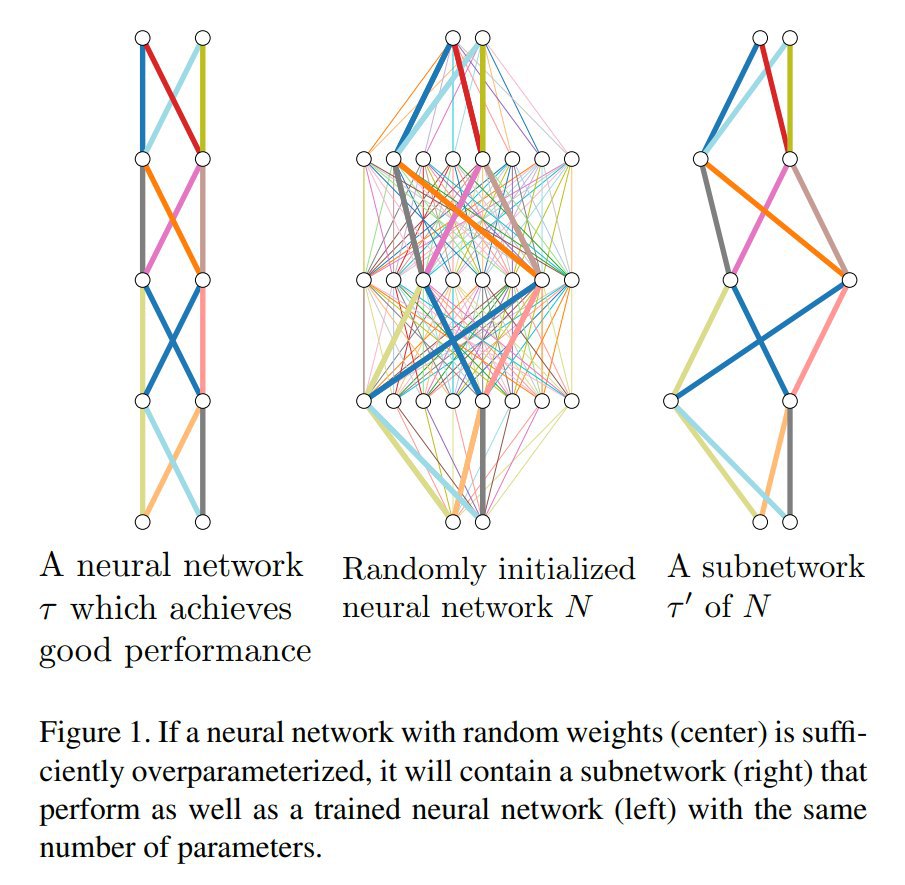
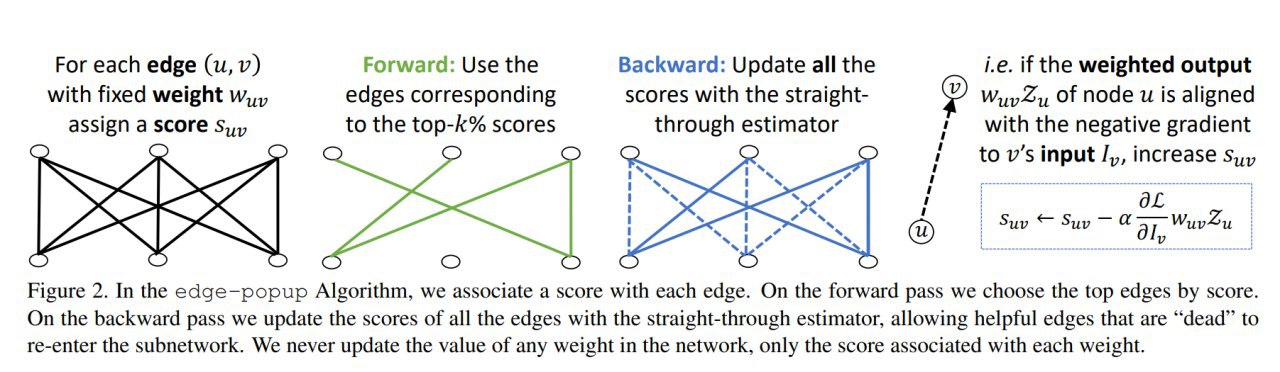
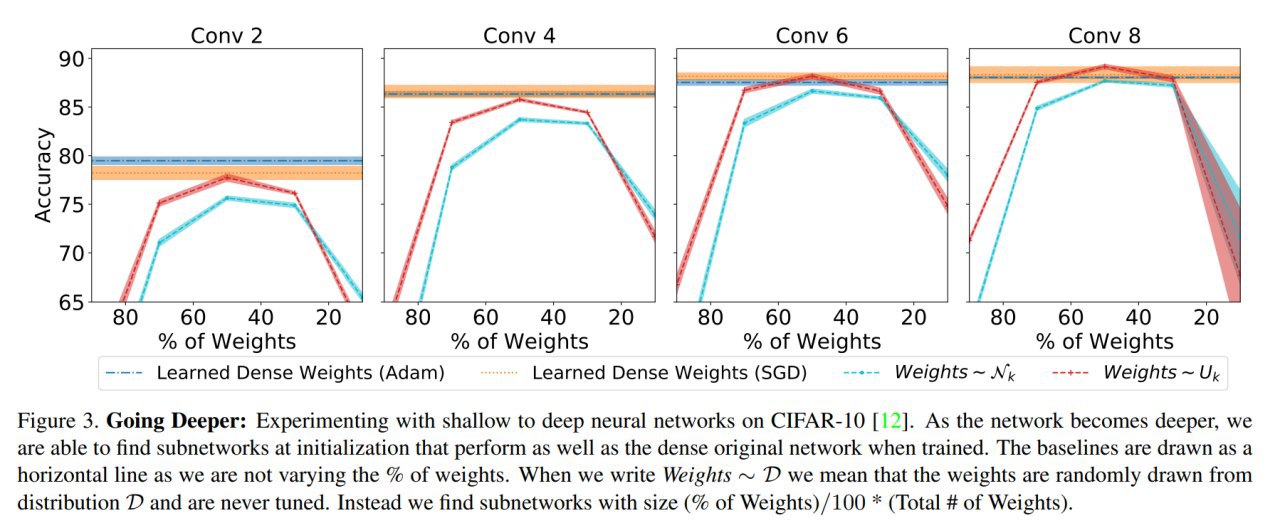
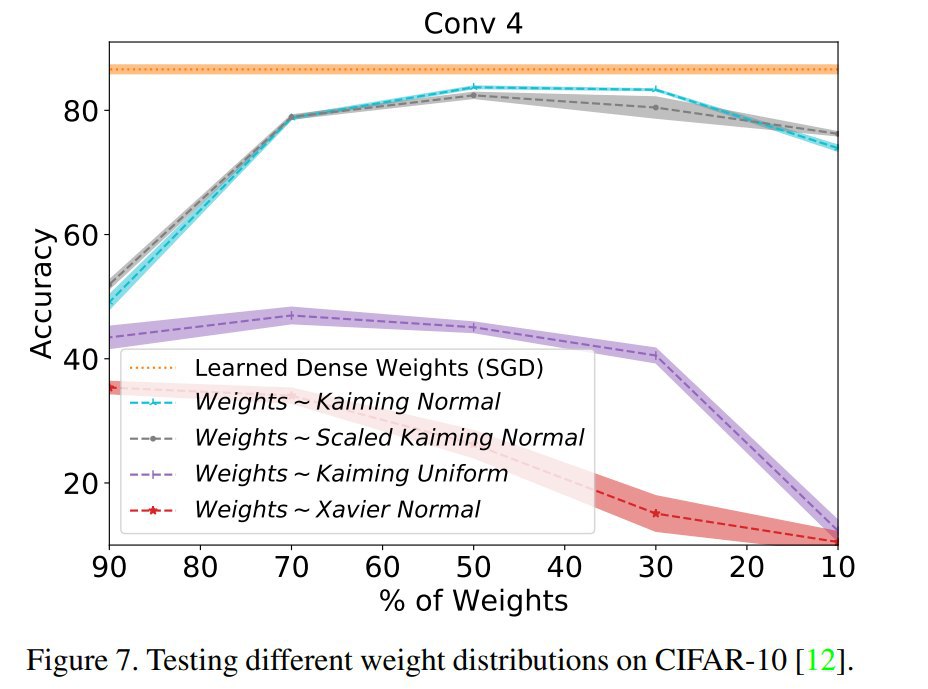
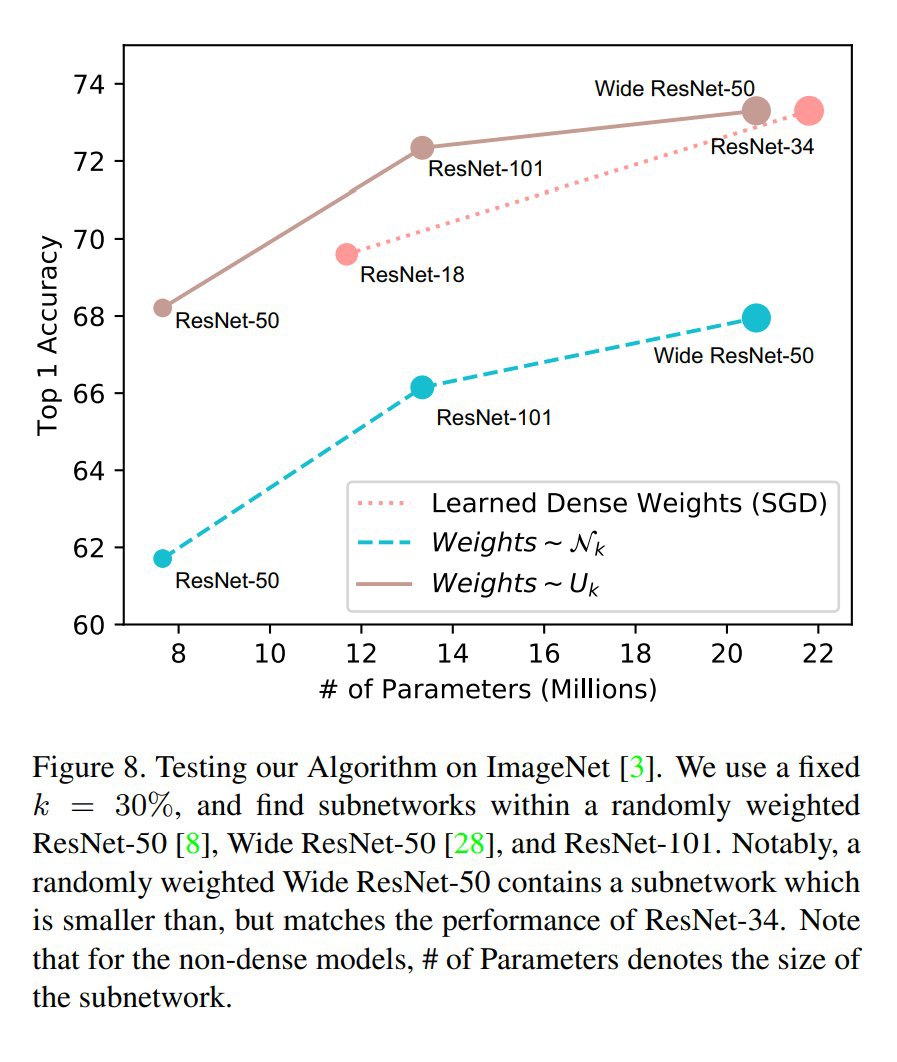
Improving Deep Neuroevolution via Deep Innovation Protection
Sebastian Risi, Kenneth O. Stanley
Статья: https://arxiv.org/abs/2001.01683
Что-то давненько не писали мы про нейроэволюцию. А тут прикольная свежая работа как раз.
Авторы (один из которых -- это, кажется, главный сейчас по нейроэволюции, Kenneth Stanley из Uber AI) предложили метод под названием Deep Innovation Protection (DIP), который улучшает end-to-end обучение сложных world models (архитектура от David Ha и любимого нами Юргена Шмидхубера, World Models, https://arxiv.org/abs/1803.10122) с помощью эволюционных методов.
