
Insertion Transformer: Flexible Sequence Generation via Insertion Operations
Mitchell Stern, William Chan, Jamie Kiros, Jakob Uszkoreit
Google Brain, 2019
Статья: https://arxiv.org/abs/1902.03249
#nlp #nlg #nonautoregressive #transformer #icml #2019
Итак, раз уж мы научились сэмплировать токены в произвольном порядке, зачем делать это по одному за раз, нельзя ли в этом месте оптимизировать процесс? Авторы предлагают архитектуру Insertion Transformer, которая довольно-таки похожа на INTRUS из предыдущей статьи, но позволяет сэмплировать по нескольку токенов за шаг.
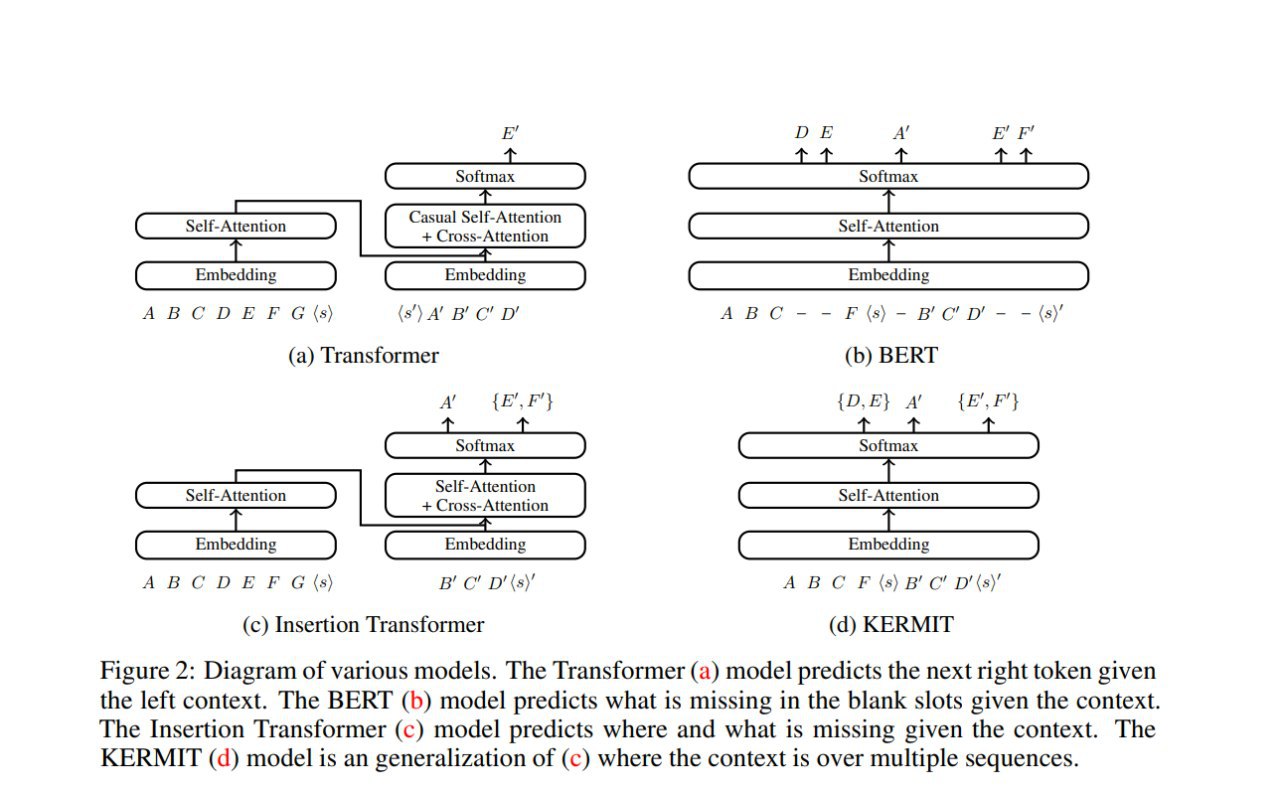
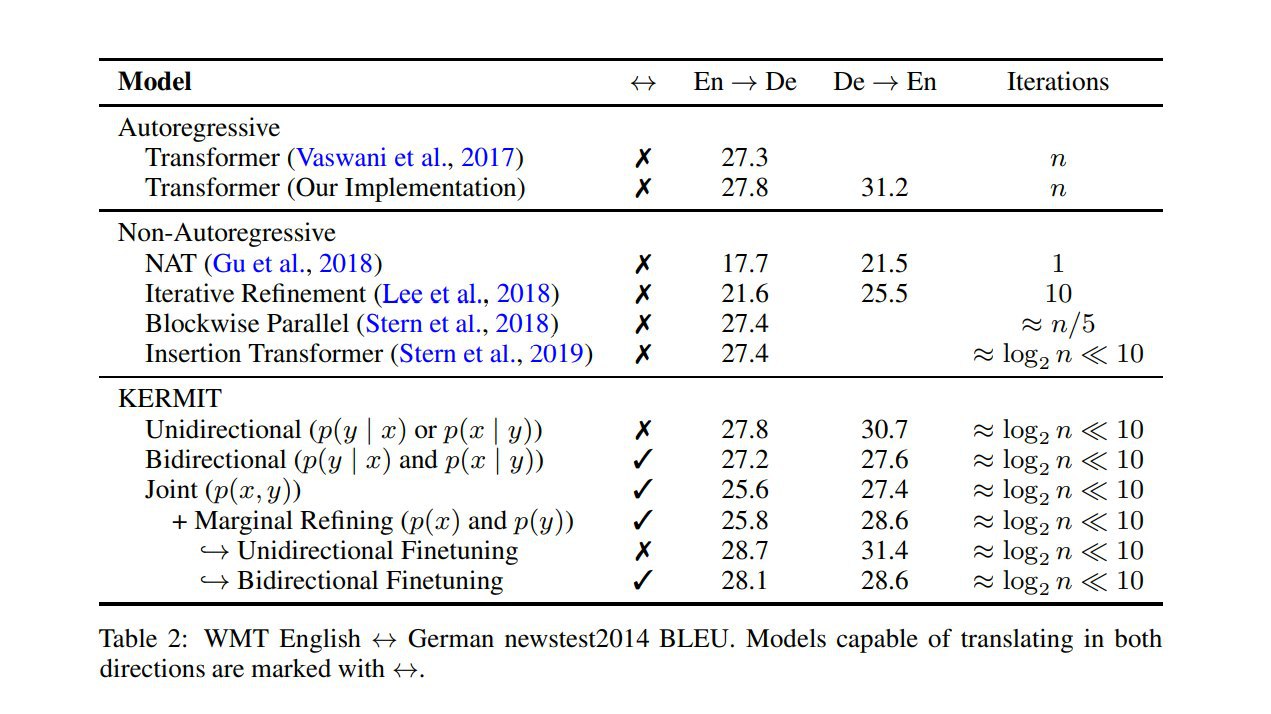
Начинаем всегда с пустой строки = единственного слота. На каждом шаге модель выдаёт на выходе совместное распределение по доступным слотам (= число уже имеющихся токенов + 1) и словарю токенов. И тут допускается одновременная вставка нескольких токенов -- максимально по числу имеющихся слотов.
