
Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation using Deep Neural Networks
Charith Mendis, Alex Renda, Saman Amarasinghe, Michael Carbin
Статья: https://arxiv.org/abs/1808.07412
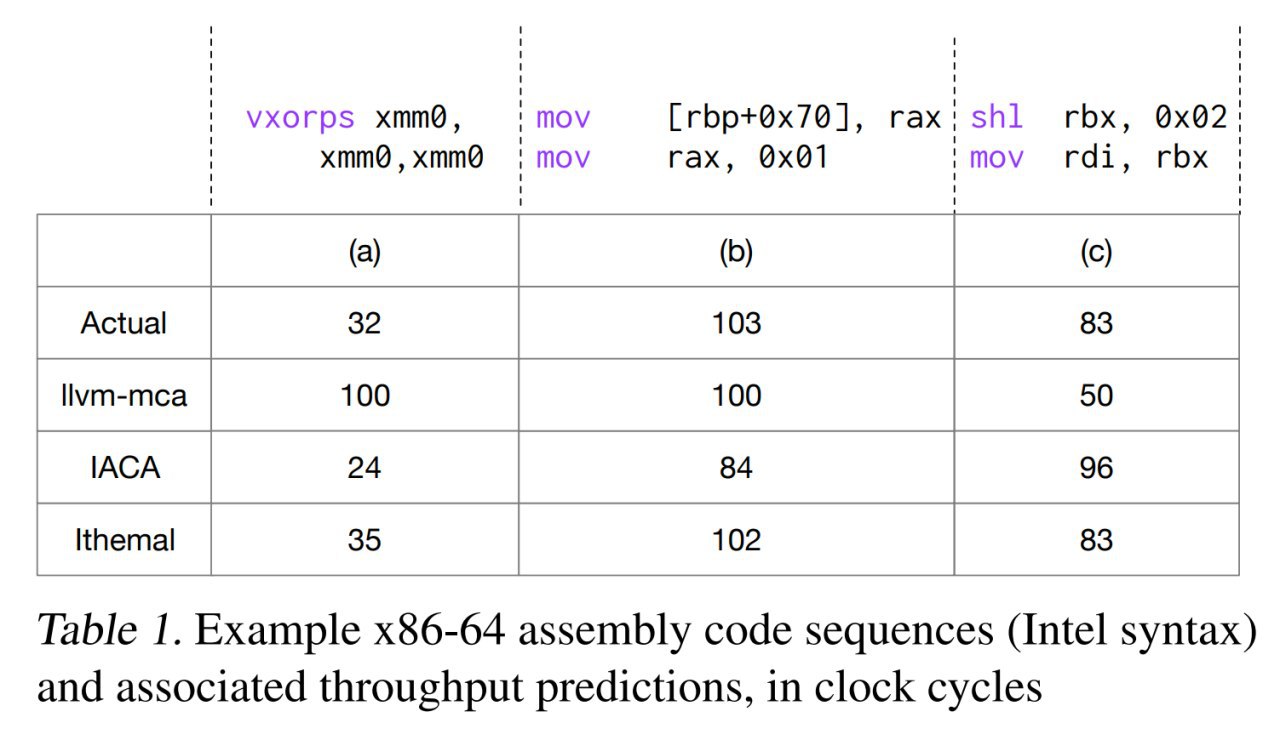
Прикольная статья достойная конференции SysML. Авторы представили тул, Ithemal (Instruction THroughput Estimator using MAchine Learning), который предсказывает throughput (количество циклов процессора, требуемых для выполнения) набора машинных инструкций. И делает это лучше, чем родная интеловская тулза или тулза из комплекта LLVM. Ещё и так же быстро.
Тулза пока работает только с простыми блоками (без ветвления и переходов)
Задача состоит в том, что чтобы сгененировать эффективный код под конкретную архитектуру (рассматриваются x86-64), надо хорошо уметь оценивать различные альтернативы и правильно предсказывать их производительность на конкретной микроархитектуре. Ибо те же микроархитектуры Haswell и Skylake внутри довольно различны, хоть внешне и предоставляют одинаковый набор команд.
Решить эту задачу довольно сложно. Лучший подход -- взять и всё померять (много раз), но он долгий. Поэтому приходится пользоваться суррогатами. Например, моделью процессора. Но модель получается довольно сложной, должна учитывать много тонкостей работы современного процессора (out-of-order execution, micro-op fusion, register renaming и т.д.). Плюс, в реальных процессорах многое недокументировано (по крайней мере для широкой публики), так что сделать такую модель кому-то кроме Интела/АМД довольно сложно. Да и те ошибаются, как показано в работе. Да ещё и под свежие микроархитектуры не умеют быстро выпускать обновления модели.