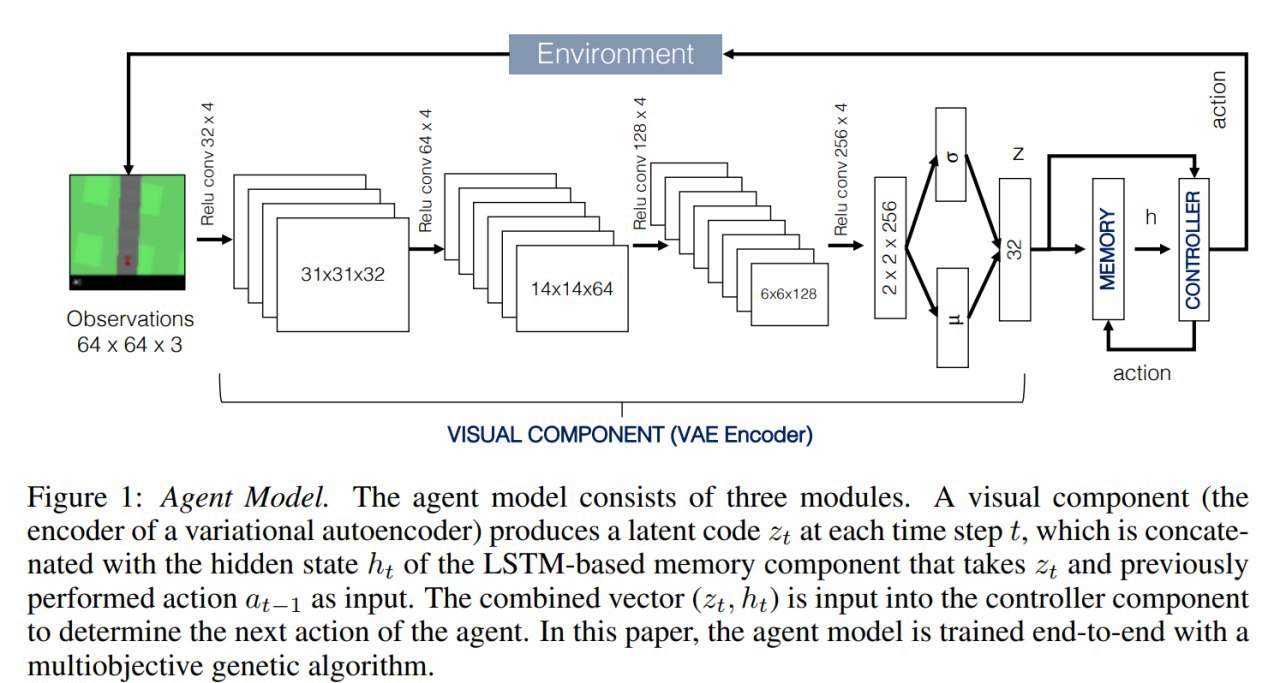
Идея world models (WM), если вы её пропустили, заключалась в том, что архитектура агента состоит из трёх компонентов:
1). Визуальный модуль, который маппит картинку в низкоразмерный код. Здесь использовался VAE.
2). Модуль памяти, который пытается предсказать будущие состояния среды (в виде низкоразмерного кода). Для этого использовалась LSTM с Mixture Density Network (MDN)
3). Контроллер, который берёт данные от визуального модуля и памяти и выдаёт следующее действие.
Оригинальная WM обучалась по частям: сначала визуальный модуль бэкпропом на роллаутах случайной полиси, потом MDN-RNN тоже бэкпропом, а потом уже контроллер через эволюционную стратегию (CMA-ES). Ну то есть нифига не end-to-end. Но работало уже весьма интересно и давало богатую пищу для размышлений.
Примерно полгода назад Стэнли и Риси (авторы текущей статьи) уже реализовали обучение WM end-to-end (Deep Neuroevolution of Recurrent and Discrete World Models, https://arxiv.org/abs/1906.08857) с помощью генетических алгоритмов и добились сравнимого с оригинальной WM результата на 2D car racing.
Но та работа про нейроэволюцию не очень работала на сложных средах с 3D типа WizDoom, и вот наконец текущая работа устраняет эту проблему.