Модификации по сравнению с обычным трансформером:
- Как и ранее, в декодере снимается стандартная для декодеров трансформеров casual self-attn mask, запрещающая видеть токены правее текущего.
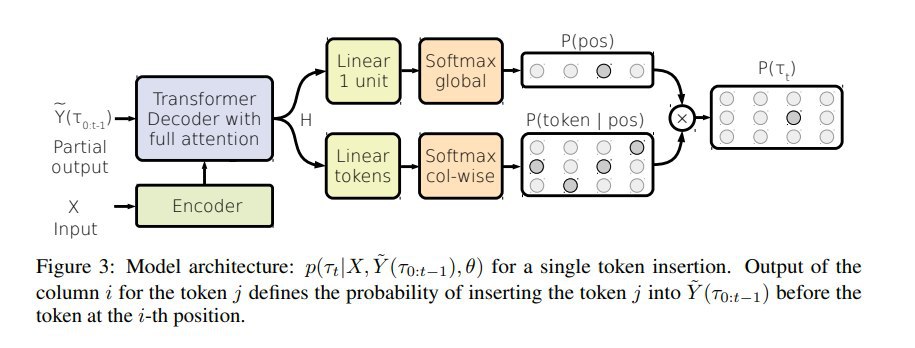
- Пусть вход у нас из n токенов — добавляем на вход два дополнительных токена в начало и в конец, это даёт нам на выходе n+2 позиционных вектора, дальше конкатенацией каждой пары соседних выходных векторов мы получаем n+1 векторов, каждый из которых соответствует одному из возможных слотов
- Дальше из матрицы этих векторов H, соответствующих слотам, вычисляются вероятности совместного распределения (слот, токен). Тут в базовом варианте делается просто проекция+софтмакс в вероятности совместного распределения (слот, токен).
