Size: a a a
2020 March 08

А если прунить входной слой, получается что-то вроде feature selection'а
2020 March 09
Picking Winning Tickets Before Training by Preserving Gradient Flow
Chaoqi Wang, Guodong Zhang, Roger Grosse
Статья: https://arxiv.org/abs/2002.07376
Код: https://github.com/alecwangcq/GraSP
Вот ещё работа про прунинг. На этот раз не прунинг готовых сеток, и не прунинг во время обучения, а прунинг при инициализации!
Как видно, есть разные способы прунинга:
1) Наиболее известный и частый прунинг готовых обученных сетей (со всеми его недостатками, см.предыдущий пост)
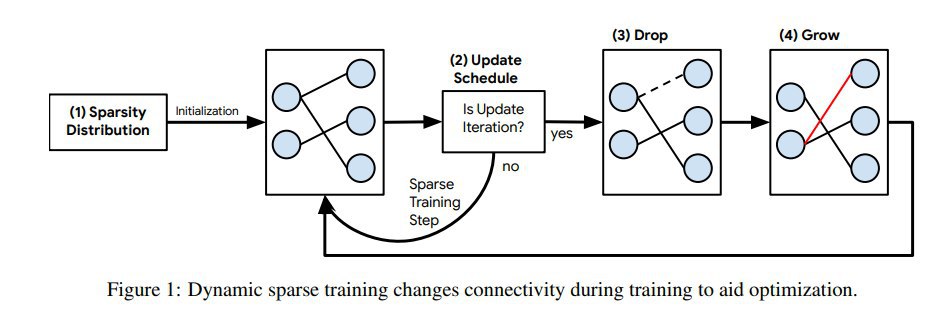
2) Прунинг во время обучения, включая dynamic sparse training (см.предыдущий пост, RigL как раз отсюда)
3) Прунинг перед обучением (это уже что-то интересненькое!). Дальше рассматриваем этот кейс.
Lottery ticket hypothesis была бы из этой серии, если бы можно было при инициализации сразу находить эти выигрышные билеты.
В предыдущем посте упоминался метод SNIP (Single-shot Network Pruning, https://arxiv.org/abs/1810.02340), который в этой работе относят к классу foresight pruning.
