Just Add Functions: A Neural-Symbolic Language Model
David Demeter, Doug Downey
Статья:
https://arxiv.org/abs/1912.05421Прикольная статья про расширение нейросетевых языковых моделей (Neural Network Language Model, NNLM) более правильными inductive biases путём внедрения простых функций. Эти функции явно кодируют символьные отношения и выдают вероятностные распределения для слов.
У NNLM есть проблемы с некоторыми текстами, например, если там встречаются определённые пространственные, временные или количественные отношения.
Например, предсказание последнего слова в тексте:
William the Conqueror won the Battle of Hastings in 1066, and died in [1087]
где мы знаем, что это скорее всего четырёхзначное число большее (но не сильно) 1066.
Или в тексте:
Exciting European cities are Paris, Rome and [London]
где мы скорее всего ожидаем что-то географически близкое к перечисленным.
Эту всю логику довольно непросто заложить в классические NNLM, но можно легко описать простыми математическими или логическими выражениями.
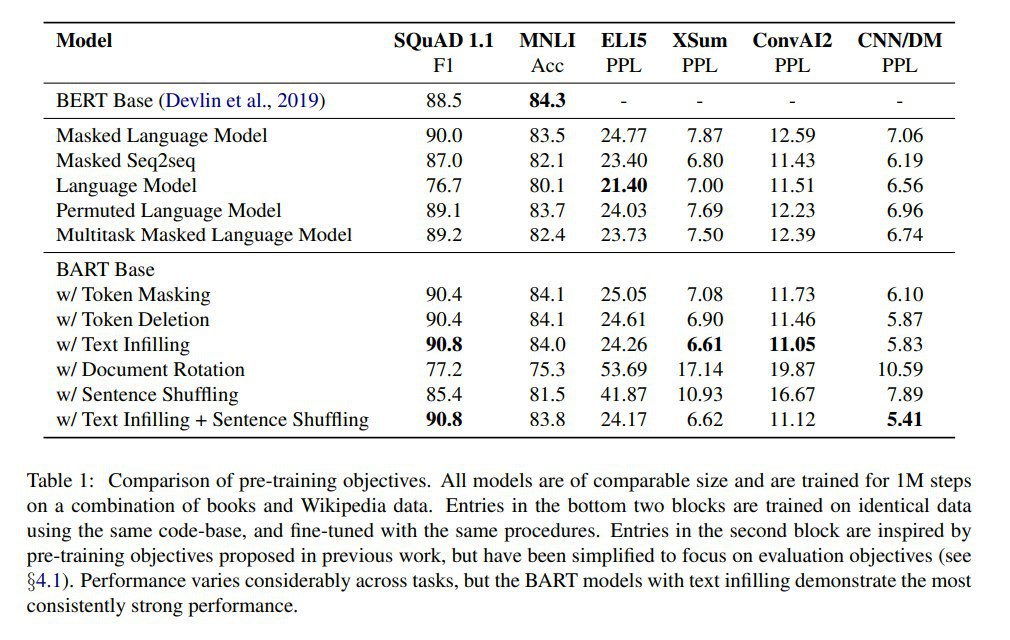
Собственно после добавления в модель таких функций и получается нейро-символьная языковая модель (Neuro-Symbolic Language Model, NSLM).
NSLM представляет собой иерархическую NNLM (HNLM), генерирующую совместное распределение классов и слов. Простые функции используются для явного кодирования вероятностных распределений слов внутри класса. В работе такие функции называются микро-моделями (micro-models, MM). В обычных иерархических языковых моделях на месте микро-модели была бы какая-то другая сеточка.
