Rethinking the Value of Network Pruning
Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, Trevor Darrell
Статья: https://arxiv.org/abs/1810.05270
Код (unofficial): https://github.com/Eric-mingjie/rethinking-network-pruning
Про переосмысление ценностей и снова про прунинг.
Классический прунинг реализует пайплайн вида “обучение модели” → “прунинг” → “файнтюнинг”
Данная работа ниспровергает некоторые широко распространённые верования относительно этого процесса:
1) Важно начинать с обучения большой over-parameterized сети, из которой мы затем можем удалить часть избыточных параметров, не влияя существенно на точность. И это, считается, лучше, чем обучать маленькую модель с нуля.
2) И веса, и архитектура полученной урезанной модели важны для получения итогового качественного результата. Поэтому выбирается файнтюнинг получившейся модели, а не обучение полученной архитектуры с нуля.
Авторы показывают, что для методов structured pruning (прунинг на уровне каналов свёртки или выше) оба верования не обязательно верны.
То есть,
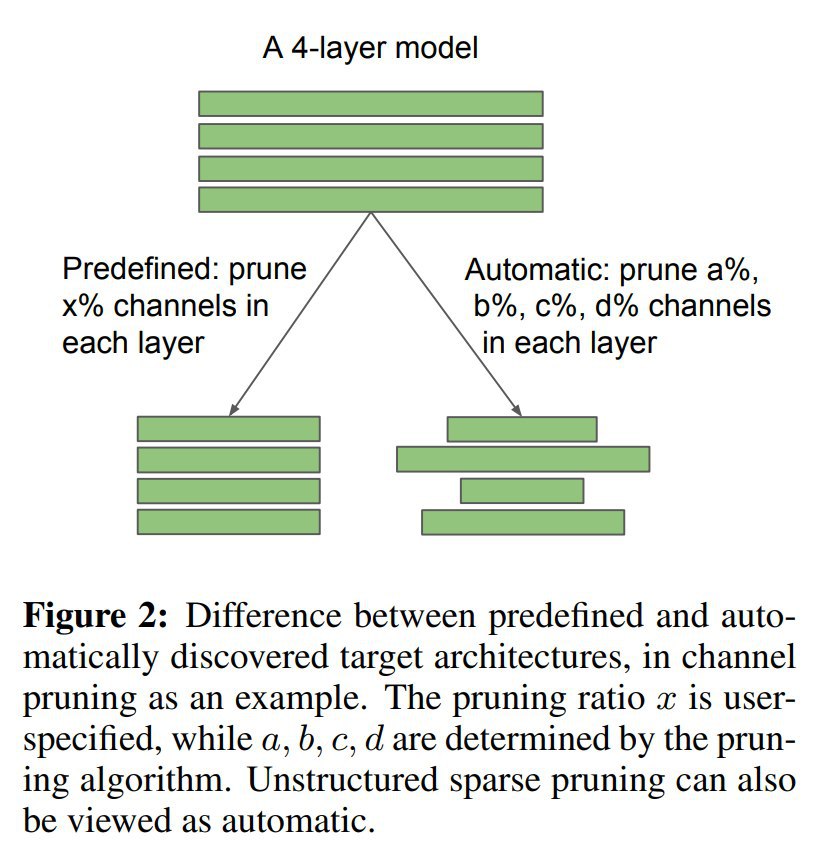
1) Обучение с нуля маленькой целевой модели (где убрано x% каналов в каждом слое) со случайной инициализации способно дать то же или более высокое качество. То есть не обязательно начинать с [долгого] обучения большой модели, можно сразу начать с маленькой.
2) Обучение урезанной после прунинга модели с нуля также даёт аналогичное или более высокое качество по сравнению с файн-тюнингом. То есть полученная архитектура может быть важнее, чем собственно сами веса.
Для методов unstructured pruning (где прунятся индивидуальные веса) также удаётся при обучении с нуля получить сравнимые с прунингом + файн-тюнингом результаты на маленьких датасетах, но не получается на больших типа ImageNet.
