Продолжаем дистиллировать данные.
Dataset Distillation
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, Alexei A. Efros
Статья:
https://arxiv.org/abs/1811.10959Страница:
https://ssnl.github.io/dataset_distillation/Код:
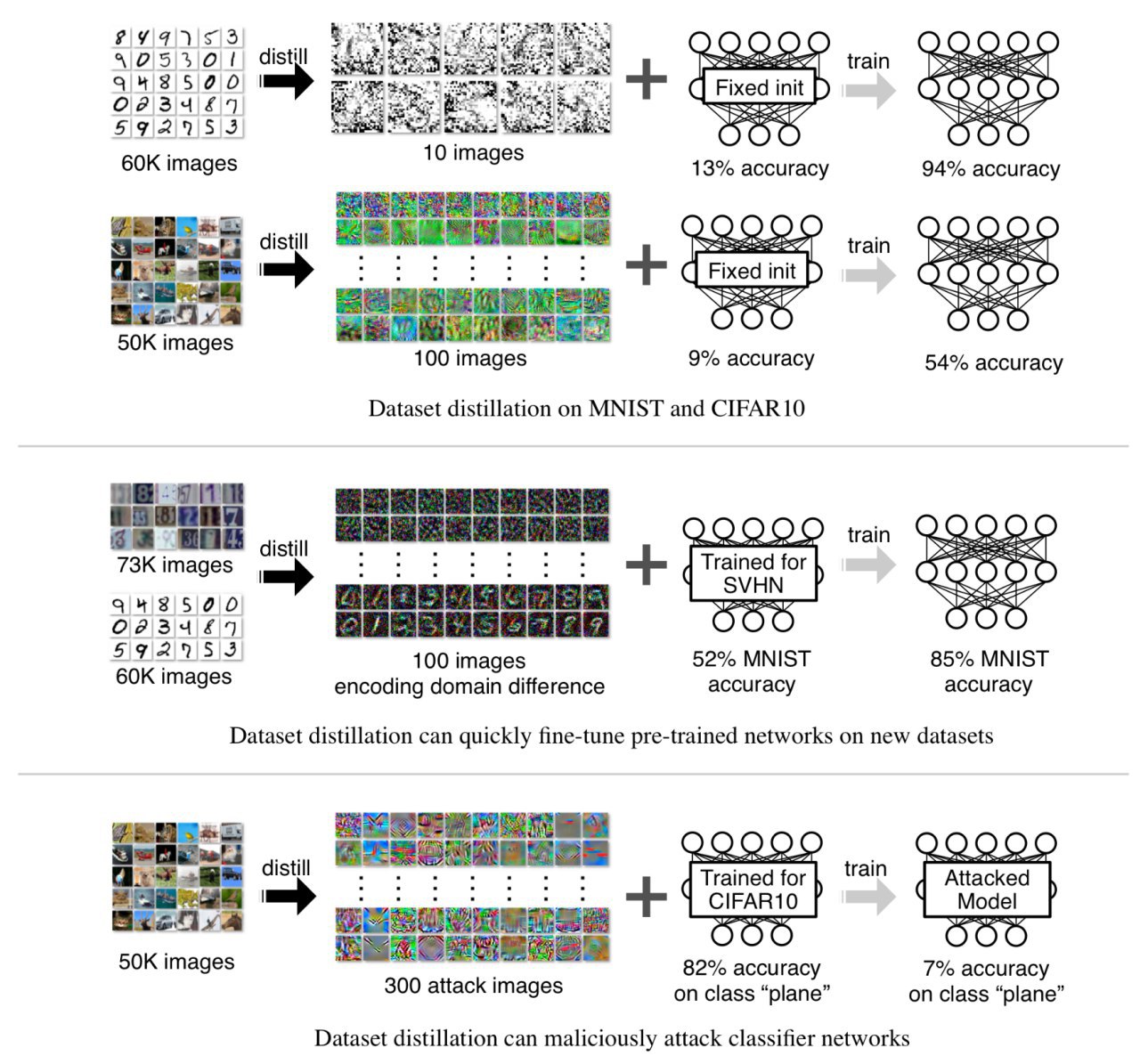
https://github.com/SsnL/dataset-distillationТеперь заход с другой стороны — что если модель не трогать, а большой датасет отдистиллировать в маленький? Например, превратить 60000 обучающих примеров MNIST’а в 10? Причём не как раньше, когда пытались оставлять наиболее значимые примеры, а прям вот создать синтетические примеры (возможно не из того многообразия, где обитают сами исходные данные), на которых модель хорошо и быстро обучится.
