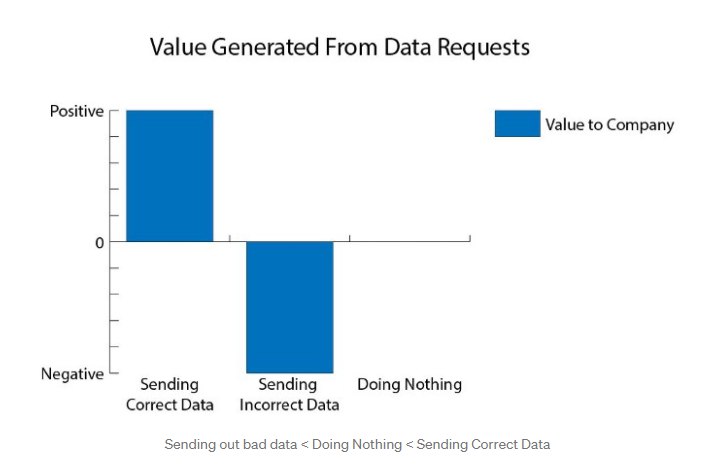
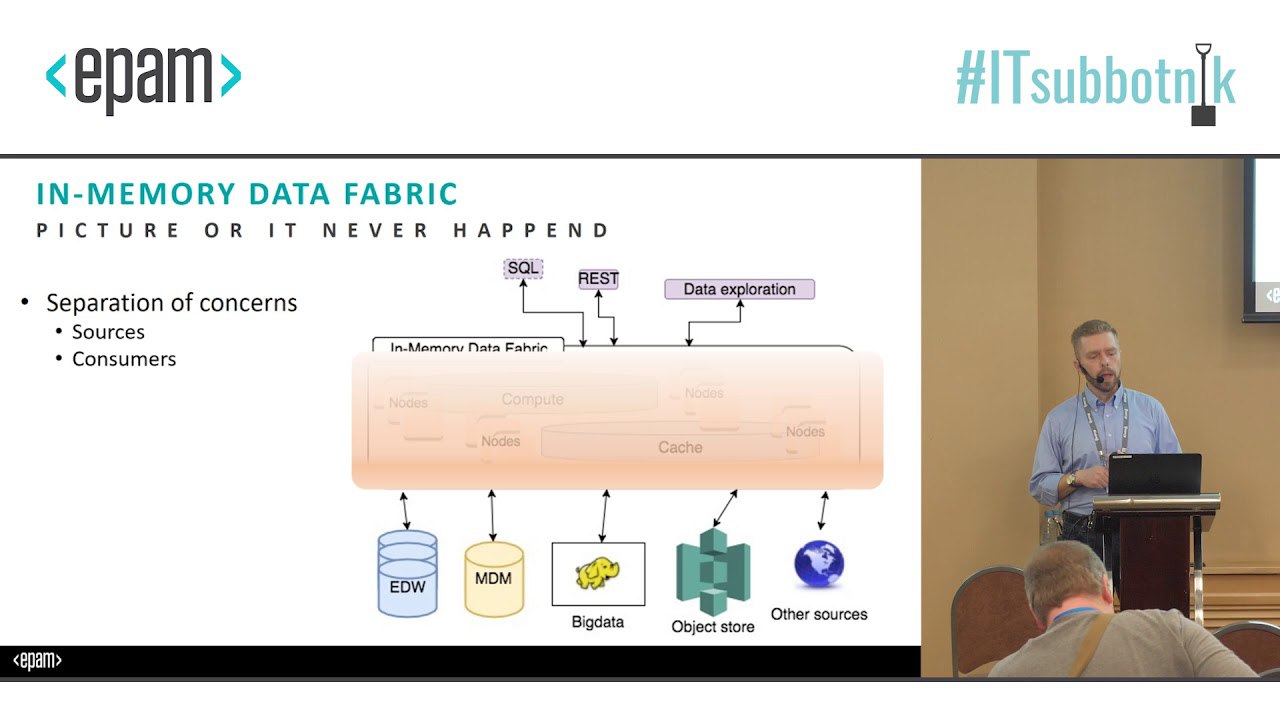
Интерсная заметка про data mesh, мне стало немного понятней, когд а на пальцах описали:
Force me to describe how a data mesh might actually work, and my immediate thought is something like Trino (née Presto): It’s a query wrapper that sits on top of a bunch of data sources.
This seems to be the community’s best guess for well. But as Ross Housewright points out, this is an uninspiring answer. If the data mesh works with any underlying data structure (e.g., it can sit on top of BigQuery, Oracle, S3, and every weird thing in between), it doesn’t integrate anything. It’s just a switchboard, routing queries to different destinations.
If the data mesh does requires data sources to be heavily standardized (e.g., each data source is a Snowflake database configured in a particular way), the data mesh doesn’t do anything. It’s just another layer of organization above the database schema. Presto, in fact, already does exactly this.
In both cases, the data mesh fails to help people consuming data—the people for whom all of this effort is supposedly for.
Вообще это из статьи про Data OS, где автор рассуждает о куче несвязанных инструментов, где есть vendor lock, и как не хватает операционной системы, как например, Андроид, где уживаются разные приложения.
Force me to describe how a data mesh might actually work, and my immediate thought is something like Trino (née Presto): It’s a query wrapper that sits on top of a bunch of data sources.
This seems to be the community’s best guess for well. But as Ross Housewright points out, this is an uninspiring answer. If the data mesh works with any underlying data structure (e.g., it can sit on top of BigQuery, Oracle, S3, and every weird thing in between), it doesn’t integrate anything. It’s just a switchboard, routing queries to different destinations.
If the data mesh does requires data sources to be heavily standardized (e.g., each data source is a Snowflake database configured in a particular way), the data mesh doesn’t do anything. It’s just another layer of organization above the database schema. Presto, in fact, already does exactly this.
In both cases, the data mesh fails to help people consuming data—the people for whom all of this effort is supposedly for.
Вообще это из статьи про Data OS, где автор рассуждает о куче несвязанных инструментов, где есть vendor lock, и как не хватает операционной системы, как например, Андроид, где уживаются разные приложения.