Идея SNIP проста: у нас есть какая-то инициализированная (рандомом) сетка, давайте оставим в ней самые многообещающие соединения. Самые многообещающие определяются по т.н. connection sensitivity, насколько убирание конкретного веса влияет на лосс — убираются наименее влияющие. То есть SNIP стремится сохранить лосс оригинальной (инициализированной рандомом) сетки.
Авторы текущей работы утверждают, что в начале обучения важнее сохранить общую динамику обучения, чем лосс сам по себе. SNIP явным образом ничего такого не делает и может нарушить поток информации по сети. Например, при высоких pruning ratios (скажем, 99%) он стремится убрать почти все веса определённых слоёв, создавая боттлнек в сети.
Авторы считают, что важнее сохранять поток градиентов в сети и строят свой алгоритм на этом. GraSP (Gradient Signal Preservation) стремится убирать веса, которые не уменьшают поток градиентов в сети (клёво, если это ещё и увеличивают).
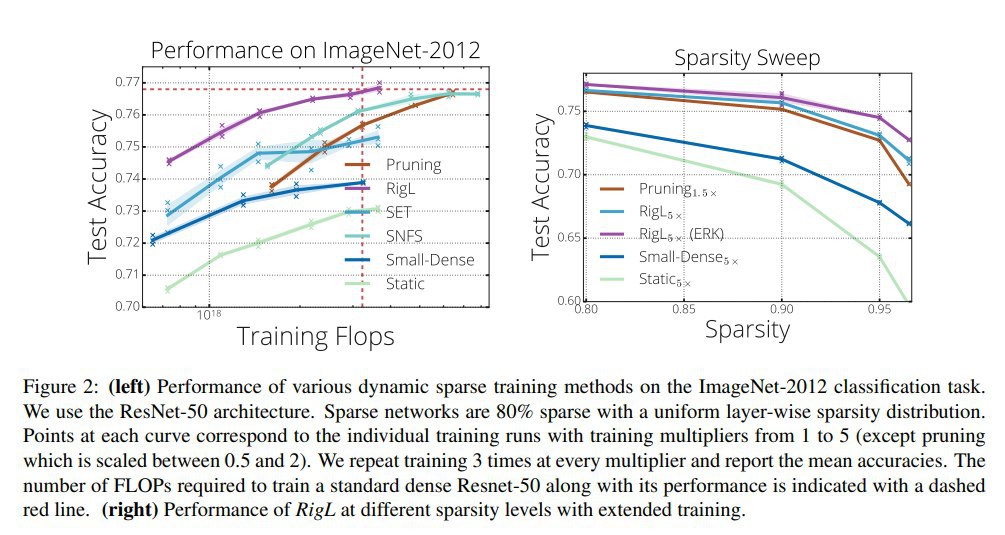
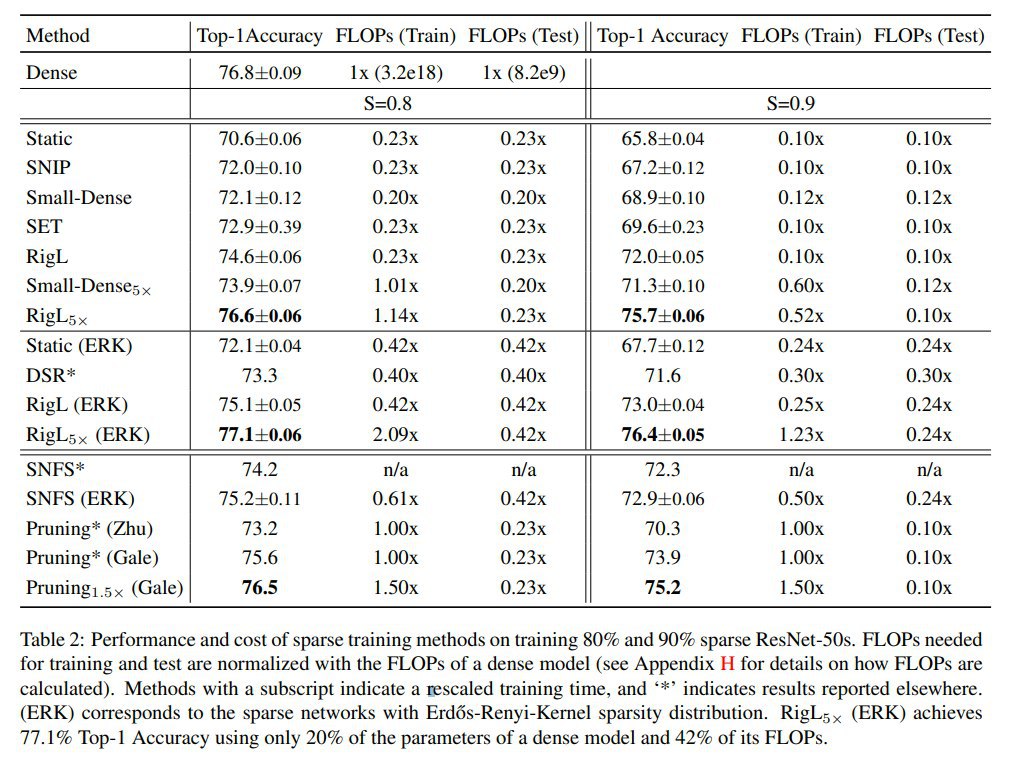
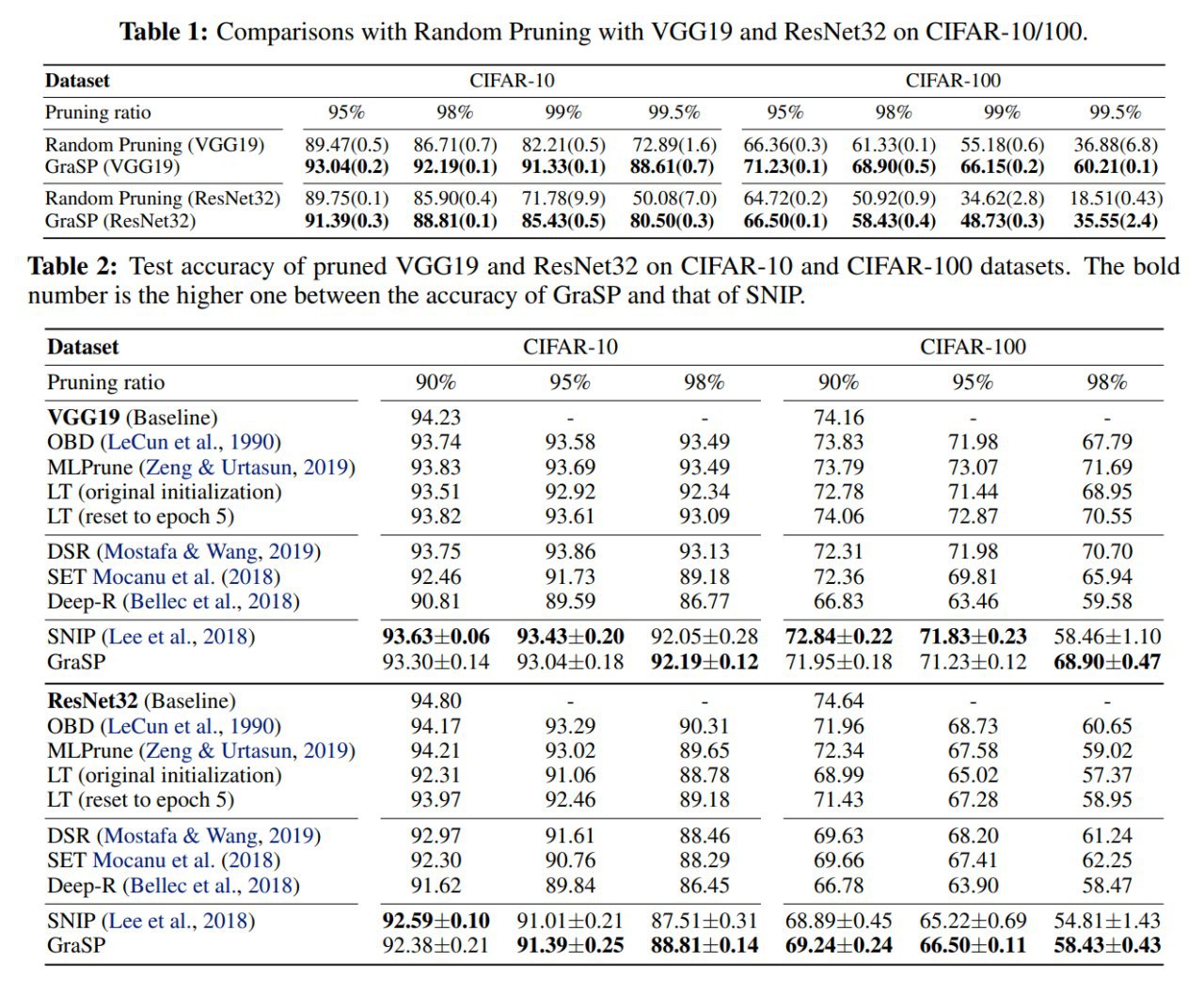
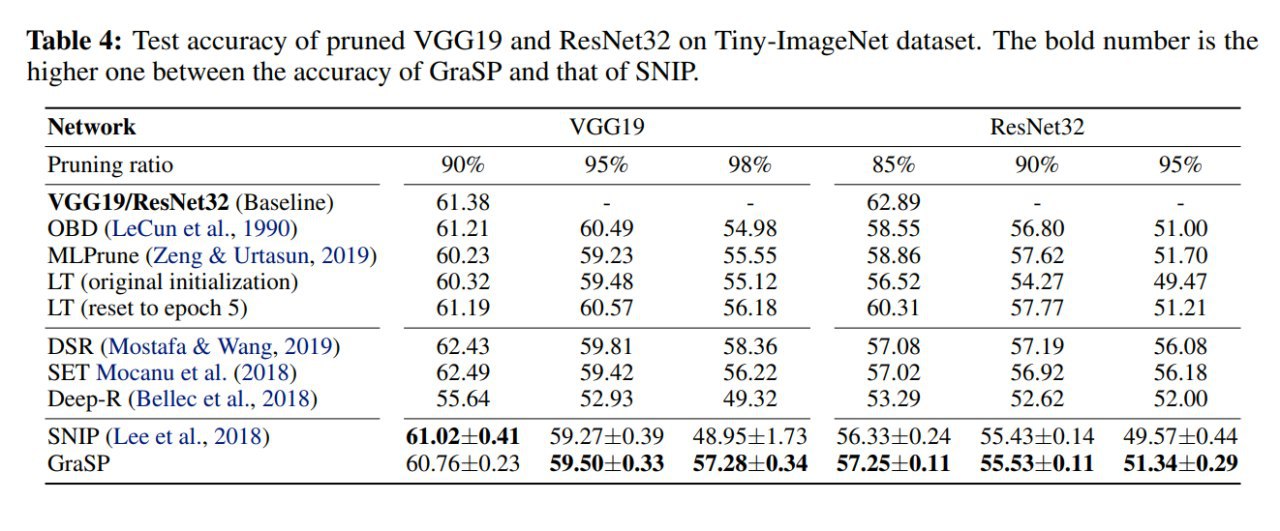
Метод в целом работает. Точно лучше случайного прунинга. На низких pruning rate (85-90%) и SNIP и GraSP дают близкие к бейзлайнам (работающим на уже тренированных сетях) результаты, но не превосходят их (что в общем неудивительно). При более серьёзном прунинге и более сложных сетях GraSP обгоняет SNIP и чем дальше, тем больше.