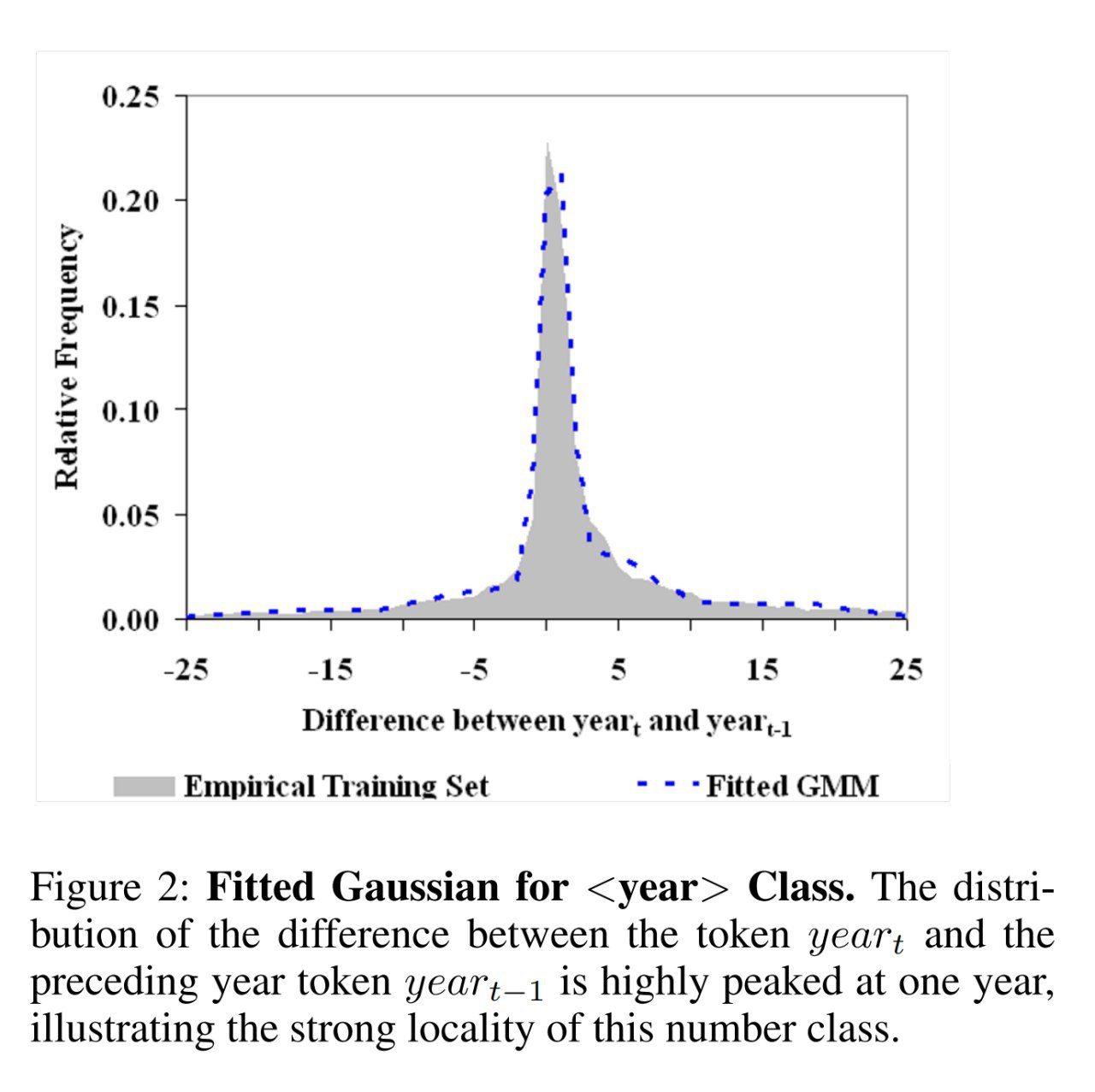
Например, для класса <год> такой функцией может быть гауссиана (параметры которой выучены из данных), задающая дельту (в годах) между предыдущей уже встреченной в тексте датой (годом) и текущим словом, про которое модель решила, что это класс <год>.
Микро-модель задаётся метрической функцией (например, вычисляющей численную разницу между значениями двух токенов в случае класса <год>) и вероятностным распределением (PDF, в которую это значение трансформируется).
