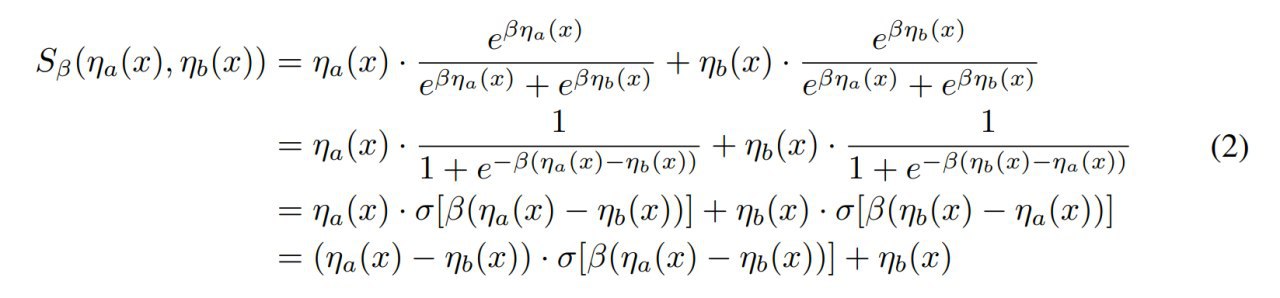Activate or Not: Learning Customized Activation
Ningning Ma, Xiangyu Zhang, Jian Sun
Статья:
https://arxiv.org/abs/2009.04759 Давно мы не писали про какие-нибудь хитрые функции активации, а вернее, кажется, вообще не писали ни разу. А тут и повод есть.
В 2017 году команда из Google Brain с помощью хитрого автоматического поиска, построенного на RNN-ках, нашла функцию активации Swish [f(x) = x · sigmoid(βx)], которая оказалась заметно лучше ReLU (
https://arxiv.org/abs/1710.05941).
Поскольку никакой человек эту функцию не дизайнил, спросить RNN-ку, что она имела в виду, не получается. Работает и работает, а GPT-3 для объяснения результатов нейро-поиска ещё никто не прикручивал вроде.
Функция стала популярна, её часто можно встретить у тех, кто старается выжать последние проценты качества из имеющихся моделей. Затем подоспело ещё какое-то число свежих функций, например, Mish, которая вроде как ещё лучше (
https://krutikabapat.github.io/Swish-Vs-Mish-Latest-Activation-Functions/).