Из интересного, оба метода сравнимы или немного превосходят Lottery ticket с оригинальной инициализацией. Но после оригинальной работы с LT была вторая про обучение больших сетей (https://arxiv.org/abs/1903.01611), и там брали инициализацию не от самого начала, от небольшого числа итераций после, она была лучше.
До DSR (динамический прунинг, сравнение с ним было в предыдущем посте) недотягивают, он лидер. По идее RigL из предыдущей статьи был бы ещё лучше.
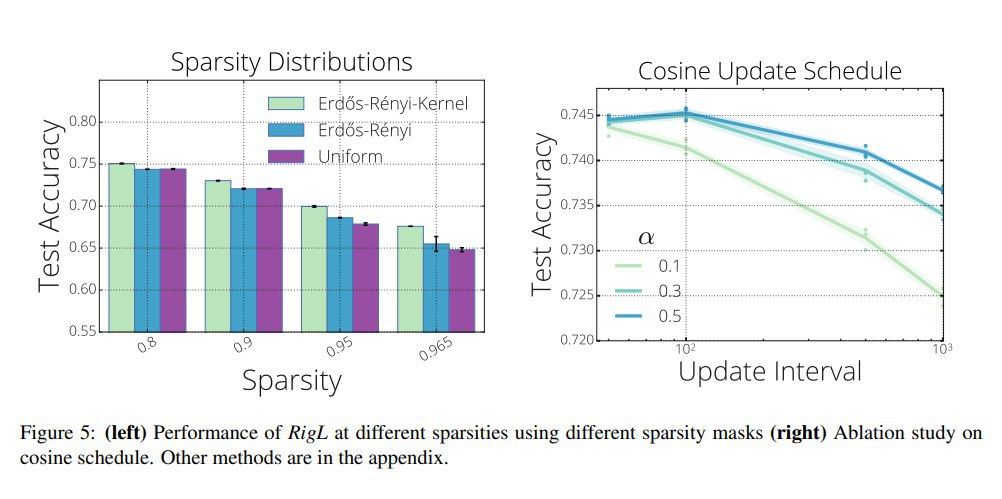
Визуализации показывают преференции по прунингу разных частей сети. Оба метода любят прунить много весов в верхних слоях, но GraSP всё же оставляет их больше.
В целом сейчас не выглядит суперпрорывом, но направление интересное. Если научатся делать хороший foresight pruning, то удастся сэкономить много ресурсов на обучении. Возможно, когда-нибудь получится что-то сравнимое по качеству с традиционным прунингом уже обученных сетей.
Chaoqi Wang, Guodong Zhang, Roger Grosse
Статья: https://arxiv.org/abs/2002.07376
Код: https://github.com/alecwangcq/GraSP
Вот ещё работа про прунинг. На этот раз не прунинг готовых сеток, и не прунинг во время обучения, а прунинг при инициализации!
Как видно, есть разные способы прунинга:
1) Наиболее известный и частый прунинг готовых обученных сетей (со всеми его недостатками, см.предыдущий пост)
2) Прунинг во время обучения, включая dynamic sparse training (см.предыдущий пост, RigL как раз отсюда)
3) Прунинг перед обучением (это уже что-то интересненькое!). Дальше рассматриваем этот кейс.
Lottery ticket hypothesis была бы из этой серии, если бы можно было при инициализации сразу находить эти выигрышные билеты.
В предыдущем посте упоминался метод SNIP (Single-shot Network Pruning, https://arxiv.org/abs/1810.02340), который в этой работе относят к классу foresight pruning.
Идея SNIP проста: у нас есть какая-то инициализированная (рандомом) сетка, давайте оставим в ней самые многообещающие соединения. Самые многообещающие определяются по т.н. connection sensitivity, насколько убирание конкретного веса влияет на лосс — убираются наименее влияющие. То есть SNIP стремится сохранить лосс оригинальной (инициализированной рандомом) сетки.
Авторы текущей работы утверждают, что в начале обучения важнее сохранить общую динамику обучения, чем лосс сам по себе. SNIP явным образом ничего такого не делает и может нарушить поток информации по сети. Например, при высоких pruning ratios (скажем, 99%) он стремится убрать почти все веса определённых слоёв, создавая боттлнек в сети.
Авторы считают, что важнее сохранять поток градиентов в сети и строят свой алгоритм на этом. GraSP (Gradient Signal Preservation) стремится убирать веса, которые не уменьшают поток градиентов в сети (клёво, если это ещё и увеличивают).
Метод в целом работает. Точно лучше случайного прунинга. На низких pruning rate (85-90%) и SNIP и GraSP дают близкие к бейзлайнам (работающим на уже тренированных сетях) результаты, но не превосходят их (что в общем неудивительно). При более серьёзном прунинге и более сложных сетях GraSP обгоняет SNIP и чем дальше, тем больше.