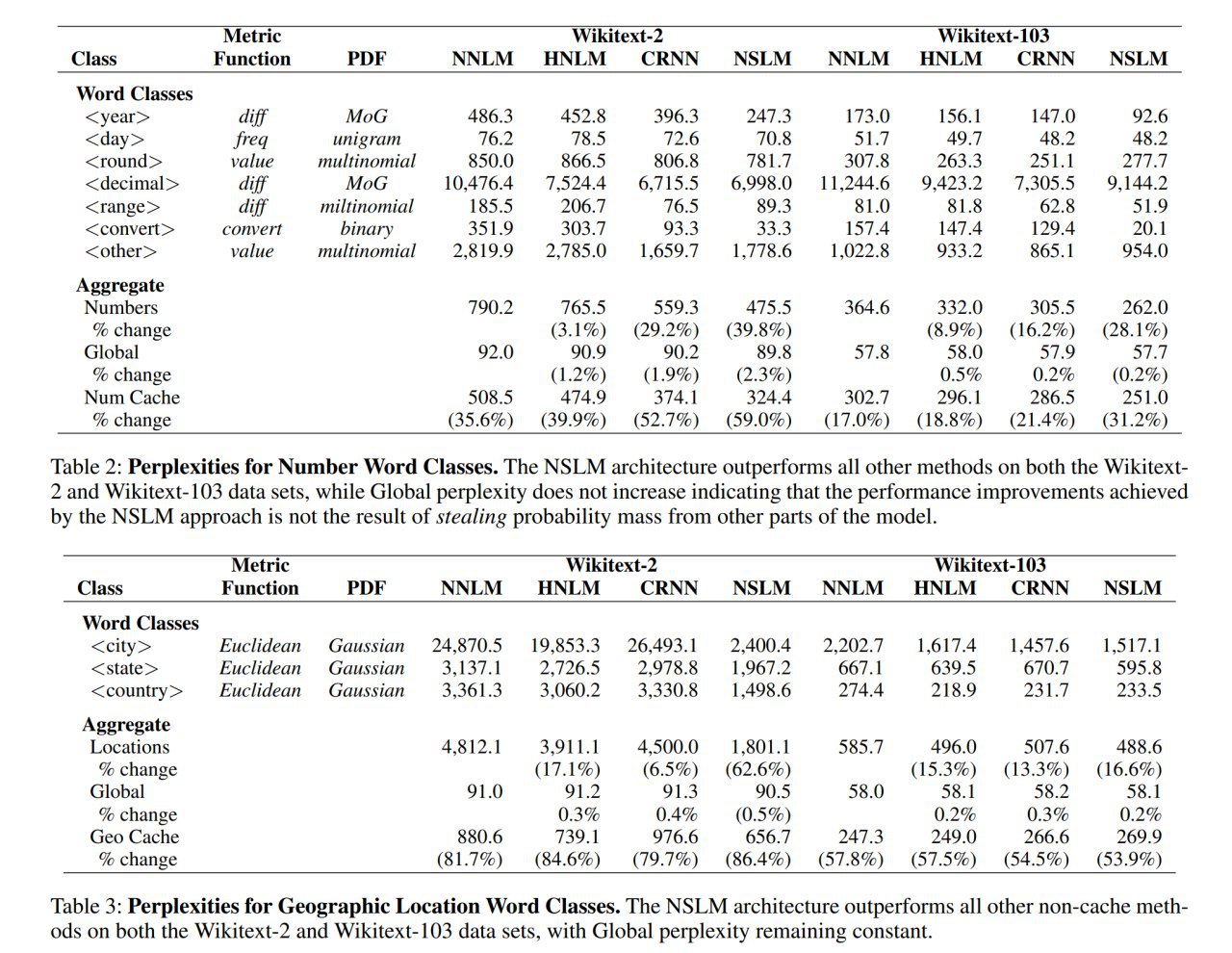
В работе NSLM делается на базе LSTM и разбираются классы про числа (year, day, round, decimal, range, convert) и географию (city, state, country).
NSLM бьёт по perplexity различные бейзлайны (LSTM NNLM, HNLM, character RNN, Neural cache models). На больших датасетах преимущество не настолько большое, но всё равно остаётся значительным на редких токенах. Более хитрые бейзлайны (например, с эмбеддингами, обученными на 6B корпусе, или с добавлением в эмбеддинги географических координат) тоже бьёт. И более продвинутую современную AWD-LSTM бьёт.
В общем получился красивый простой метод затачивания NNLM под доменно-специфичные задачи.