

Levenshtein Transformer
Jiatao Gu, Changhan Wang, Jake Zhao
Facebook AI, 2019
Статья: https://arxiv.org/abs/1905.11006
Код: https://github.com/pytorch/fairseq/tree/master/examples/nonautoregressive_translation
#nlp #nlg #nonautoregressive #transformer
В этой работе делается следующий логичный шаг — что, если дать модели возможность не только вставлять, но и удалять токены?
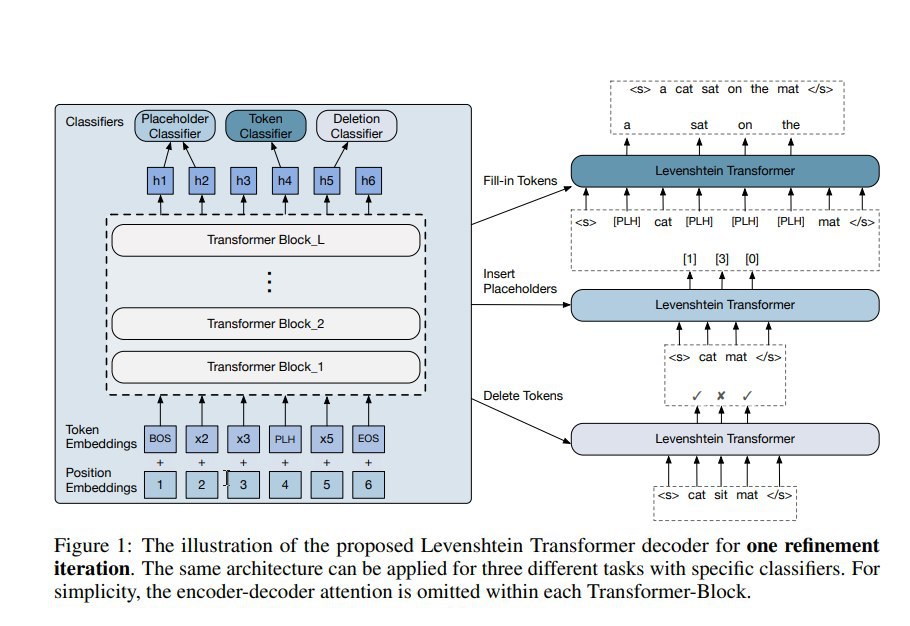
Опять таки, используют подход imitation learning, причём в этом случае действительно используют roll-in policy, как стохастические смеси текущей policy и оракула. Обучаемую policy представляют как композицию трёх независимых: предсказание удаления токенов (по битовой маске), выбор плейсхолдеров среди доступных между уже имеющихся токенов (как в Insertion Transformer) и выбор токенов для заполнения плейсхолдеров (как при MLM). Эти три действия (удаление, генерация плейсхолдеров, заполнение плейсхолдеров) делаются за один шаг, тремя разными головами Transformer-сети. Награда вычисляется как расстояние Левенштейна с обратным знаком до таргета.
