из прошлых программ (хранятся в большой очереди, шансов что там затерялось что-то эквивалентное, мало).
Для обучения используется процедура аналогичная MoCo (конкурент SimCLR,
https://arxiv.org/abs/1911.05722), где один энкодер обучается SGD, а второй архитектурно идентичный momentum encoder через EMA (exponential moving average) параметров первого энкодера. Сам энкодер может быть разным, здесь проверяют на BiLSTM и трансформере.
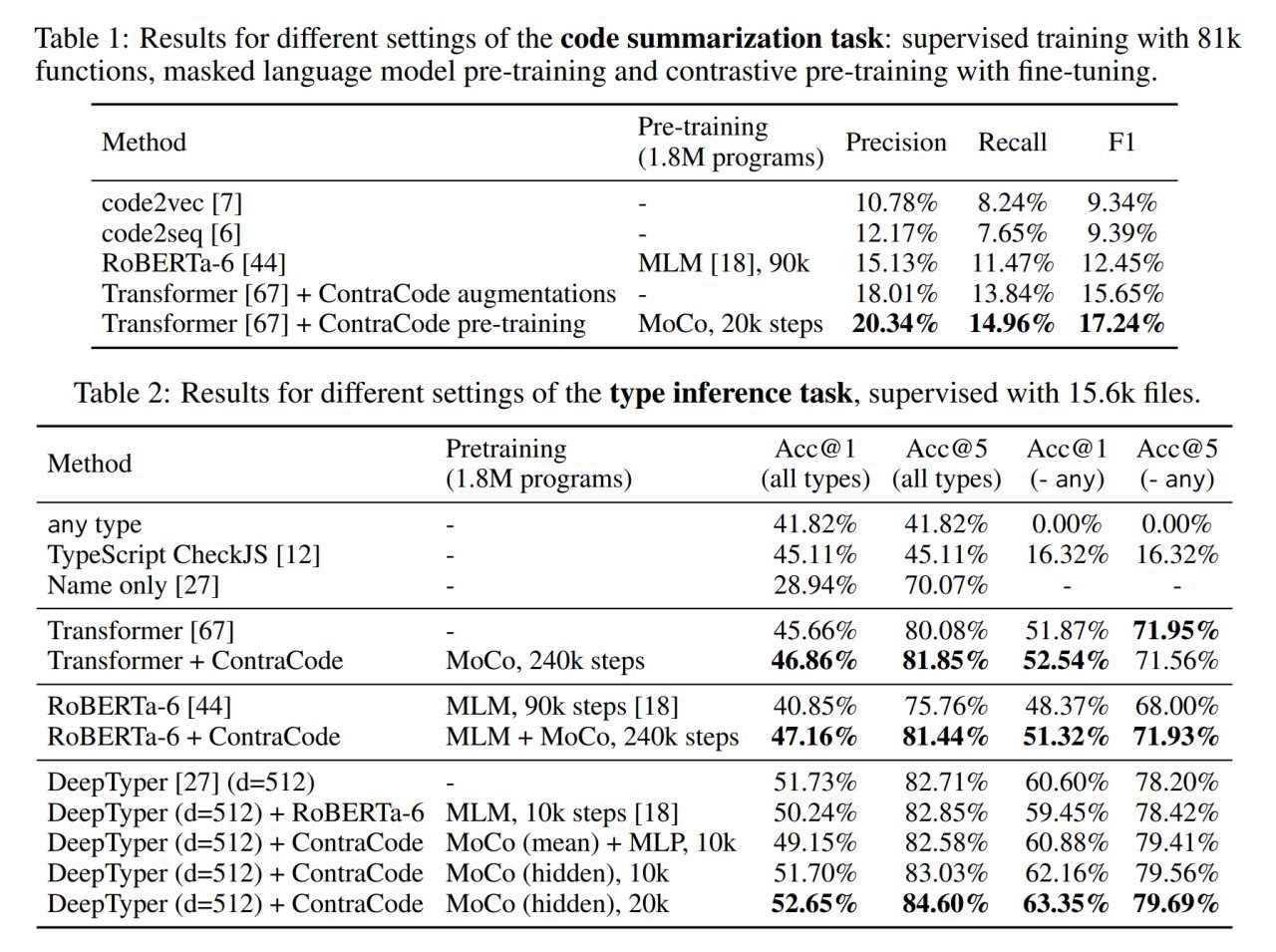
После предобучения делают трансфер на задачу, добавляя специфичную для неё голову декодера (MLP, LSTM, трансформер).
Для предобучения берут датасет CodeSearchNet (
https://github.com/github/CodeSearchNet) и из него только JavaScript. Размеченные программы из него же используют для задачи extreme code summarization (надо предсказать имя метода). Также берут датасет от DeepTyper (
https://github.com/DeepTyper/DeepTyper) и на примерах TypeScript из него обучают вывод типа.