Из интересного, оба метода сравнимы или немного превосходят Lottery ticket с оригинальной инициализацией. Но после оригинальной работы с LT была вторая про обучение больших сетей (https://arxiv.org/abs/1903.01611), и там брали инициализацию не от самого начала, от небольшого числа итераций после, она была лучше.
До DSR (динамический прунинг, сравнение с ним было в предыдущем посте) недотягивают, он лидер. По идее RigL из предыдущей статьи был бы ещё лучше.
Визуализации показывают преференции по прунингу разных частей сети. Оба метода любят прунить много весов в верхних слоях, но GraSP всё же оставляет их больше.
В целом сейчас не выглядит суперпрорывом, но направление интересное. Если научатся делать хороший foresight pruning, то удастся сэкономить много ресурсов на обучении. Возможно, когда-нибудь получится что-то сравнимое по качеству с традиционным прунингом уже обученных сетей.



2020 March 11
Subclass Distillation
Rafael Müller, Simon Kornblith, Geoffrey Hinton
Статья: https://arxiv.org/abs/2002.03936
Что-то давно мы про дистилляцию не писали. А тут как раз свежая работа от Хинтона и ко. Или от ко и Хинтона. Как посмотреть.
Классическая дистилляция вроде как (ну общей теории дистилляции вроде как никто пока не создал) работает благодаря большому количеству неявной информации, содержащейся в распределении вероятностей неправильных классов, выдаваемых учителем. Поэтому на этих данных студент обучается лучше, чем на hard labels, где только у одного класса единица, а все остальные нули.
А если классов мало, то и дополнительной информации мало. Надо с этим что-то делать.
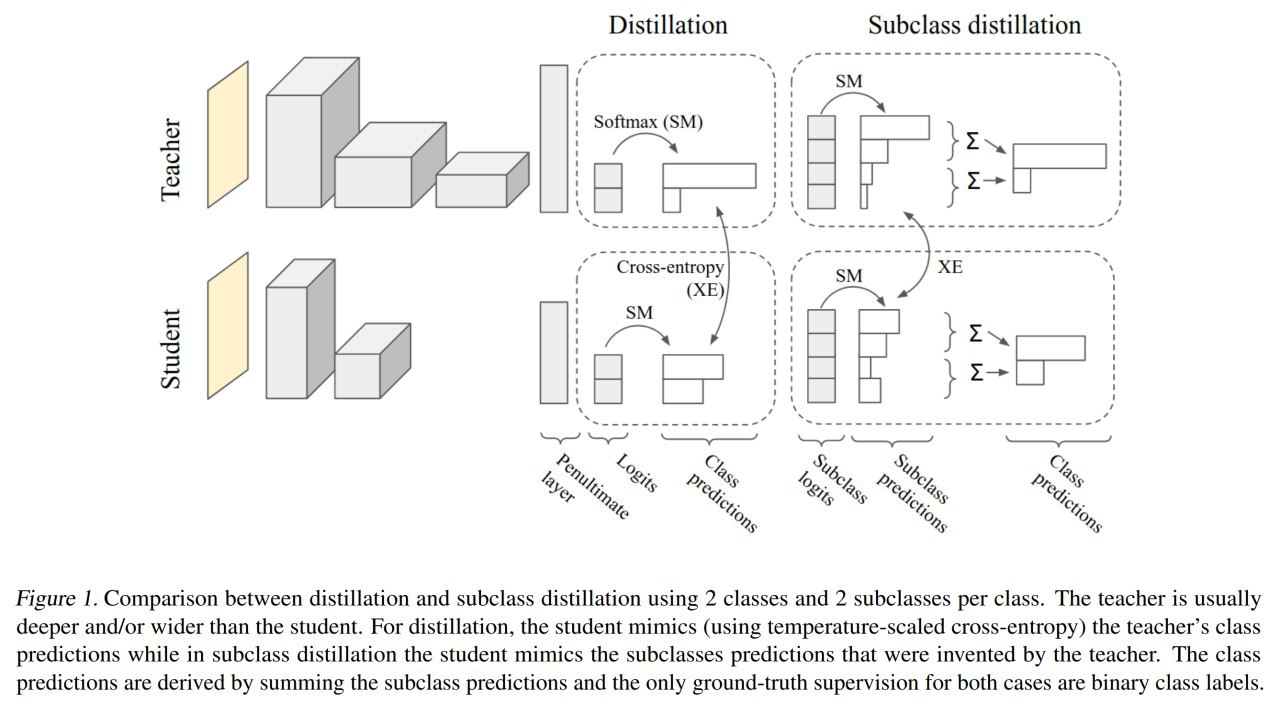
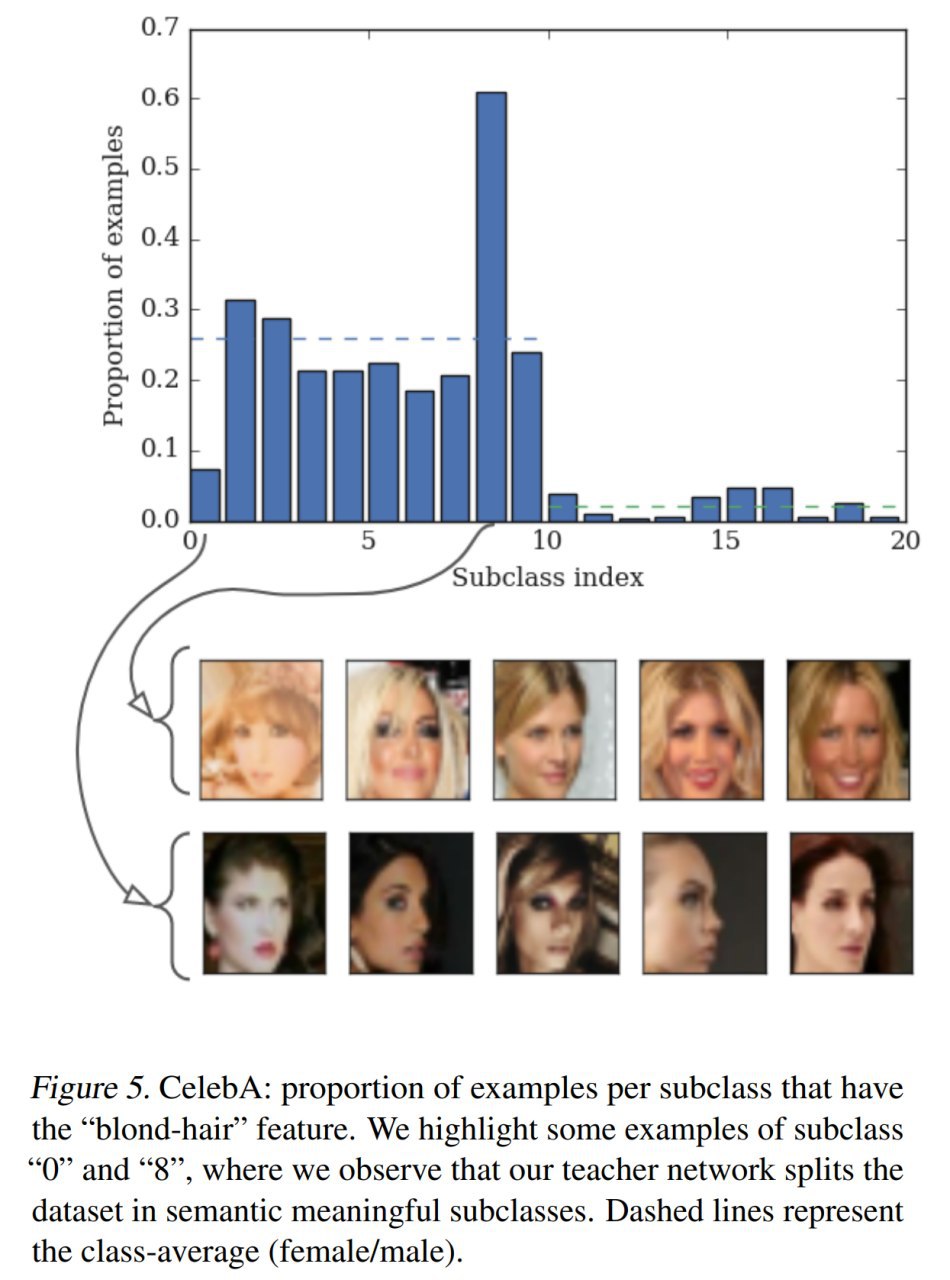
И оказывается, сделать можно, если заставить учителя придумать вымышленные подклассы внутри классов, и на этом обучить студента. Как бонус, сами вымышленные подклассы тоже оказываются интересными, и в случае известных подклассов оказываются похожими на них.
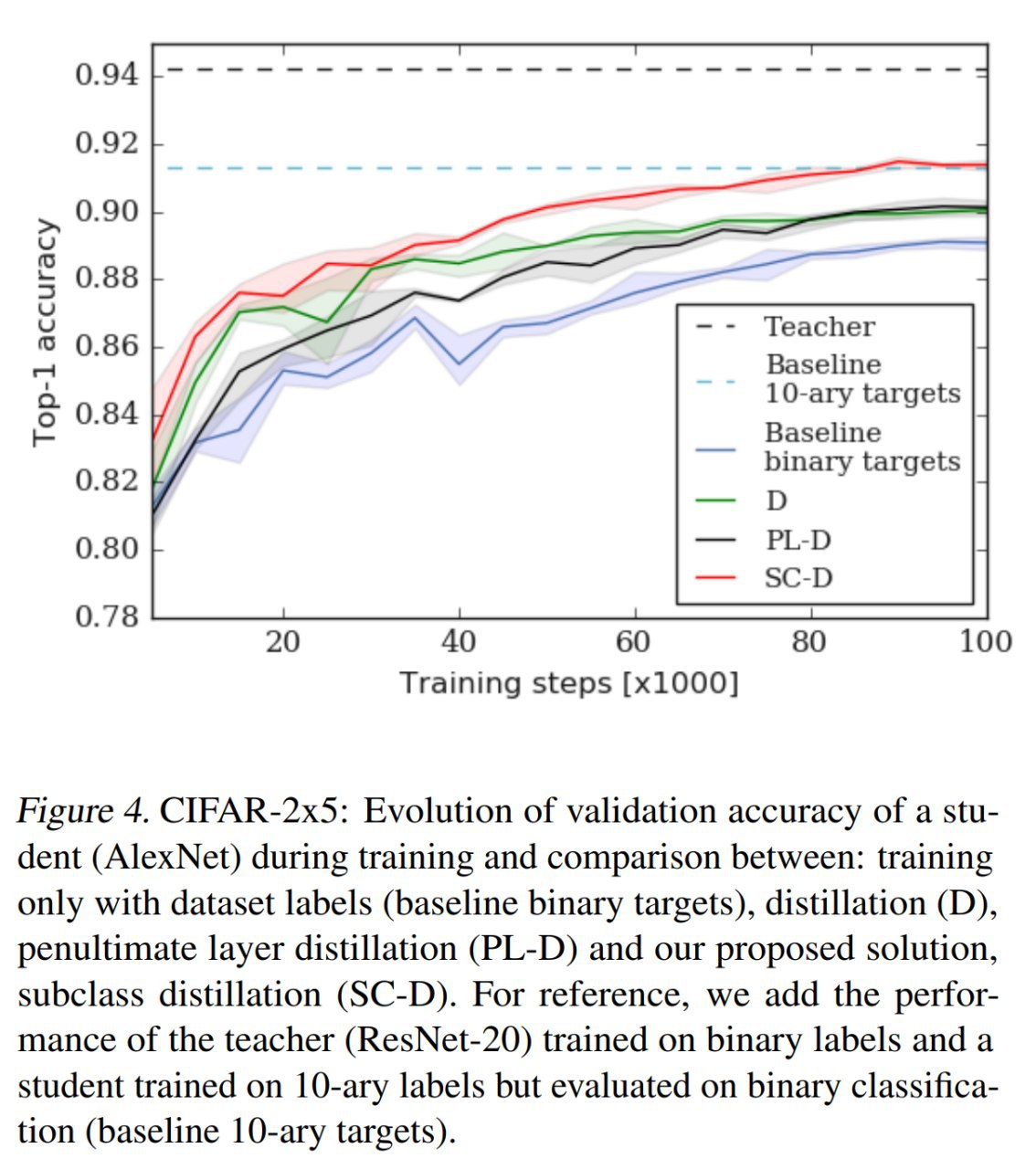
В качестве модельного примера можно взять CIFAR-10 и превратить его в CIFAR-два-по-пять (CIFAR-2x5), где мы группируем наборы по 5 классов в два новых класса (1: airplane, automobile, bird, cat, deer; 2: dog, frog, horse, ship truck).