И вот на днях появилось логическое продолжение под названием ACON.
В чём дело? Разберёмся!
Подход в общем классический. Давайте поймём как имеющиеся функции можно обобщить, а потом из этого обобщения предложим что-нибудь интересное. Заодно и интуицию обретём.
Логические шаги тут следующие:
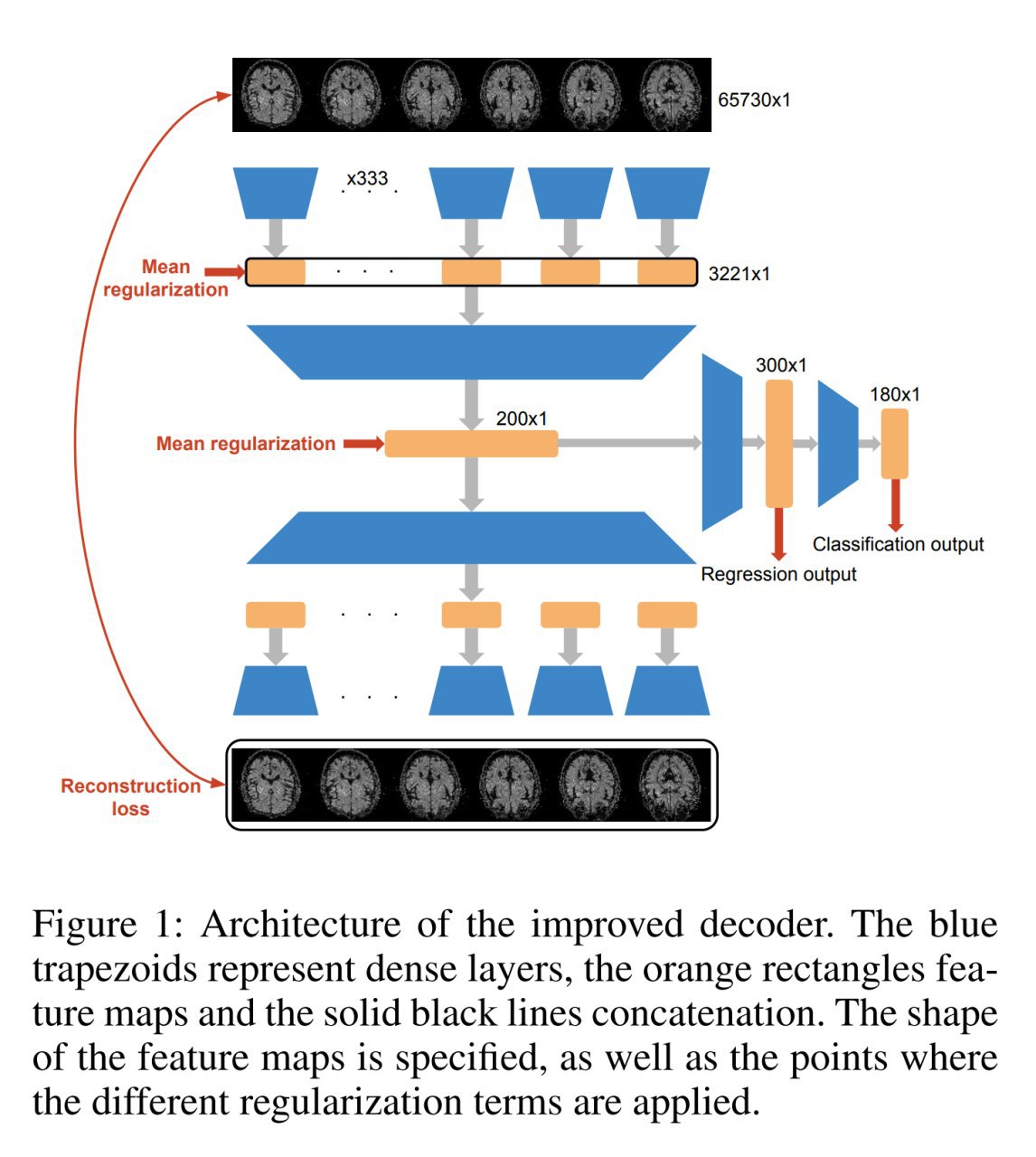
1. Функцию max можно аппроксимировать гладким и дифференцируемым вариантом, который мы будем называть smooth maximum с параметром β, который когда стремится к бесконечности, даёт в пределе максимум, а когда стремится к нулю — арифметическое среднее.
S_β(x_1, ..., x_n) = sum(x_i*exp(β*x_i))/sum(exp(β*x_i))
2. ReLU это, как известно, max(x,0), а значит можно аппроксимировать этим нашим гладким максимумом о двух входах:
S_β(η_a(x), η_b(x))
и η_a(x) = x, η_b(x) = 0,
3. Swish тоже можно представить через эту функцию S_β(x, 0) = x * σ(β*x) и её мы называем ACON-A. А заодно Swish — это гладкая аппроксимация ReLU.
4. Если рассмотреть развития ReLU типа PReLU, Leaky ReLU и т.п., то можно прийти к функции ACON-B c n η_a(x) = x, η_b(x) = px.