Оказывается, можно.
Это идейно похоже на процесс генерации картинок, максимально активирующих нейроны конкретных классов, где backprop применяется для генерации входных данных, а не для обновления весов модели. Здесь мы генерим входные примеры, которые дадут минимальный лосс через шаг (или много шагов, потому что одного обычно совсем недостаточно) градиентного спуска относительно начальных весов.
В прямолинейном варианте подход требует знания начальных весов сети. В более интересном варианте достаточно знать распределение, из которого сэмплили начальные веса. Для моделей, предобученных на другие задачи (AlexNet), метод может найти дистиллированный датасет для быстрого файнтюнинга.
Полученный дистиллированный датасет представляет интерес не только для изучения, он полезен также для continual learning методов, где часто сохраняется в специальном буфере подмножество обучающих примеров, на которых проверяется качество и блокируются изменения, ухудшающие его. Дистиллированный датасет выглядит интересной заменой такого случайного подмножества (занимает мало места и содержит много важной информации для обучения).
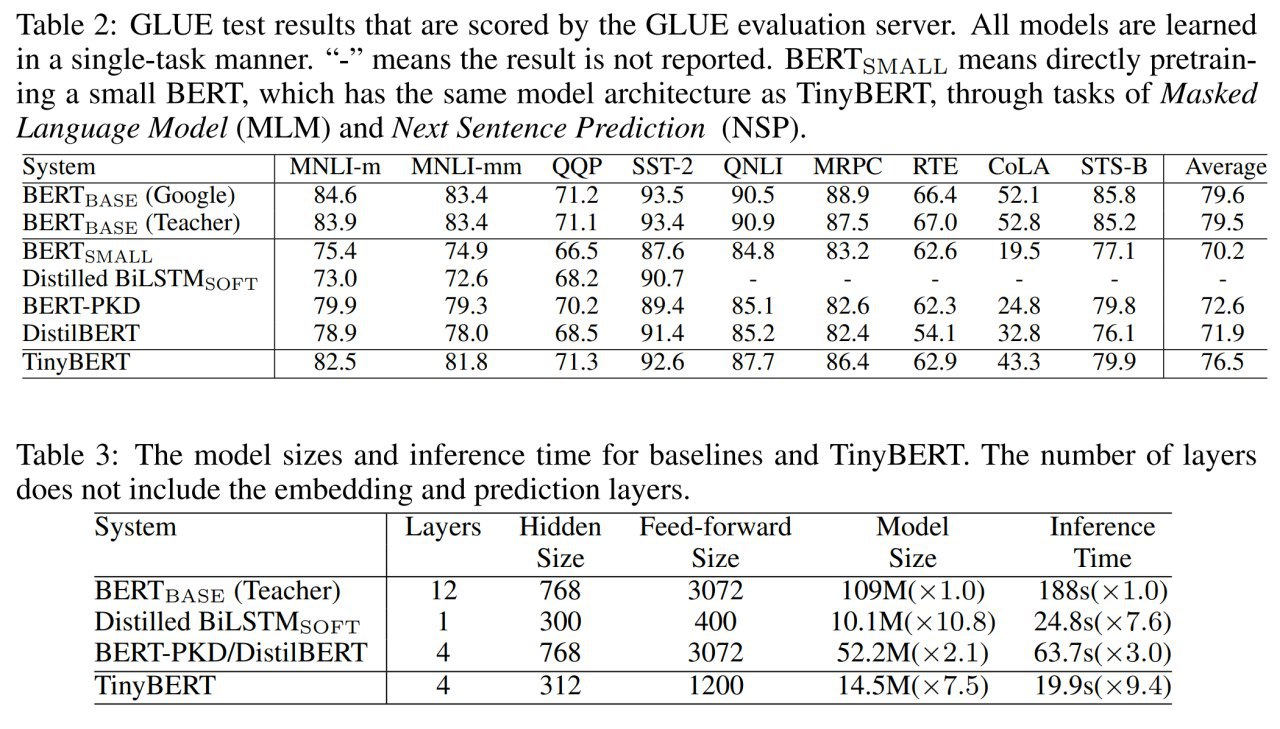
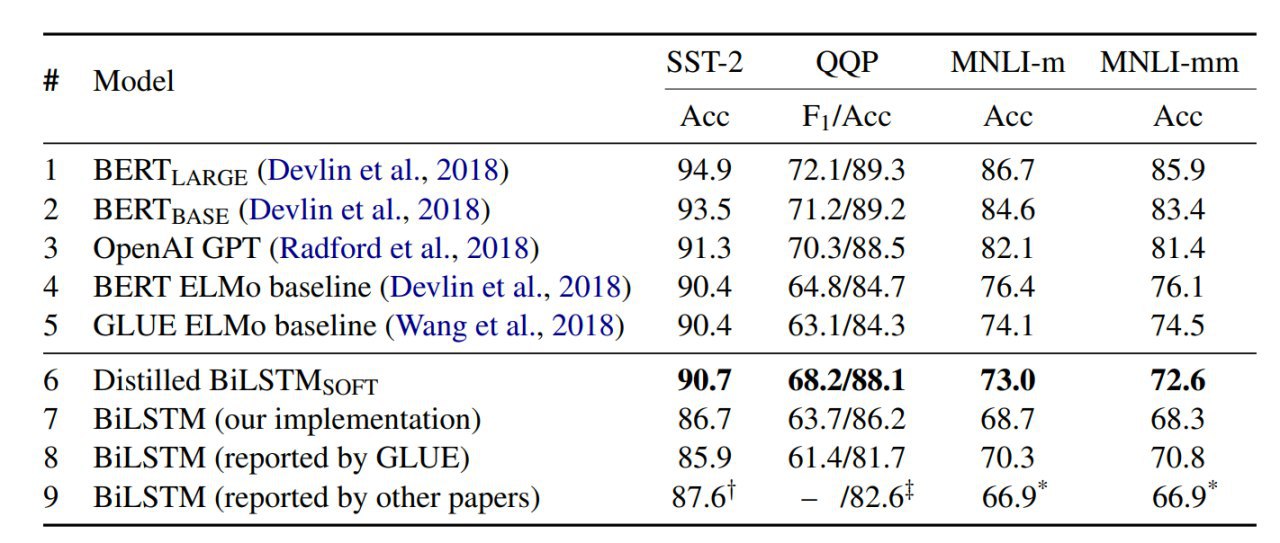
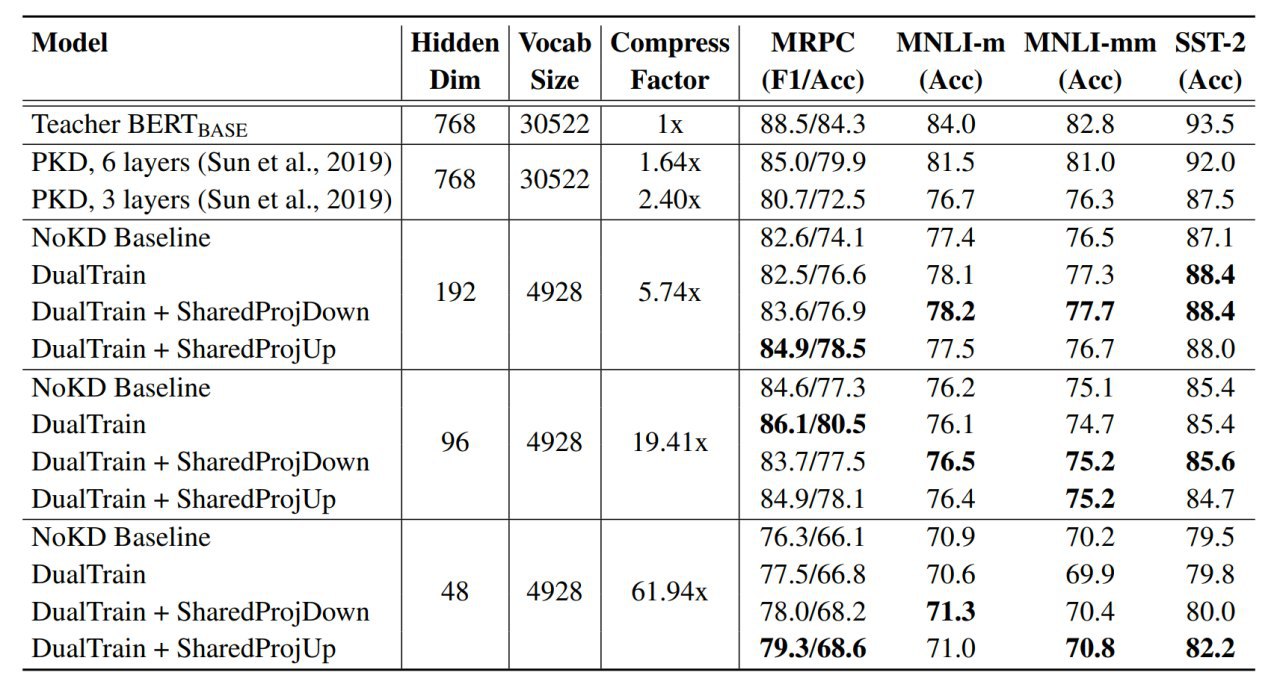
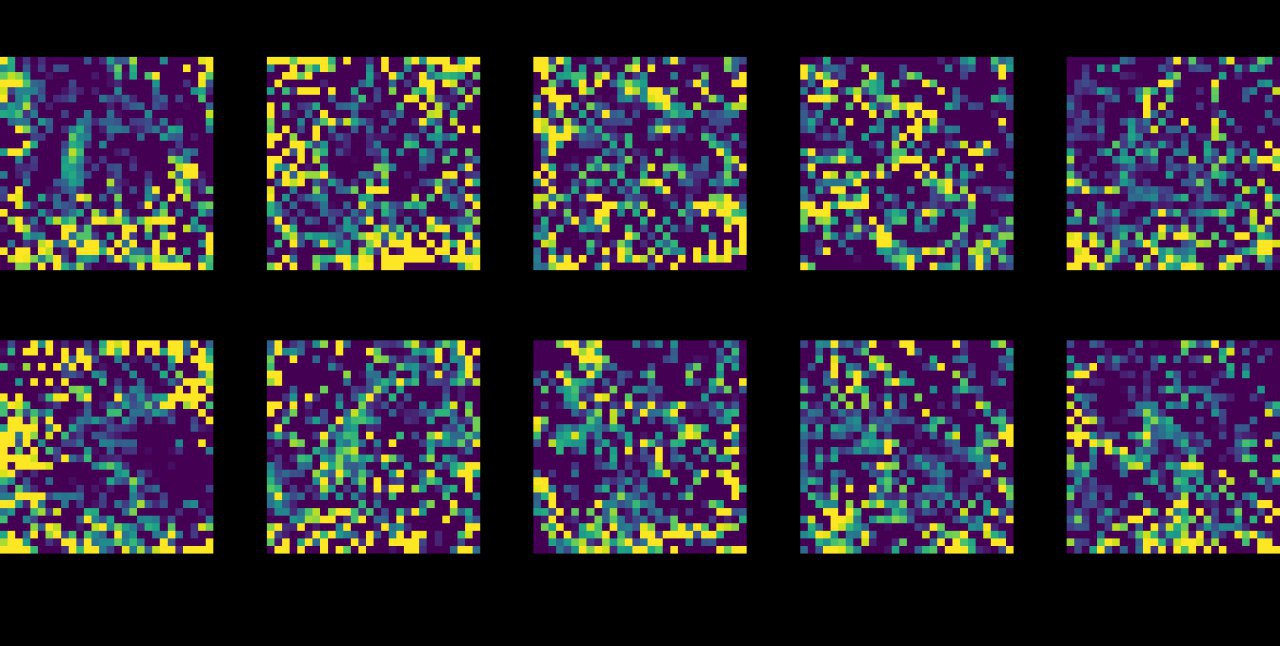
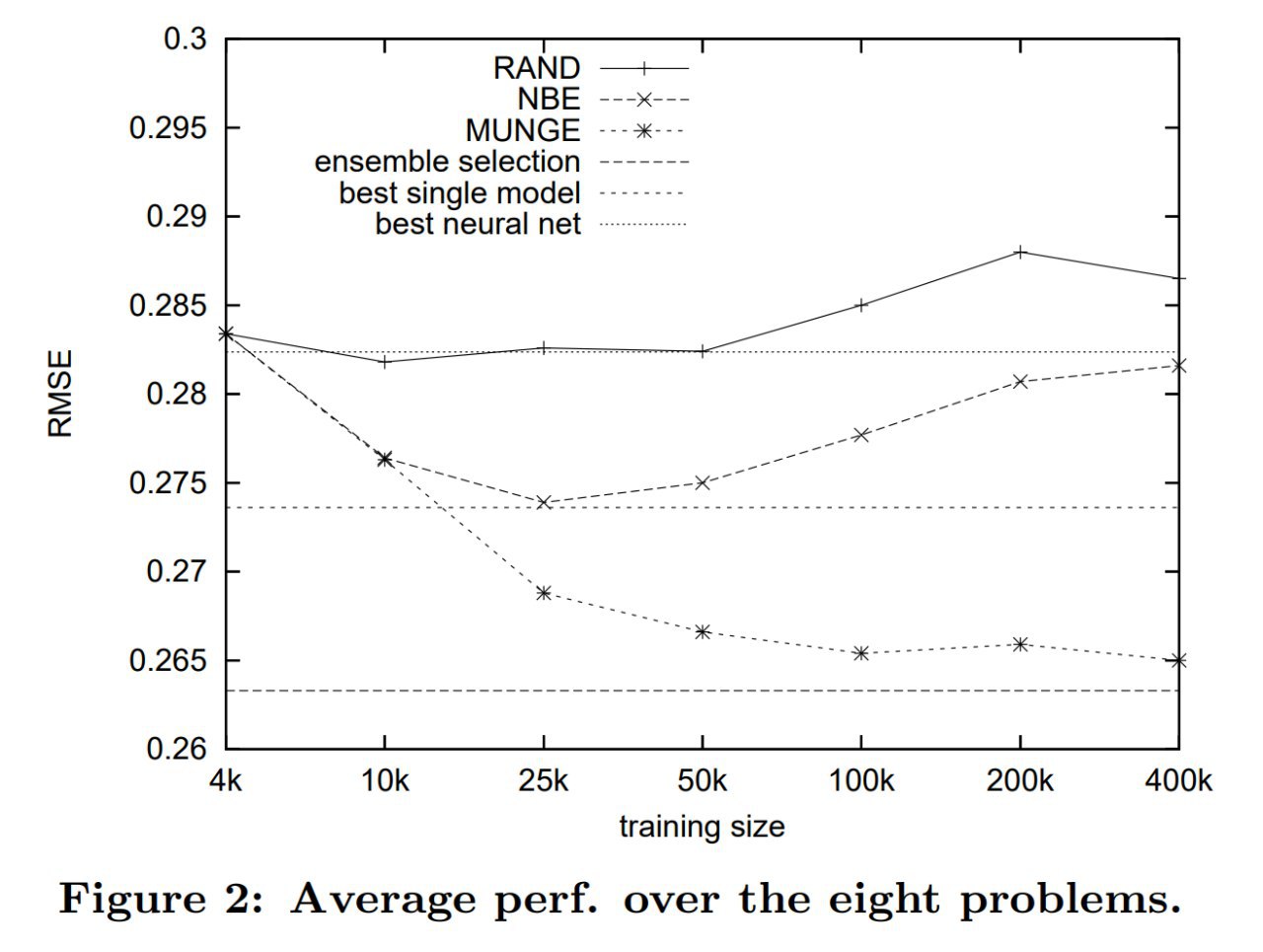
