The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Maxwell Forbes, Yejin Choi
University of Washington, Allen Institute for Artificial Intelligence
#NLP #LM #sampling #beamsearch
Статья: https://arxiv.org/abs/1904.09751
Простенькая статья, которой, однако, давно не хватало. Аккуратно разбирают различные стратегии сэмплинга уже обученной LM. Противопоставляют open-ended сэмплинг (открытый сэмплинг, например, в GPT-2) и non-open-ended — когда сэмплинг имеет фиксированную цель (например, в NMT).
Дают красивое объяснение, почему open-ended сэмплинг обычно вырождается в повторение в случае использования beamseach стратегии — с каждым повторением вероятность следующего повторения растёт, образуется петля положительной обратной связи, соответственно, бимсёрч идёт по полю с воронками и так или иначе куда-то сваливается.
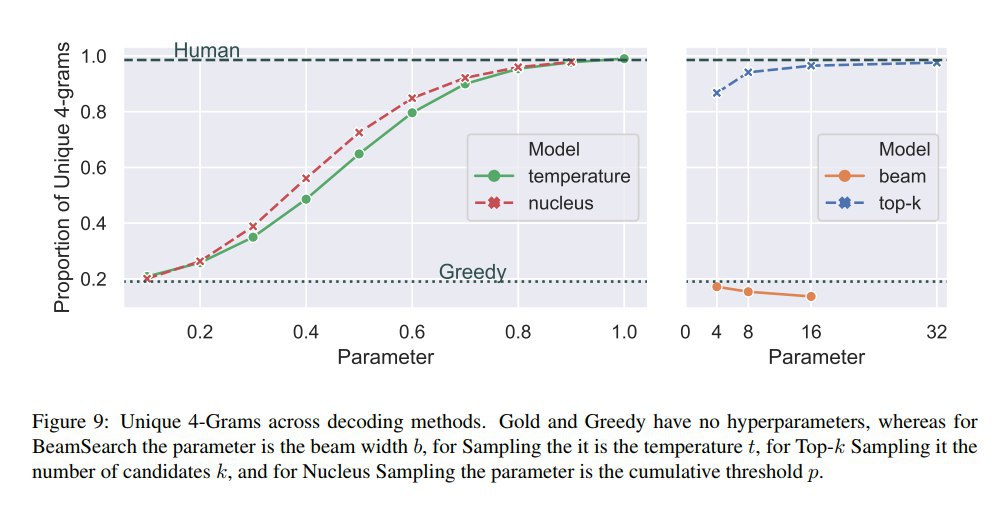
Кроме того, анализ частот n-gram показывает, что в реальной речи гораздо больше "чёрных лебедей", чем даёт сэмплинг по максимизации правдоподобия, а beamsearch даёт ровную высоковероятную картину.
С другой стороны, сэмплить из всего словаря с вероятностью, предсказанной моделью тоже не очень хорошо: в хвосте слова с эпсилон-вероятностями, но их много, и суммарно они дают высокую вероятность насэмплить полной фигни, по оценке авторов обычно эта вероятность около 30%, поэтому на 20 шагах вероятность зачерпнуть из хвоста 0.9996, в результате чего мы наблюдаем мусор, сломанную грамматику и т.п..
Далее рассматриваются разные способы, улучшающие ситуацию — температура, сэмплинг из top-K слов, а также предлагается несложный способ (Nucleus (Top-p) Sampling) адаптивно выбирать топ для сэмплинга по суммарной вероятности. Показывают, что такой способ даёт наиболее похожие на человеческие частоты n-gram.
Ari Holtzman, Jan Buys, Maxwell Forbes, Yejin Choi
University of Washington, Allen Institute for Artificial Intelligence
#NLP #LM #sampling #beamsearch
Статья: https://arxiv.org/abs/1904.09751
Простенькая статья, которой, однако, давно не хватало. Аккуратно разбирают различные стратегии сэмплинга уже обученной LM. Противопоставляют open-ended сэмплинг (открытый сэмплинг, например, в GPT-2) и non-open-ended — когда сэмплинг имеет фиксированную цель (например, в NMT).
Дают красивое объяснение, почему open-ended сэмплинг обычно вырождается в повторение в случае использования beamseach стратегии — с каждым повторением вероятность следующего повторения растёт, образуется петля положительной обратной связи, соответственно, бимсёрч идёт по полю с воронками и так или иначе куда-то сваливается.
Кроме того, анализ частот n-gram показывает, что в реальной речи гораздо больше "чёрных лебедей", чем даёт сэмплинг по максимизации правдоподобия, а beamsearch даёт ровную высоковероятную картину.
С другой стороны, сэмплить из всего словаря с вероятностью, предсказанной моделью тоже не очень хорошо: в хвосте слова с эпсилон-вероятностями, но их много, и суммарно они дают высокую вероятность насэмплить полной фигни, по оценке авторов обычно эта вероятность около 30%, поэтому на 20 шагах вероятность зачерпнуть из хвоста 0.9996, в результате чего мы наблюдаем мусор, сломанную грамматику и т.п..
Далее рассматриваются разные способы, улучшающие ситуацию — температура, сэмплинг из top-K слов, а также предлагается несложный способ (Nucleus (Top-p) Sampling) адаптивно выбирать топ для сэмплинга по суммарной вероятности. Показывают, что такой способ даёт наиболее похожие на человеческие частоты n-gram.