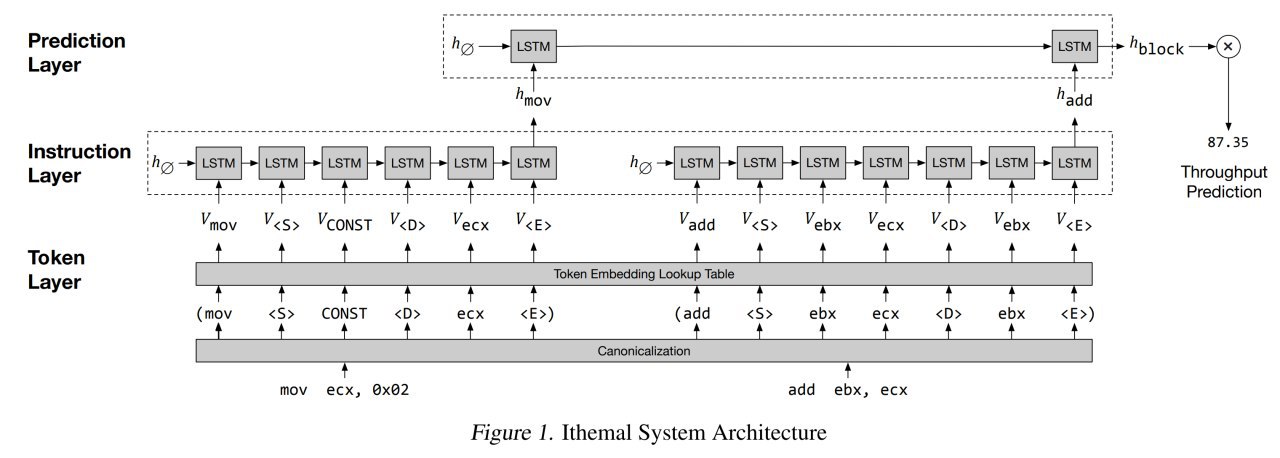
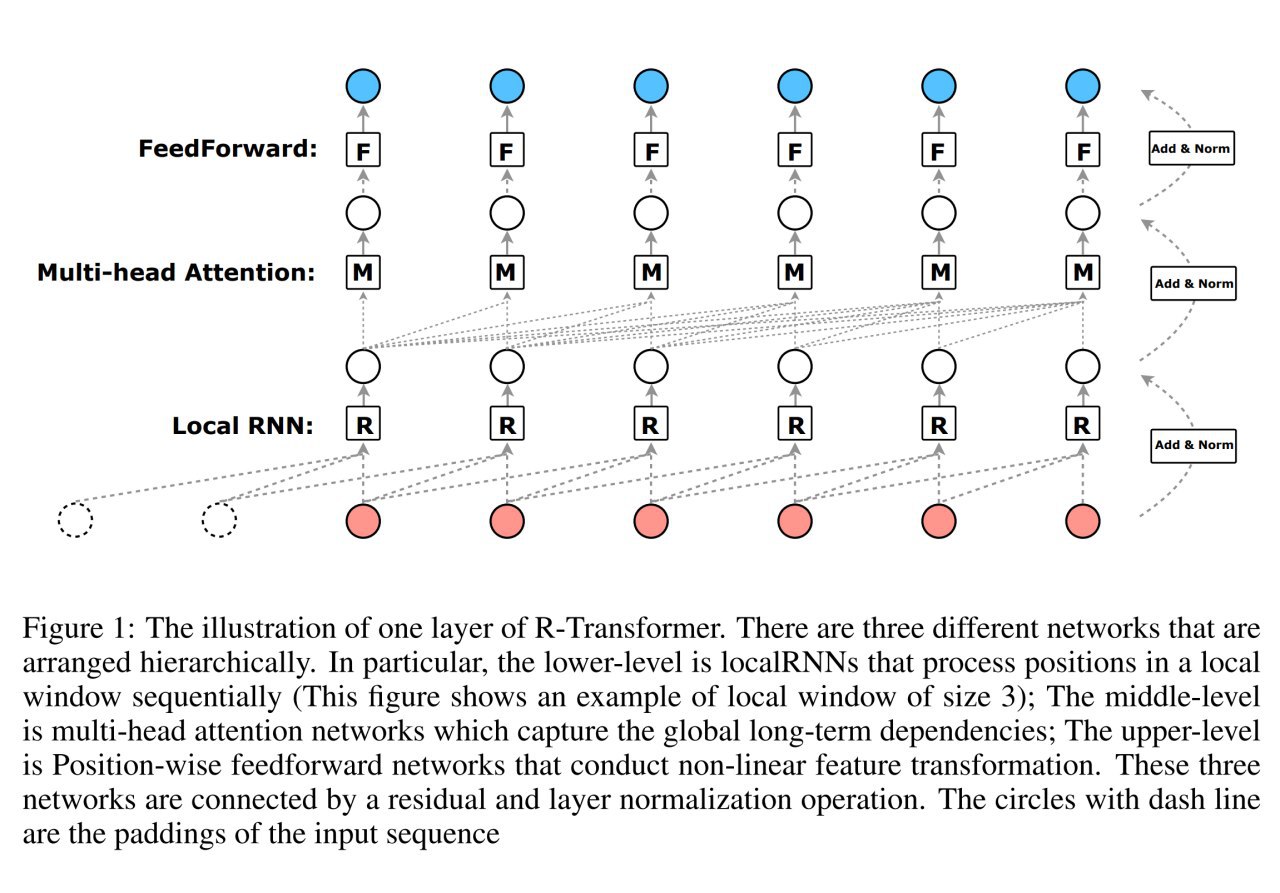
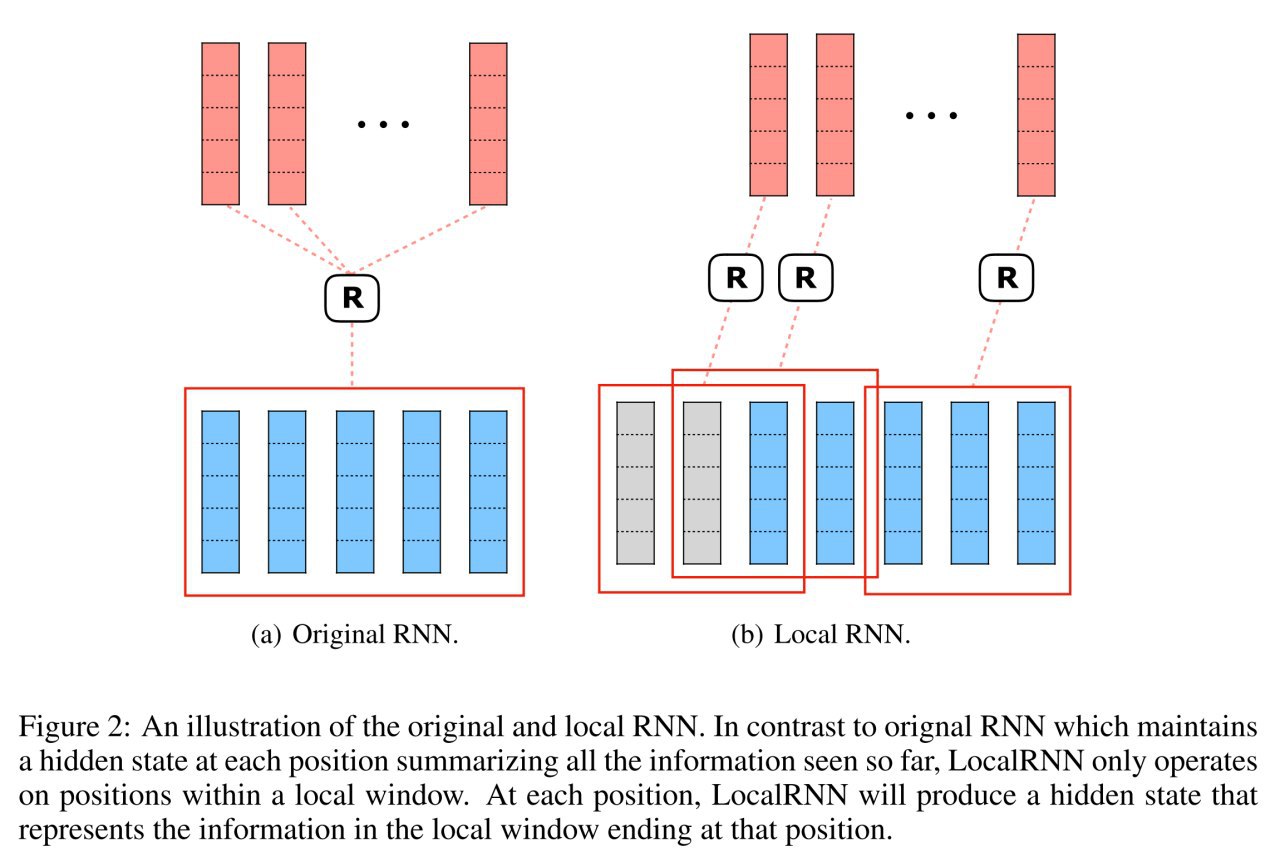
Раз всё так сложно, давайте попробуем решить задачу сеточками. Пусть производительность последовательности инструкций предсказывает hierarchical multiscale LSTM.