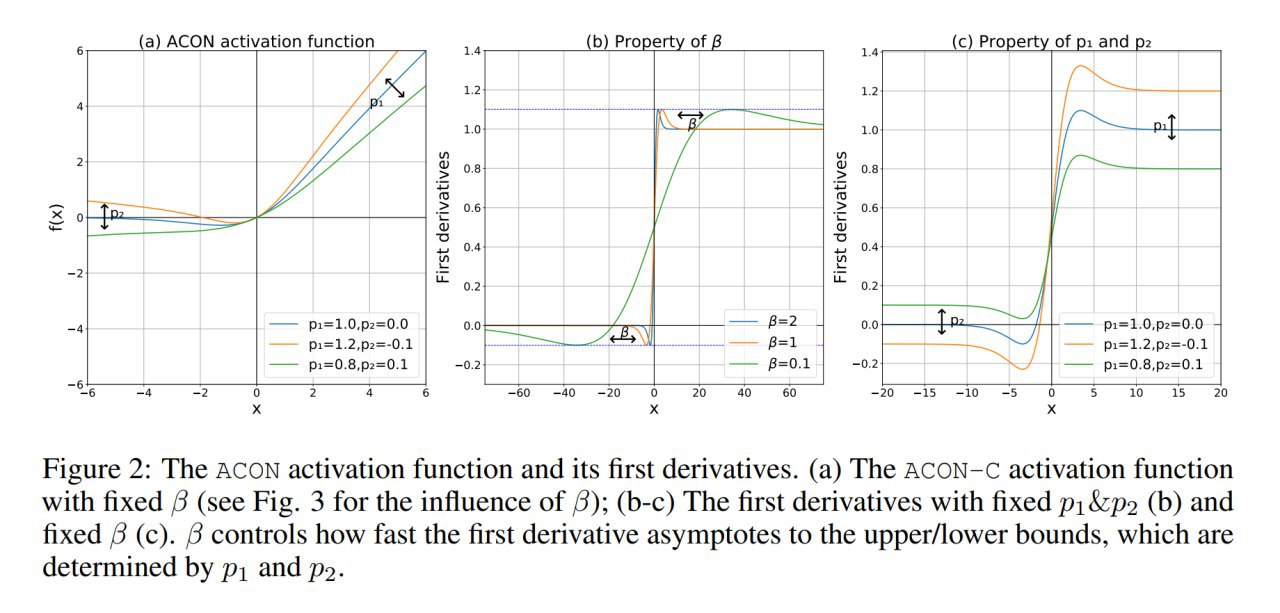
5. Можно пойти ещё дальше и сделать ACON-C с η_a(x) = p_1*x, η_b(x) = p_2*x(p_1 != p_2). ACON-C в такой формулировке позволяет иметь обучаемые верхние и нижние границы для градиента (у Swish они фиксированы). Они определяются параметрами p_1 и p_2.
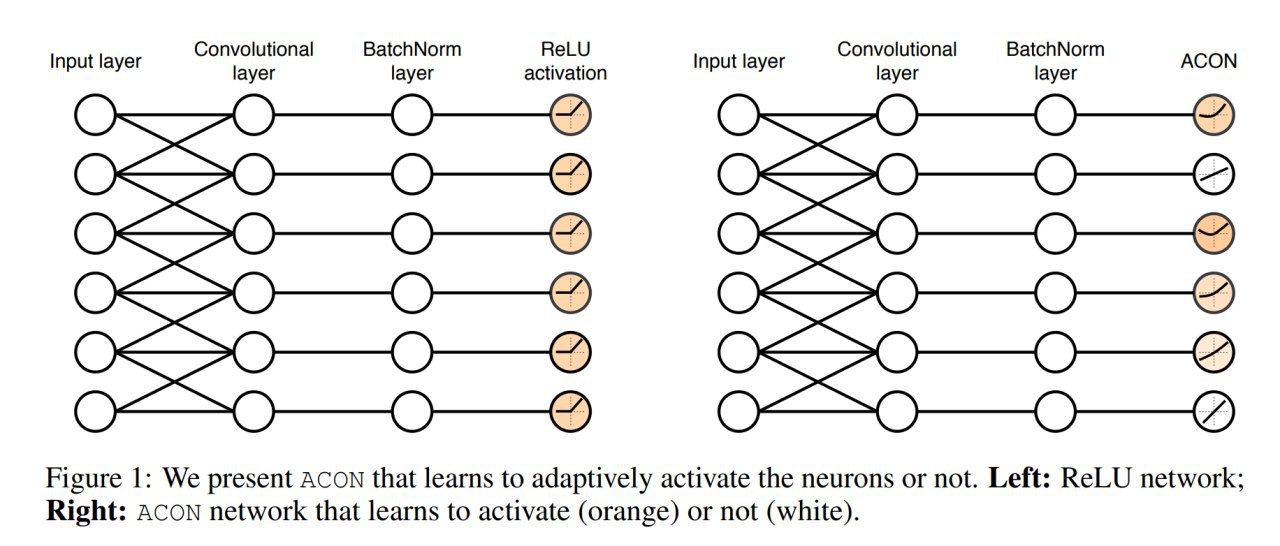
6. Ну и наконец параметр β тоже можно обучать и это даёт функцию Meta-ACON. Этот параметр называется switching factor и регулирует поведение нейрона: линейный (неактивный нейрон) или нелинейный режим работы (активный нейрон). Отсюда и название ActivateOrNot (ACON).