Почему раньше все считали иначе? Возможно, просто менее тщательно подбирали гиперпараметры (увы, обычная история в DL, к тому же требующая больших вычислительных ресурсов на эксперименты с переборами), схемы аугментации данных или был нечестный вычислительный бюджет для бейзлайнов.
Пора всё переосмыслить. Возможно, ценность прунинга порой состоит в нахождении правильной целевой архитектуры нежели конкретных “важных” весов. Таким образом прунинг может работать как неявный architecture search.
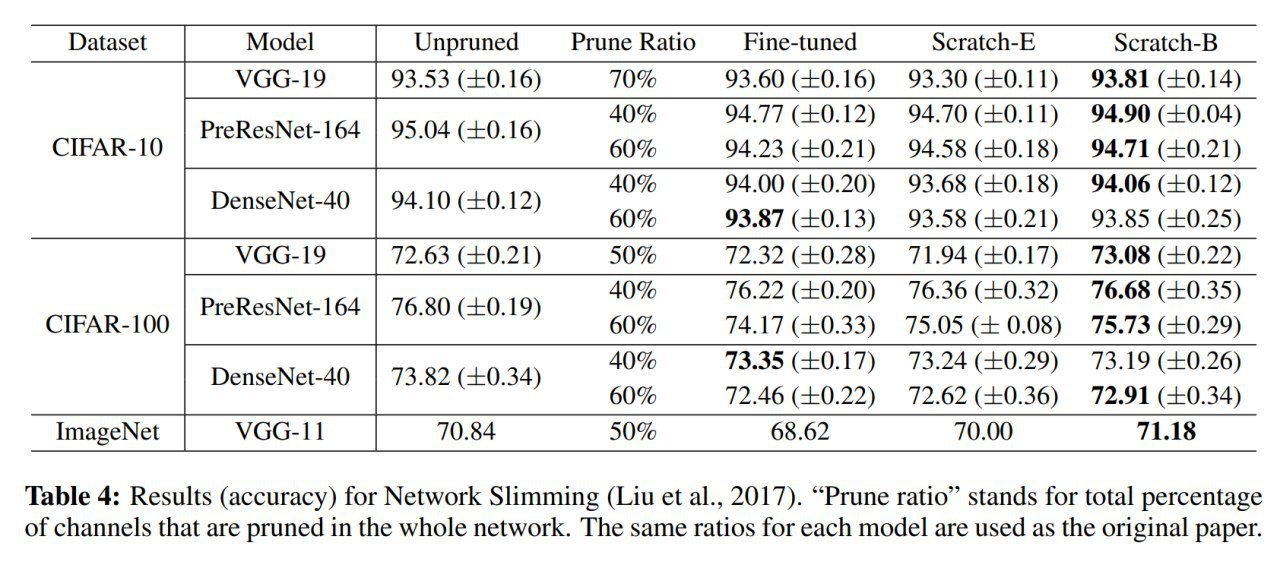
Авторы озаботились тщательным сравнением с разными методами. Среди прочего, важно сравнивать в рамках одинаковых вычислительных бюджетов. Соответственно есть два режима обучения маленьких сетей с нуля -- Scratch-E (то же число эпох) и Scratch-B (тот же вычислительный бюджет в терминах FLOPs).
Дальше сравнивают с кучей методов:
1) Predefined Structured Pruning (pruning ratio предопределён заранее): L1-norm absed filter pruning, ThiNet, Regression based feature reconstruction. Scratch-B почти тотально лучше всего остального.
2) Automatic Structured Pruning (pruning ratio определяется алгоритмом для каждого слоя самостоятельно): Network slimming, Sparse structure selection. Scratch-B снова рулит.
3) Unstructured Magnitude-based Pruning. Scratch-B сравним с файн-тюнингом (но при высоких pruning ratio файнтюнинг порой выигрывает) и проигрывает только на ImageNet.