Иерархичность модели в том, что одна часть сети выучивает хорошие представления инструкций, а следующая из них вычисляет представления блоков инструкций, из которого уже регрессией предсказывается throughput.
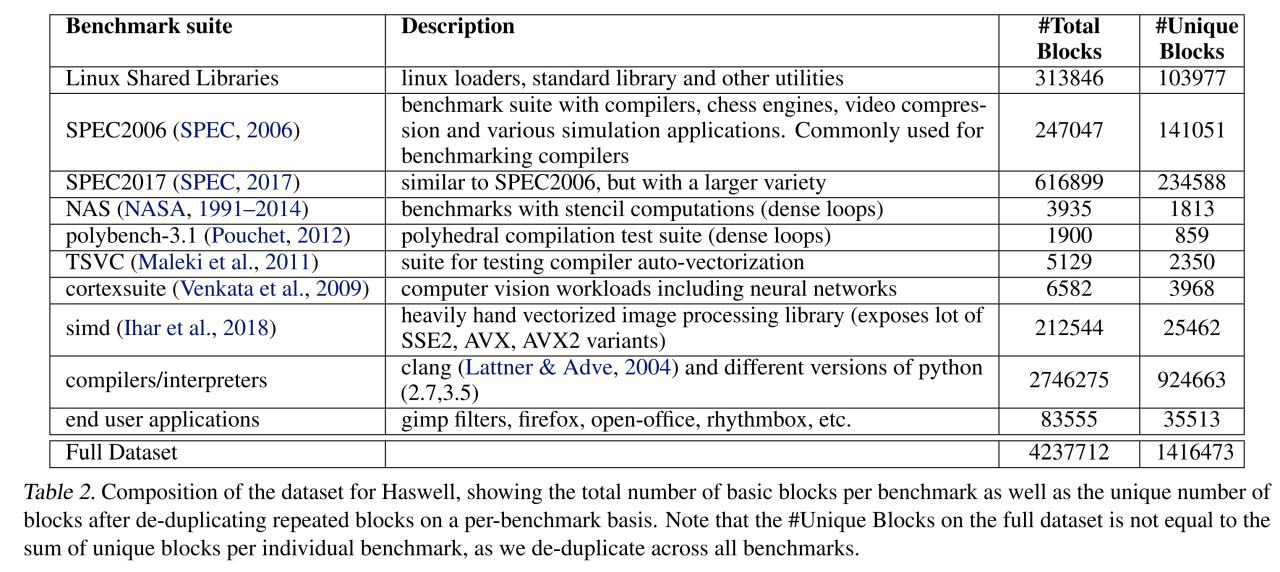
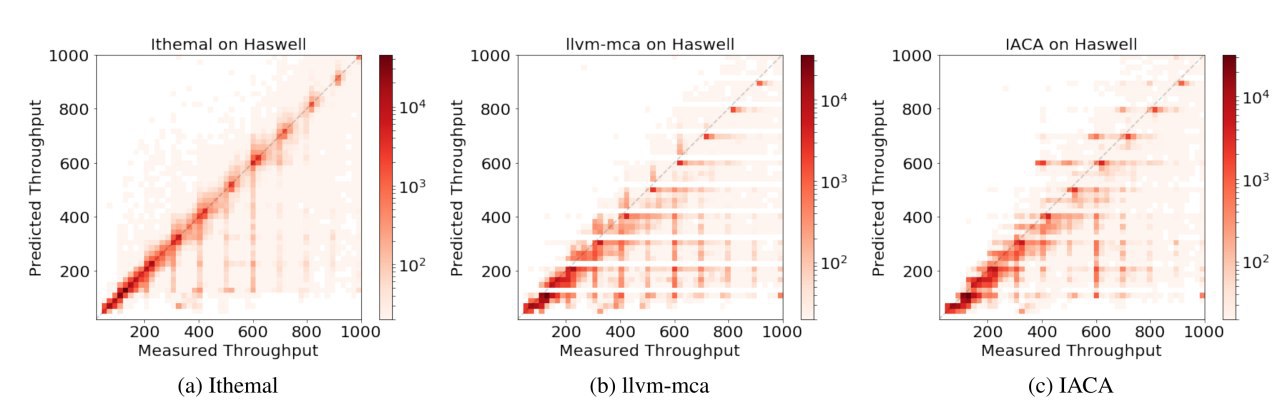
Подход хорош тем, что он целиком data driven. Собираем набор бенчмарков (кодов), компилим с оптимизациями под конкретные архитектуры, извлекаем блоки инструкций и их коды, многократно замеряем время выполнения. Сбор данных занимает 4-5 дней на каждую микроархитектуру. Затем обучаем модель на имеющихся данных. Получает state-of-the-art prediction performance. Profit!