Далее модифицируется учитель, чтобы у него было 10 логитов на выходе (по числу всех подклассов), которые объединяются в два класса простым суммированием вероятностей после софтмакса.
Учитель обучается на задаче классификации двух классов, не 10, это важно. Подклассами его явно не кормят, он должен сам присвоить какие-то вероятности входящим в класс подклассам. Финальный кросс-энтропийный лосс смотрит только на итоговое качество бинарной классификации.
Ну на самом деле, чтобы стимулировать учителя выучивать нетривиальные подклассы (а то начнёт, скажем, в один подкласс всё запихивать, заполняя остальные нулями), есть ещё один стимулирующий auxiliary loss, подталкивающий сетку раскидывать разные примеры по разным подклассам (даже если они принадлежат одному).
В общем учитель обучается, а потом из него дистиллируется студент. Лосс студента -- это сбалансированный с коэффициентом альфа лосс дистилляции (студент должен имитировать распределение по подклассам учителя) плюс обычный кросс-энтропийный лосс на hard targets (которые в разметке датасета с небольшим числом классов).
Как альтернатива дистилляции подклассов есть ещё дистилляция предпоследнего слоя, где тоже содержится больше информации, чем в последнем. Но по идее в случае подклассов вся нерелевантная классификации информация убирается, чего не скажешь про предпоследний слой, там может быть всякое.
Метод дистилляции подклассов работает. Качество дистилляции повышает. Это во-первых. То есть та самая бинарная классификация на искусственно собранных двух классах CIFAR-2x5 работает лучше. Заодно и классификация на 10 классов тоже работает ощутимо лучше рандома, хоть её специально не обучали. А во-вторых, если глазами посмотреть на придуманные сетью подклассы, то они выглядят вполне разумно (хоть и неидеально).
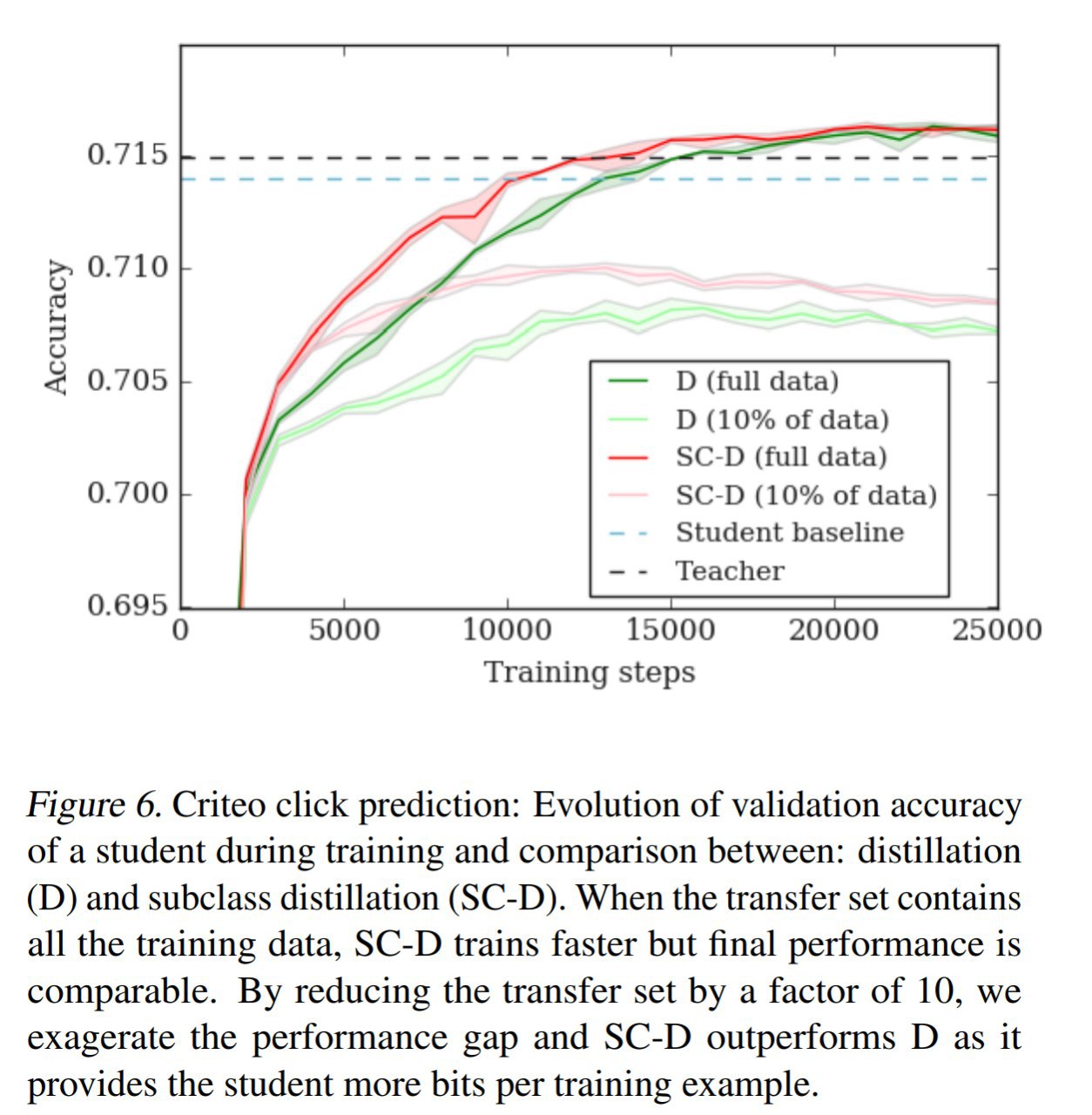
Из менее модельных случаев проверяют метод на CelebA, тоже работает. И ещё на кликовом датасете Criteo, и там работает. Что интересно, на этом датасете и обычная дистилляция и предложенная дают качество выше учителя. Это если обучать на полном датасете (он огромен). Но дистилляция подклассов обучается гораздо быстрее и делает это лучше обычной в случае ограниченных данных.