И вот эта последняя история открывает целое пространство для исследования, можно реализовывать разные функции, генерящие эту β по входным данным: можно иметь общий параметр на весь слой, можно на отдельные каналы, а можно и на пиксели.
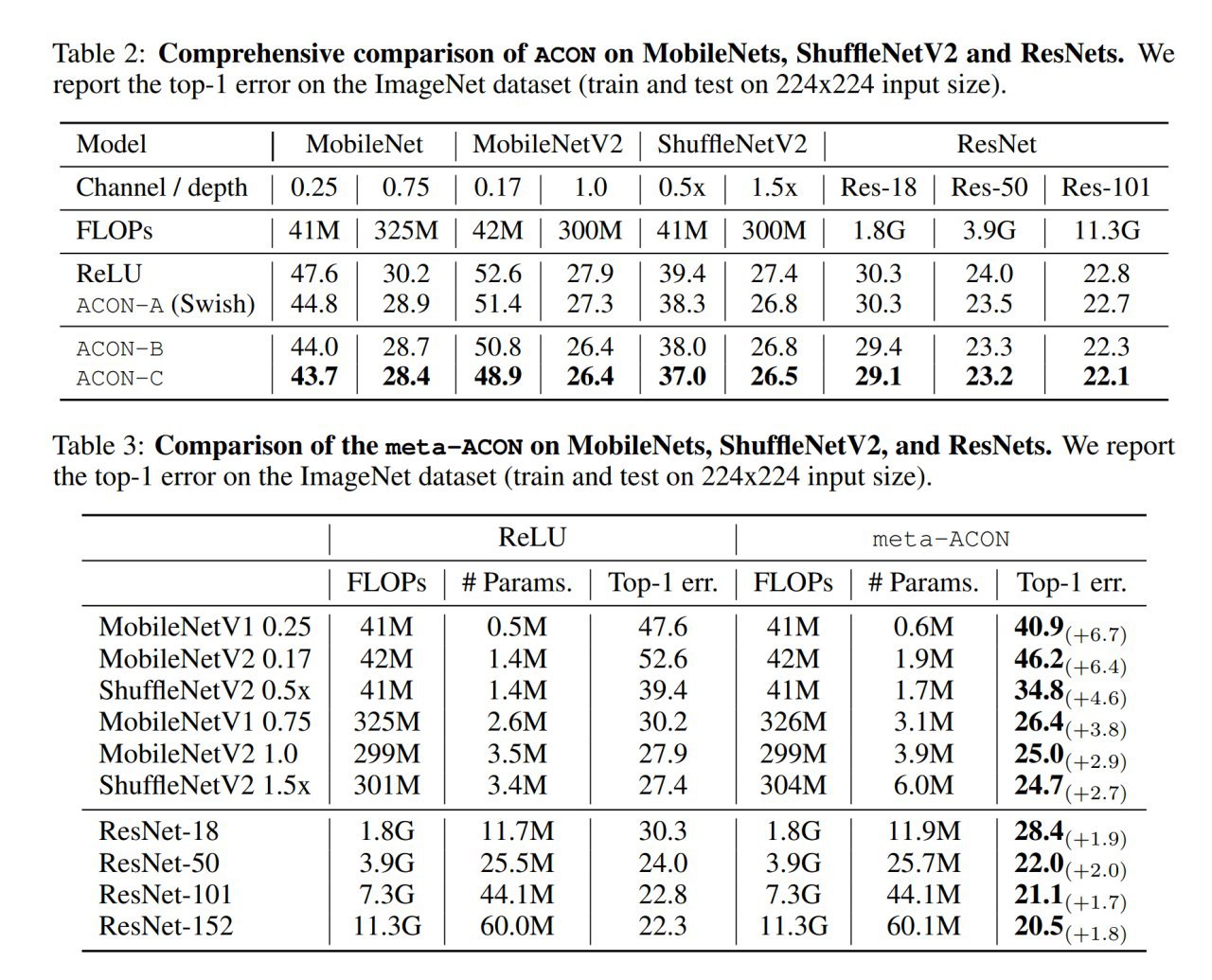