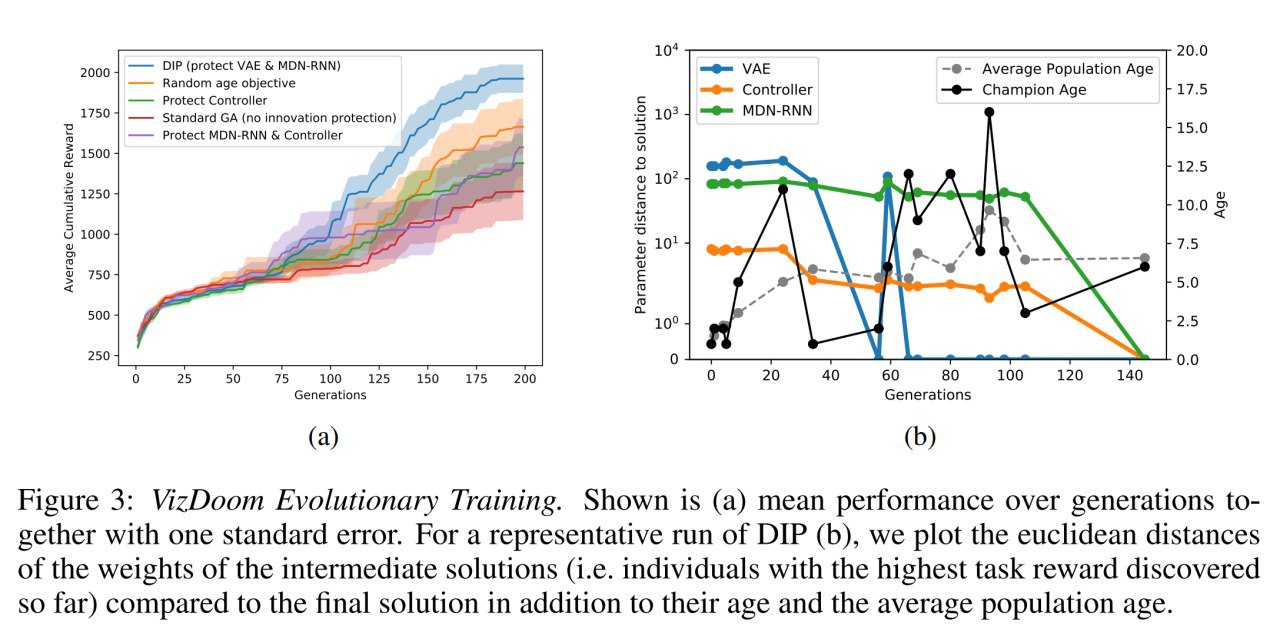
Идея работы в том, что оптимизацию такой гетерогенной сети как WM надо рассматривать как коэволюцию различных подсистем. И если в одной из систем происходит какая-то инновация, то другим системам ещё надо успеть под неё подстроиться, потому что краткосрочно это приводит к деградации. Но вдруг после подстройки новый вариант всех порвёт? Соответственно надо защищать такие свежемутированные варианты, снижая давление отбора на них, тем самым давая время на эту подстройку.
Собственно в этом и идея. Мы трансформируем задачу в задачу многокритериальной оптимизации. Вторым критерием добавляется возраст решения. Если два индивида демонстрируют одинаковый перформанс, то преимущество отдаётся тому, у кого меньше возраст. А возраст сбрасывается в ноль для всех индивидов, у которых мутировала VAE или MDN-RNN (то есть визуальная система или система памяти).
Надо заметить, это заметно отличается от традиционного использования возраста индивида в эволюционных вычислениях, где оно обычно используется для увеличения разнообразия популяции, трекая как долго кто тут уже сидит. Текущий подход тоже в принципе влияет на разнообразие, но здесь возраст используется для подсчёта, сколько времени было у контроллера на подстраивание к изменившимся частям в апстриме.
Теперь и VAE, и MDN-RNN оптимизируются вместе генетическим алгоритмом, не оцениваясь по отдельности. VAE больше не оптимизируется на предмет более качественного восстановления исходной картинки, а модуль памяти больше не натаскивается на предсказание следующего состояния.
В общем в целом подход работает, выживать в среде VizDoom:Take Cover агент научается, DIP профит даёт.