В общем полезный метод. Есть у него что-то общее с кластеризацией. Может он себя в этом деле ещё покажет.
Rafael Müller, Simon Kornblith, Geoffrey Hinton
Статья: https://arxiv.org/abs/2002.03936
Что-то давно мы про дистилляцию не писали. А тут как раз свежая работа от Хинтона и ко. Или от ко и Хинтона. Как посмотреть.
Классическая дистилляция вроде как (ну общей теории дистилляции вроде как никто пока не создал) работает благодаря большому количеству неявной информации, содержащейся в распределении вероятностей неправильных классов, выдаваемых учителем. Поэтому на этих данных студент обучается лучше, чем на hard labels, где только у одного класса единица, а все остальные нули.
А если классов мало, то и дополнительной информации мало. Надо с этим что-то делать.
И оказывается, сделать можно, если заставить учителя придумать вымышленные подклассы внутри классов, и на этом обучить студента. Как бонус, сами вымышленные подклассы тоже оказываются интересными, и в случае известных подклассов оказываются похожими на них.
В качестве модельного примера можно взять CIFAR-10 и превратить его в CIFAR-два-по-пять (CIFAR-2x5), где мы группируем наборы по 5 классов в два новых класса (1: airplane, automobile, bird, cat, deer; 2: dog, frog, horse, ship truck).
Далее модифицируется учитель, чтобы у него было 10 логитов на выходе (по числу всех подклассов), которые объединяются в два класса простым суммированием вероятностей после софтмакса.
Учитель обучается на задаче классификации двух классов, не 10, это важно. Подклассами его явно не кормят, он должен сам присвоить какие-то вероятности входящим в класс подклассам. Финальный кросс-энтропийный лосс смотрит только на итоговое качество бинарной классификации.
Ну на самом деле, чтобы стимулировать учителя выучивать нетривиальные подклассы (а то начнёт, скажем, в один подкласс всё запихивать, заполняя остальные нулями), есть ещё один стимулирующий auxiliary loss, подталкивающий сетку раскидывать разные примеры по разным подклассам (даже если они принадлежат одному).
В общем учитель обучается, а потом из него дистиллируется студент. Лосс студента -- это сбалансированный с коэффициентом альфа лосс дистилляции (студент должен имитировать распределение по подклассам учителя) плюс обычный кросс-энтропийный лосс на hard targets (которые в разметке датасета с небольшим числом классов).
Как альтернатива дистилляции подклассов есть ещё дистилляция предпоследнего слоя, где тоже содержится больше информации, чем в последнем. Но по идее в случае подклассов вся нерелевантная классификации информация убирается, чего не скажешь про предпоследний слой, там может быть всякое.
Метод дистилляции подклассов работает. Качество дистилляции повышает. Это во-первых. То есть та самая бинарная классификация на искусственно собранных двух классах CIFAR-2x5 работает лучше. Заодно и классификация на 10 классов тоже работает ощутимо лучше рандома, хоть её специально не обучали. А во-вторых, если глазами посмотреть на придуманные сетью подклассы, то они выглядят вполне разумно (хоть и неидеально).
Из менее модельных случаев проверяют метод на CelebA, тоже работает. И ещё на кликовом датасете Criteo, и там работает. Что интересно, на этом датасете и обычная дистилляция и предложенная дают качество выше учителя. Это если обучать на полном датасете (он огромен). Но дистилляция подклассов обучается гораздо быстрее и делает это лучше обычной в случае ограниченных данных.
В общем полезный метод. Есть у него что-то общее с кластеризацией. Может он себя в этом деле ещё покажет.

2020 March 12
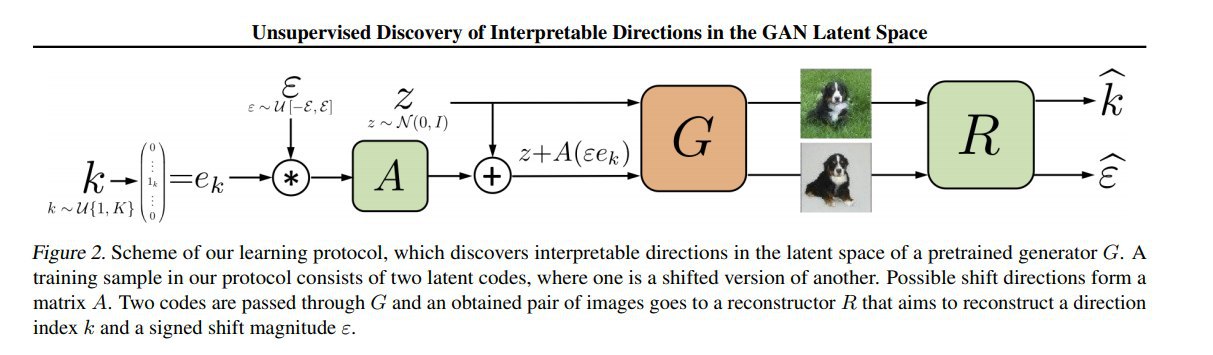
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
Andrey Voynov, Artem Babenko
Yandex, ВШЭ
#GAN, #representation, #latent_space, #ACAI
Статья: https://arxiv.org/abs/2002.03754
Код: https://github.com/anvoynov/GANLatentDiscovery
Свежая работа об изучении свойств латентного пространства, в каком-то смысле перекликающаяся с идеей в основе ACAI, про который мы тут писали аж два раза. Предположим, у нас уже есть обученный GAN с некоторым латентным пространством. Хочется уметь находить в этом пространстве осмысленные направления, соответствующие каким-то семантическим изменениям, не имея заранее списка этих направлений и разметки примеров для них.
Интуиция подсказывает, что смещение в случайном направлении латентного пространства обычно не имеет явно выраженной семантики и влияет сразу на много разных аспектов декодируемого объекта, тогда как смещение по "правильному вектору" приводит к более осмысленному и проще описываемому/оцениваемому изменению.