На MNIST получилось отдистиллировать весь датасет в 10 примеров (по одному на класс!), на которых LeNet обучается до почти 94% точности за 2000 шагов градиентного спуска с фиксированной инициализацией. С рандомной инициализацией 88.5%. На CIFAR10 тоже интересные результаты.
Неплохо также работает адаптация между MNIST/USPS/SVHN.
Или, например, получается адаптация претренированной AlexNet на PASCAL-VOC и CUB-200 датасеты с одной картинкой на категорию.
Метод заточен на конкретные архитектуры и инициализации, есть куда расширять. Но выглядит очень интересно. Например, можно существенно сократить вычисления на оценку моделей в neural architecture search (помните эти страшные цифры?
https://www.technologyreview.com/s/613630/training-a-single-ai-model-can-emit-as-much-carbon-as-five-cars-in-their-lifetimes/)
Статья подана на ICLR 2020.
Дистиллированные картинки выглядят интересно. Есть над чем подумать.
Отдельное направление для применения этой работы — data poisoning attack. Из сабмита на ICLR эту часть убрали :) Наверняка готовят отдельную статью, это обещает быть сильно.
Хитрый data poisoning с помощью дистилляции позволяет сгенерить небольшое число примеров, которые всего за одну итерацию обучения сильно портят одну конкретную категорию классификации, не трогая остальные. Без доступа к точным значениям весов модели!