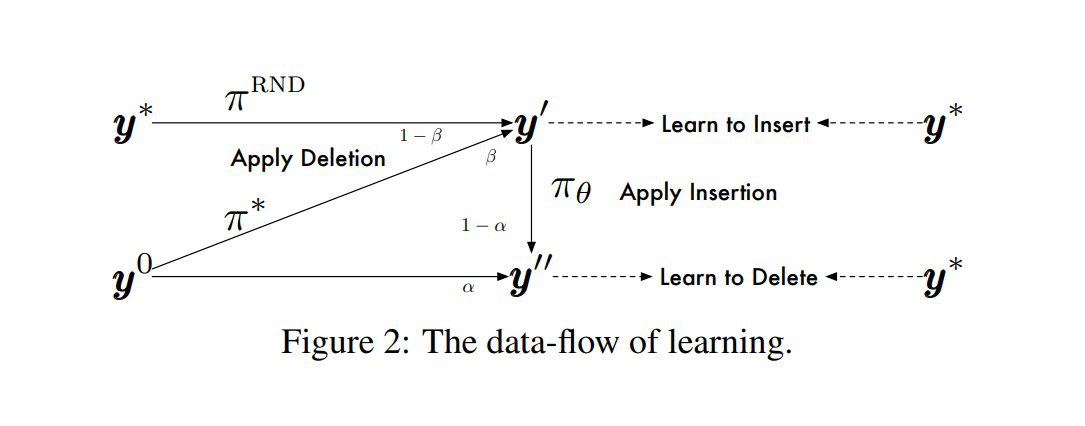
За счёт двойственности операций вставки и удаления предлагается использовать хитрый "dual policy learning" -- т.е. одновременно учат вставлять токены (из roll-in смеси выхода шага удаления и таргета со случайно удалёнными токенами) и удалять токены (из смеси исходной строки и результатов шага вставки). В качестве эксперта/оракула пробуют эвристики над ground truth таргетами или менее шумную авторегрессионную модель — просто LM, обученную на том же датасете, из которой с помощью beam-search сэмплят оптимальный псевдо-ground truth. Таким образом, на каждом шаге насэмпленное из экспертной policy используется, как траектория в окрестностях которой (с точностью до стохастической смеси) мы оптимизируем нашу модель. После пробных запусков обнаружили, что нужен дополнительный костыль в виде штрафа за неиспользованные плейсхолдеры.