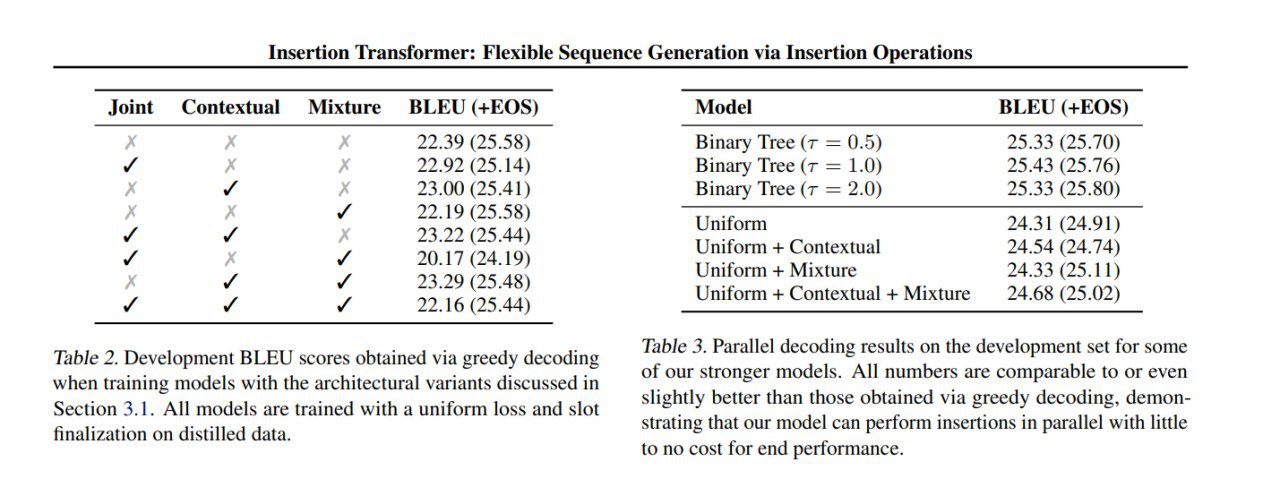
- Дополнительно рассматривают три модификации расчёта вероятностей слотов и токенов: Joint (через условную вероятность, как в INTRUS), Context (с добавлением общего для всех слотов bias, построенного max-polling-ом из H) и Mixture (Mixture-of-Softmaxes Output Layer из [arxiv:1711.03953]).