Один из главных выводов, что для structured pruning полученные после прунинга веса не лучше случайных, и видимо вся польза в полученной архитектуре.
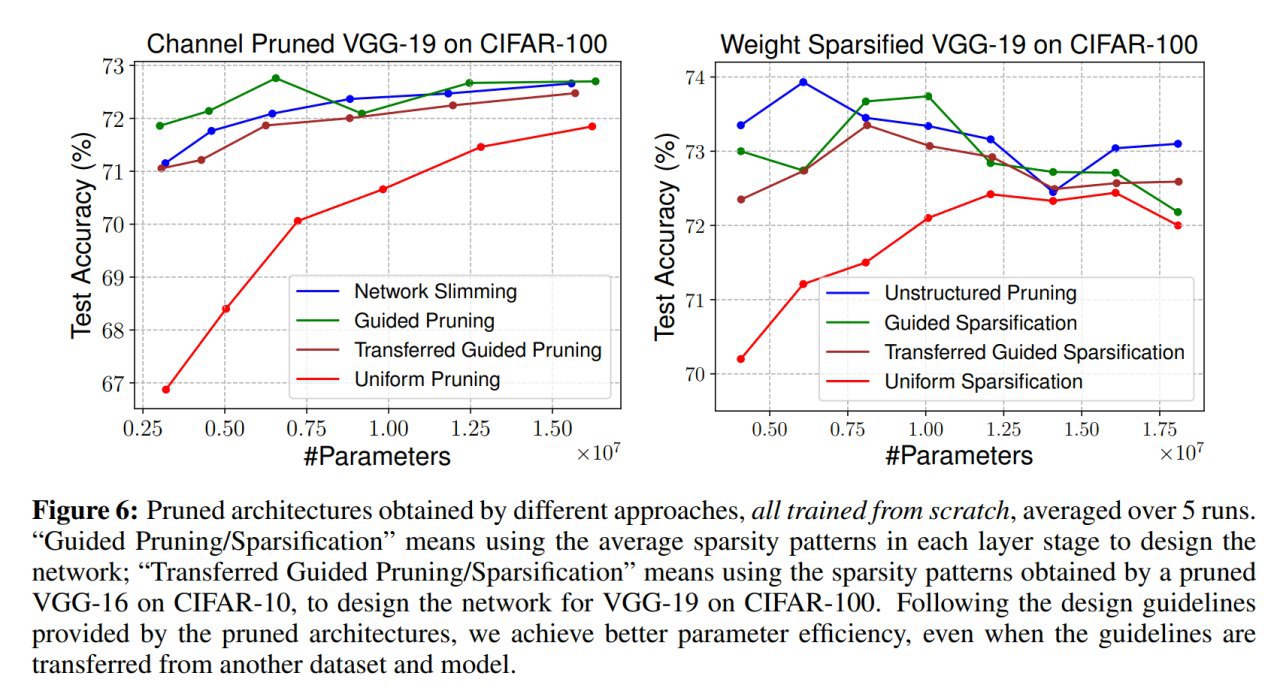
Сравнения с равномерным прунингом показывают существенную разницу, так что архитектура важна. Но есть и кейсы, где особой разницы нет, это больше свойственно архитектурам типа ResNet или DenseNet, видимо в этих сетях избыточность более сбалансирована, чем, скажем, в VGG.
На эксплуатации этого знания (в каких слоях какая часть каналов отпрунена и т.п., паттерны разреженности в фильтрах) можно построить guided pruning. Оно работает.