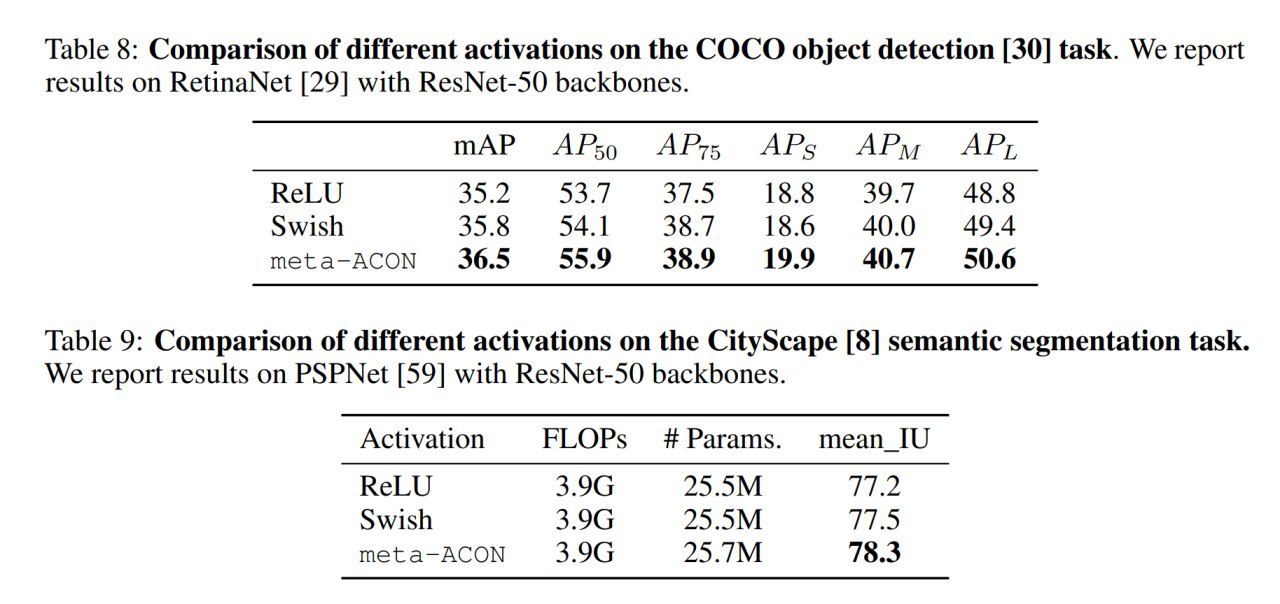
Что вообще даёт вся эта эквилибристика? На редкость неплохие улучшения, единицы процентных пунктов в терминах top-1 ошибки. Для которых от вас по большому счёту ничего не требуется кроме замены функции активации.
Ну и заодно вроде понятнее стало, что такое Swish и вообще.