Далее эту архитектуру тренировали на нескольких фиксированных последовательностях вставок (не оптимизируя lower bound как в INTRUS, а явно задавая стратегию сэмплинга). Использовалось 4 стратегии:
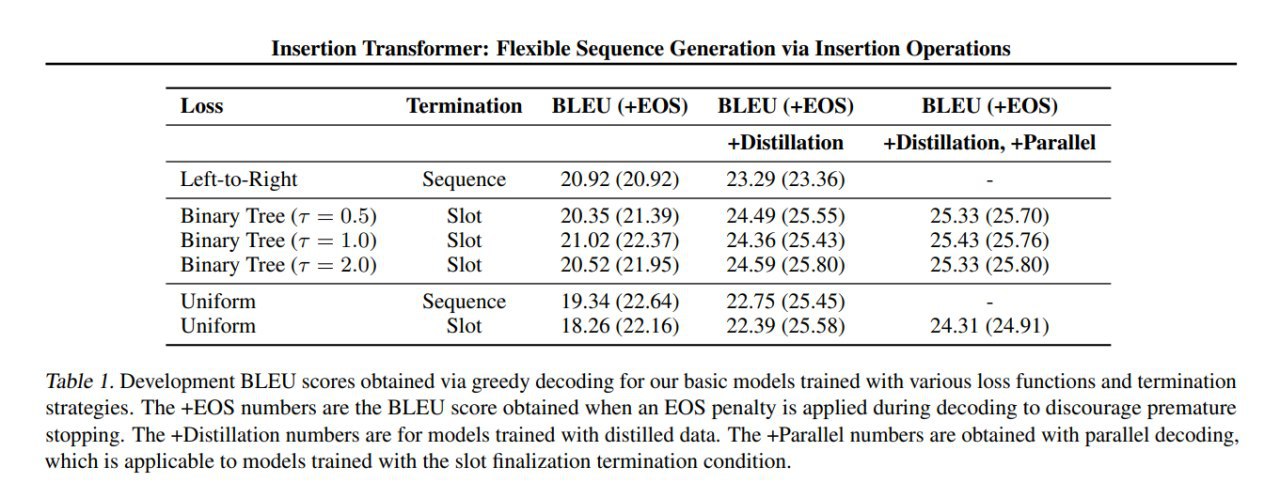
- left-to-right: слева направо, имитация стандартной авторегрессионной модели, на каждом шаге таргет на угадывание крайнего правого из доступных слотов и правильного следующего токена в нём, остановка по <EOS>.
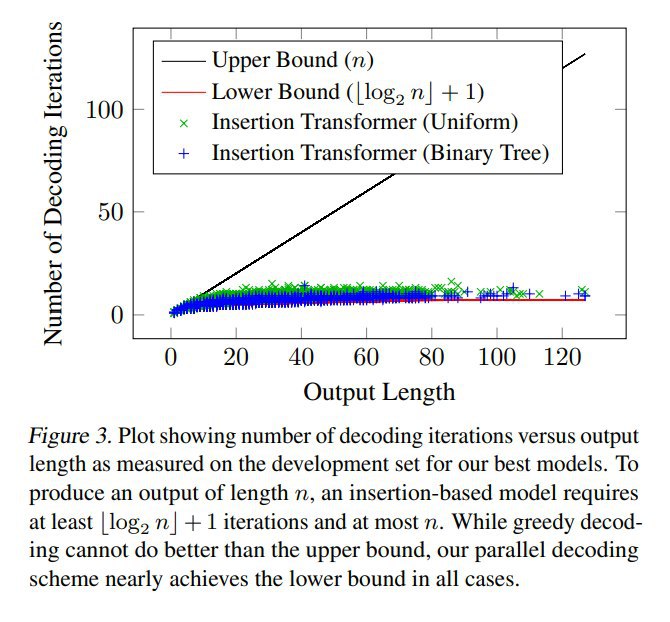
- binary-tree: сбалансированное бинарное дерево -- сначала предсказываем средний токен, потом средние в левой и правой половине, на k-ом шаге дописываем сразу 2^k токенов, т.е. в идеале число шагов ~ логарифм от длины строки. Чтобы учить такое, мы сначала на каждом шаге обучения выбираем случайную подпоследовательность токенов полного таргета (тут есть тонкости в том, чтобы сделать подпоследовательности разной длины равновероятными), а затем считаем таргет следующего шага для каждого слота как каждый отсутствующий там токен с вероятностью, взвешенной на его расстояние до центра бреши (с температурой, которая — гиперпараметр).
- uniform: равномерно случайная генерация -- с одинаковой вероятностью каждого возможного верного шага, технически это вариант binary-tree с бесконечной температурой.
Как устроено сэмплирование:
- Жадное -- выбираем 1 пару (слот, токен) с максимальной вероятностью, её вставляем, итерируем.
- Параллельное -- для каждого слота считаем вероятности токенов, если там топ1 по вероятности это end-of-slot, ничего не сэмплируем; в остальные слоты вставляем их топ1 по вероятности; итерируем (пока все не предскажут end-of-slot) + есть возможность распараллелить вычисления этих распределений для токенов в разных слотах.
- Чтобы уметь как-то останавливаться в стратегиях binary-tree и uniform, добавляем служебный токен end-of-slot, который говорит, что ничего в этот слот сейчас сэмплить не надо. Таким образом, признаков для остановки два: когда строка дописана и пришёл <EOS>, или когда все имеющиеся слоты голосуют за end-of-slot.