grid = {'learning_rate': [0.03], # 0.005],
# 'score_function': ["Cosine", "L2", "NewtonL2"],
'depth': [6, 8, 10],
'l2_leaf_reg': [2, 5, 8],
# 'nan_mode': ["Min", "Max"],
# 'fold_len_multiplier': np.linspace(1.1, 3, 3),
'bagging_temperature': np.linspace(1, 3000, 3),
}
model = catboost.CatBoostClassifier(
bootstrap_type="Bayesian",
scale_pos_weight=en.scale_pos_weight,
loss_function = "Logloss",
# eval_metric="AUC:hints=skip_train~false",
# langevin=True,
# use_best_model=True,
iterations=1000,
od_type="Iter",
od_wait=30,
rsm=1,
# random_seed=100,
boosting_type='Ordered',
logging_level="Verbose",
train_dir="grid",
)
grid_search_result = model.grid_search(
grid,
X=train_pool,
stratified=True,
cv=3,
search_by_train_test_split=False,
plot=PLOT,
)
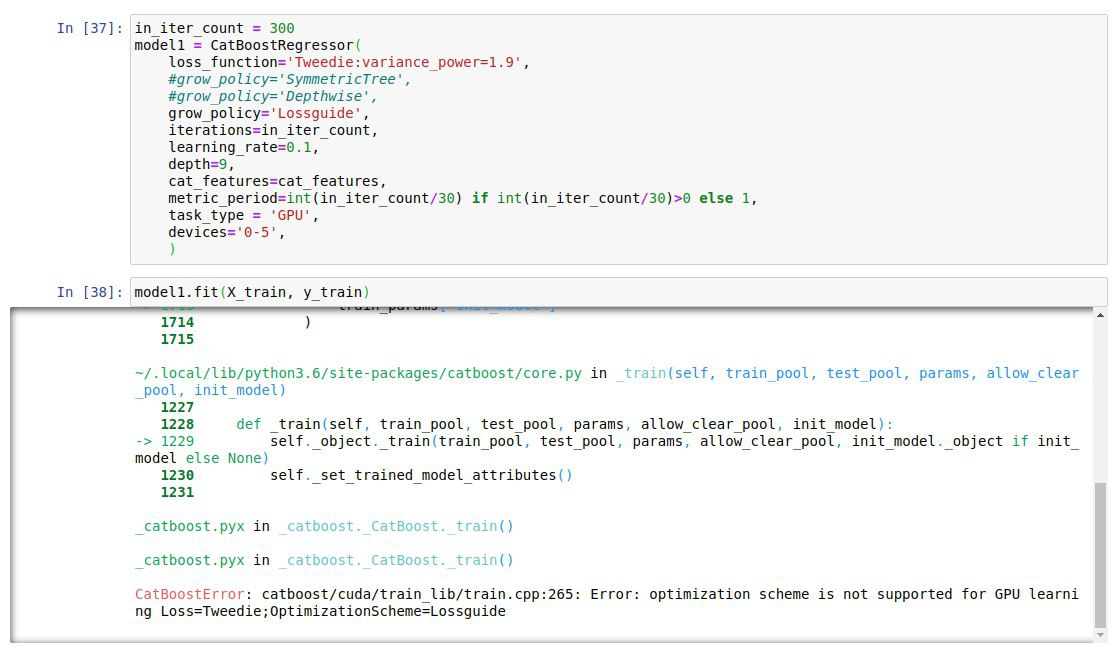
Похожий вопрос. Этот код нормально исполняется на GPU, но не удается получить выигрыша. Если выключить GPU или включить, время исполнения не меняется. Как бы разобраться, чтобы получить выигрыш? Пробовал на Виртуалной машине в Yandex Cloud, там могут ли быть настройки, которые исполняться коду позволяют, т.е. GPU нормально определяется, а на самом деле GPU не используется?