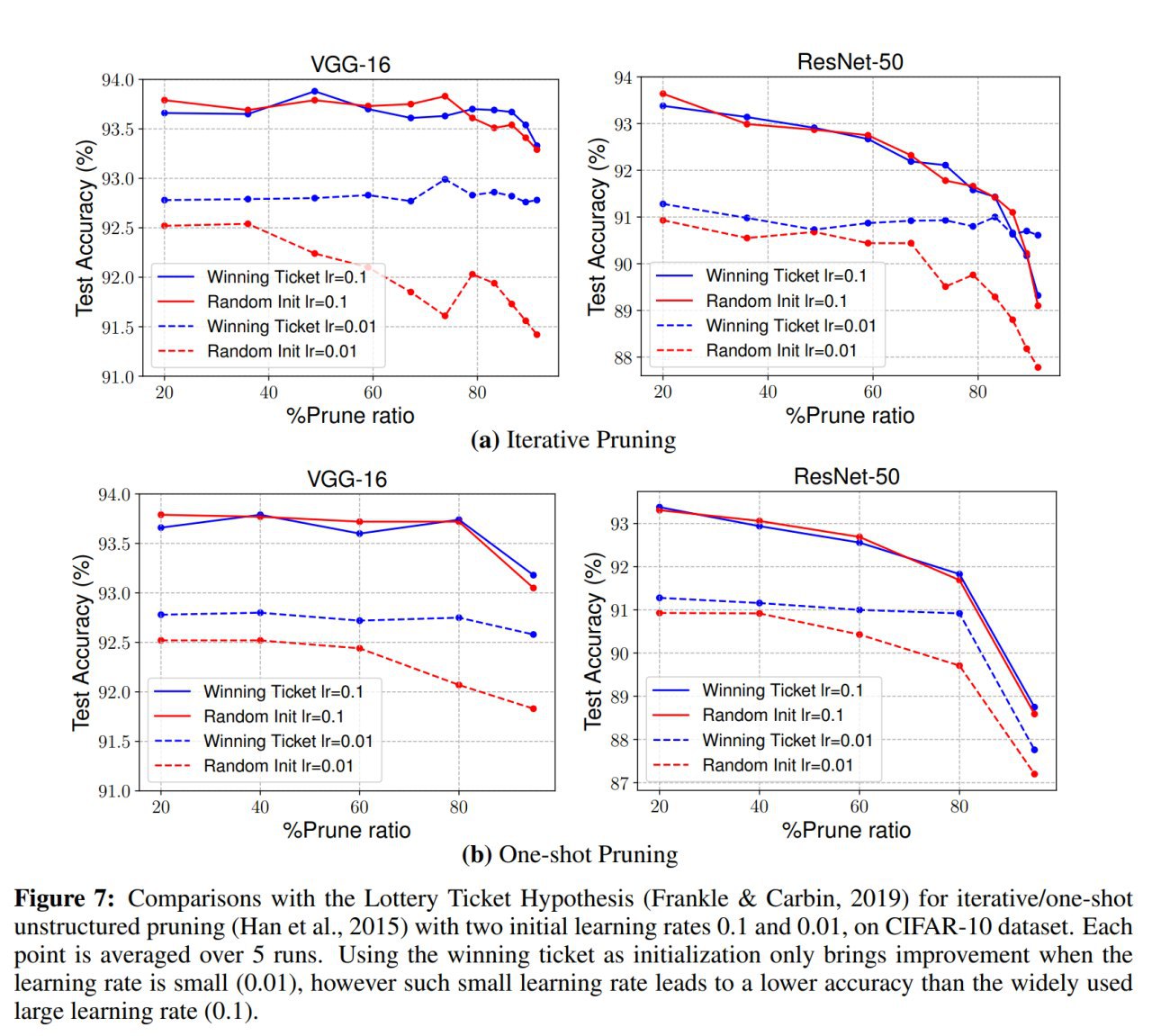
Говоря про прунинг нельзя не коснуться Lottery Ticket Hypothesys (LTH), которая работала в режиме unstructured pruning и где начальная инициализация подсети была важна. Текущая работа показывает, что результирующую сеть можно обучать с новой случайной инициализации и всё ок (но текущая работа в основном про structured pruning, хотя есть и unstructured).
Выглядит как противоречие.