Отсюда предлагается следующий подход: зафиксировав веса нашей исследуемой сети, будем учить две дополнительные компоненты: "смещатель" и "реконструктор". Смещатель -- это выучиваемая матрица полезных "правильных направлений". Выбирая случайное k-ое направление и случайное расстояние ε, мы из некоторого латентного вектора формируем новый, смещённый на ε в выбранном направлении. Сеть-реконструктор должна, глядя на объекты, сгенерированные из этой пары латентных векторов, восстановить k и ε. Лосс у обоих подсеток общий -- взвешенная сумма кроссэнтропии для реконструкции k и MAE для реконструкции ε, т.е. они играют вместе, пытаясь пробросить информацию о значениях k и ε через генератор. Согласно интуиции, им будет выгодно выбирать наиболее "осмысленные" оси, изменения по которым легче опознавать и оценивать количественно.
Эксперименты показывают, что матрица векторов "смещателя" должна быть так или иначе нормирована (использовали поколоночную нормировку или ортонормированную матрицу).
В качестве реконструктора использовали разные стандартные подходы -- LeNet для MNIST, ResNet-18 для CelebA-HQ и т.п.
Остаётся как-то задать два гиперпараметра -- отношение весов слагаемых лосса (использовали 0.25) и число искомых осей К (выбирали или равное размерности латентного простраства, или на глаз).
Чтобы оценивать интерпретируемость полученных направлений не только на глаз, придумали хитрый костыль Direction Variation Naturalness, основанный на интуицивном ожидании того, что "хорошие" направления должны быть достаточно хорошо и натуралистично представлены в реальных данных. Чтобы оценить это, для фиксированного направления d строят синтетический датасет вида {(G(z±d),±1)} для случайных z, учат на нём бинарный классификатор, потом применяют его к реальным данным и получают второй датасет с реальными картинками и синтетической разметкой от этого классификатора. Снова учат бинарный классификатор уже на этом втором датасете и проверяют его точность на исходном синтетическом датасете. Если распределения объектов в обоих датасетах похожи относительно направления d, то эта accuracy будет высокой.
В результате:
* для Spectral Norm GAN на MNIST нашли направления для наклона цифры, ширины штриха, закруглённости и т.п.
* для Spectral Norm GAN на AnimeFaces нашли направления для цвета волос, направления чёлки, наличия очков и т.п.
* для BigGAN нашлись направления зума, освещённости, поворота, а также размытия и удаления фона.
В финале показывают, как, например, найденное направление "удаления фона" можно использовать для построения датасета для обучения модели saliency detection (локализации объектов на изображении).
Навскидку кажется, что предложенный метод неспецифичен для изображений или GAN-сетей и может быть использован для изучения примерно любого нерегулярного латентного пространства.
Andrey Voynov, Artem Babenko
Yandex, ВШЭ
#GAN, #representation, #latent_space, #ACAI
Статья: https://arxiv.org/abs/2002.03754
Код: https://github.com/anvoynov/GANLatentDiscovery
Свежая работа об изучении свойств латентного пространства, в каком-то смысле перекликающаяся с идеей в основе ACAI, про который мы тут писали аж два раза. Предположим, у нас уже есть обученный GAN с некоторым латентным пространством. Хочется уметь находить в этом пространстве осмысленные направления, соответствующие каким-то семантическим изменениям, не имея заранее списка этих направлений и разметки примеров для них.
Интуиция подсказывает, что смещение в случайном направлении латентного пространства обычно не имеет явно выраженной семантики и влияет сразу на много разных аспектов декодируемого объекта, тогда как смещение по "правильному вектору" приводит к более осмысленному и проще описываемому/оцениваемому изменению.
Отсюда предлагается следующий подход: зафиксировав веса нашей исследуемой сети, будем учить две дополнительные компоненты: "смещатель" и "реконструктор". Смещатель -- это выучиваемая матрица полезных "правильных направлений". Выбирая случайное k-ое направление и случайное расстояние ε, мы из некоторого латентного вектора формируем новый, смещённый на ε в выбранном направлении. Сеть-реконструктор должна, глядя на объекты, сгенерированные из этой пары латентных векторов, восстановить k и ε. Лосс у обоих подсеток общий -- взвешенная сумма кроссэнтропии для реконструкции k и MAE для реконструкции ε, т.е. они играют вместе, пытаясь пробросить информацию о значениях k и ε через генератор. Согласно интуиции, им будет выгодно выбирать наиболее "осмысленные" оси, изменения по которым легче опознавать и оценивать количественно.
Эксперименты показывают, что матрица векторов "смещателя" должна быть так или иначе нормирована (использовали поколоночную нормировку или ортонормированную матрицу).
В качестве реконструктора использовали разные стандартные подходы -- LeNet для MNIST, ResNet-18 для CelebA-HQ и т.п.
Остаётся как-то задать два гиперпараметра -- отношение весов слагаемых лосса (использовали 0.25) и число искомых осей К (выбирали или равное размерности латентного простраства, или на глаз).
Чтобы оценивать интерпретируемость полученных направлений не только на глаз, придумали хитрый костыль Direction Variation Naturalness, основанный на интуицивном ожидании того, что "хорошие" направления должны быть достаточно хорошо и натуралистично представлены в реальных данных. Чтобы оценить это, для фиксированного направления d строят синтетический датасет вида {(G(z±d),±1)} для случайных z, учат на нём бинарный классификатор, потом применяют его к реальным данным и получают второй датасет с реальными картинками и синтетической разметкой от этого классификатора. Снова учат бинарный классификатор уже на этом втором датасете и проверяют его точность на исходном синтетическом датасете. Если распределения объектов в обоих датасетах похожи относительно направления d, то эта accuracy будет высокой.
В результате:
* для Spectral Norm GAN на MNIST нашли направления для наклона цифры, ширины штриха, закруглённости и т.п.
* для Spectral Norm GAN на AnimeFaces нашли направления для цвета волос, направления чёлки, наличия очков и т.п.
* для BigGAN нашлись направления зума, освещённости, поворота, а также размытия и удаления фона.
В финале показывают, как, например, найденное направление "удаления фона" можно использовать для построения датасета для обучения модели saliency detection (локализации объектов на изображении).
Навскидку кажется, что предложенный метод неспецифичен для изображений или GAN-сетей и может быть использован для изучения примерно любого нерегулярного латентного пространства.