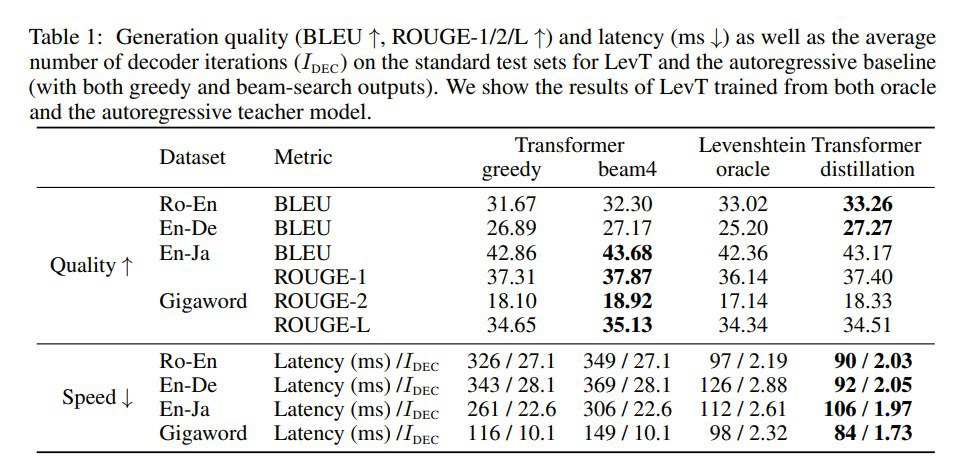
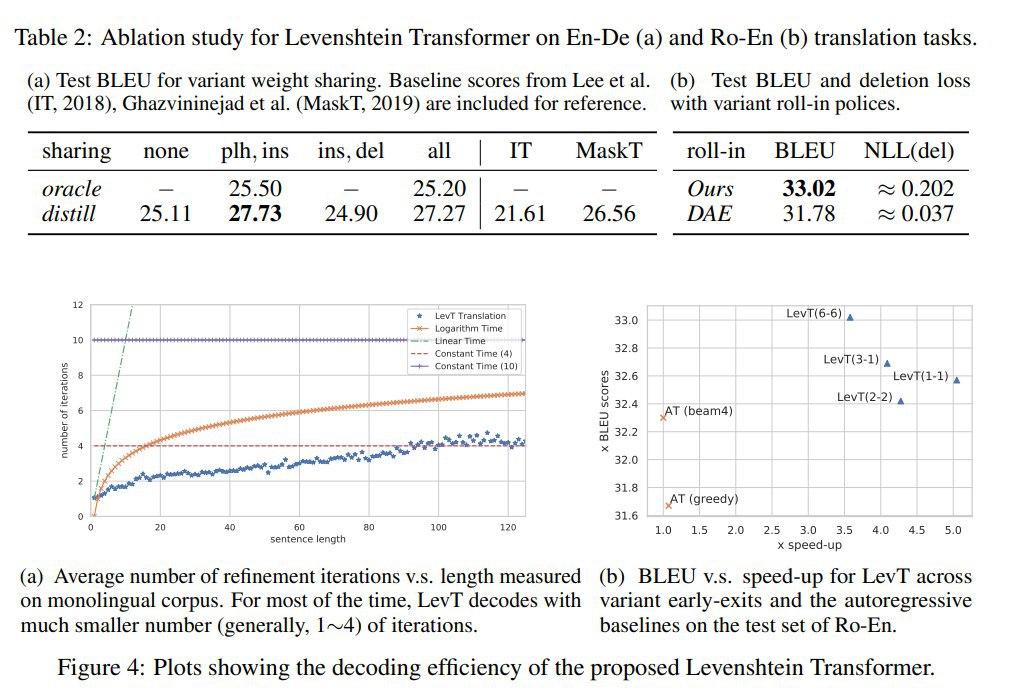
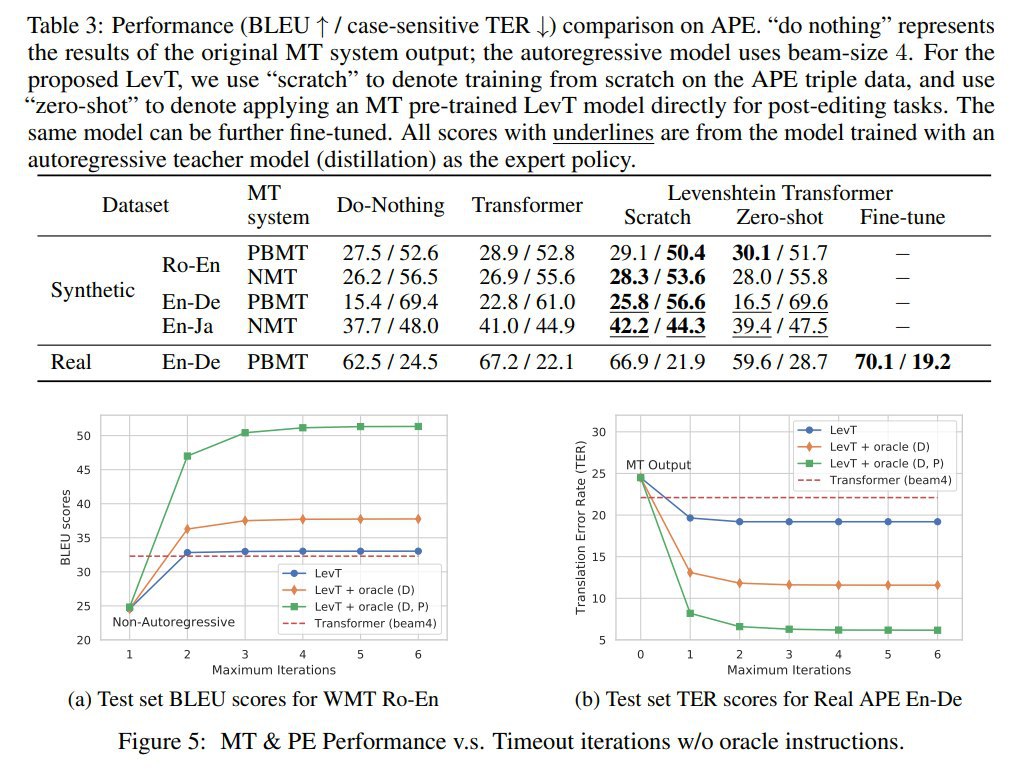
Выяснили, что на фазе inference лучше всего работает жадное сэмплирование. Остановка сэмплирования производится по зацикливанию или по таймауту (по числу итераций). Проверяли на задачах перевода, суммаризации и "automatic post-editing for machine translation". Эксперименты показывают сильное увеличение эффективности почти без потерь в качестве, как на задачах генерации, так и на задачах редактирования текстов.
Здесь же, до кучи, упомяну свежую статью Blank Language Models (arxiv:2002.03079), она довольно похожа на Levenshtein Transformer, но почему-то мало его цитирует и совсем с ним не сравнивается. Желающие могу ознакомиться.