Отдельный интересный вопрос, какие репрезентации сформирует агент для такой постановки, без явной оптимизации на реконструкцию или предсказание будущего. Ну что-то осмысленное вроде как выучивается. Похоже на то, что агент научается предсказывать попадёт в него fireball или нет (что безусловно оч.полезно для выживания в этой среде).
В общем, интересная работа, дальнейшие развития просятся.
#RL, #EVO
Sebastian Risi, Kenneth O. Stanley
Статья: https://arxiv.org/abs/2001.01683
Что-то давненько не писали мы про нейроэволюцию. А тут прикольная свежая работа как раз.
Авторы (один из которых -- это, кажется, главный сейчас по нейроэволюции, Kenneth Stanley из Uber AI) предложили метод под названием Deep Innovation Protection (DIP), который улучшает end-to-end обучение сложных world models (архитектура от David Ha и любимого нами Юргена Шмидхубера, World Models, https://arxiv.org/abs/1803.10122) с помощью эволюционных методов.
Идея world models (WM), если вы её пропустили, заключалась в том, что архитектура агента состоит из трёх компонентов:
1). Визуальный модуль, который маппит картинку в низкоразмерный код. Здесь использовался VAE.
2). Модуль памяти, который пытается предсказать будущие состояния среды (в виде низкоразмерного кода). Для этого использовалась LSTM с Mixture Density Network (MDN)
3). Контроллер, который берёт данные от визуального модуля и памяти и выдаёт следующее действие.
Оригинальная WM обучалась по частям: сначала визуальный модуль бэкпропом на роллаутах случайной полиси, потом MDN-RNN тоже бэкпропом, а потом уже контроллер через эволюционную стратегию (CMA-ES). Ну то есть нифига не end-to-end. Но работало уже весьма интересно и давало богатую пищу для размышлений.
Примерно полгода назад Стэнли и Риси (авторы текущей статьи) уже реализовали обучение WM end-to-end (Deep Neuroevolution of Recurrent and Discrete World Models, https://arxiv.org/abs/1906.08857) с помощью генетических алгоритмов и добились сравнимого с оригинальной WM результата на 2D car racing.
Но та работа про нейроэволюцию не очень работала на сложных средах с 3D типа WizDoom, и вот наконец текущая работа устраняет эту проблему.
Идея работы в том, что оптимизацию такой гетерогенной сети как WM надо рассматривать как коэволюцию различных подсистем. И если в одной из систем происходит какая-то инновация, то другим системам ещё надо успеть под неё подстроиться, потому что краткосрочно это приводит к деградации. Но вдруг после подстройки новый вариант всех порвёт? Соответственно надо защищать такие свежемутированные варианты, снижая давление отбора на них, тем самым давая время на эту подстройку.
Собственно в этом и идея. Мы трансформируем задачу в задачу многокритериальной оптимизации. Вторым критерием добавляется возраст решения. Если два индивида демонстрируют одинаковый перформанс, то преимущество отдаётся тому, у кого меньше возраст. А возраст сбрасывается в ноль для всех индивидов, у которых мутировала VAE или MDN-RNN (то есть визуальная система или система памяти).
Надо заметить, это заметно отличается от традиционного использования возраста индивида в эволюционных вычислениях, где оно обычно используется для увеличения разнообразия популяции, трекая как долго кто тут уже сидит. Текущий подход тоже в принципе влияет на разнообразие, но здесь возраст используется для подсчёта, сколько времени было у контроллера на подстраивание к изменившимся частям в апстриме.
Теперь и VAE, и MDN-RNN оптимизируются вместе генетическим алгоритмом, не оцениваясь по отдельности. VAE больше не оптимизируется на предмет более качественного восстановления исходной картинки, а модуль памяти больше не натаскивается на предсказание следующего состояния.
В общем в целом подход работает, выживать в среде VizDoom:Take Cover агент научается, DIP профит даёт.
Отдельный интересный вопрос, какие репрезентации сформирует агент для такой постановки, без явной оптимизации на реконструкцию или предсказание будущего. Ну что-то осмысленное вроде как выучивается. Похоже на то, что агент научается предсказывать попадёт в него fireball или нет (что безусловно оч.полезно для выживания в этой среде).
В общем, интересная работа, дальнейшие развития просятся.
#RL, #EVO