



Size: a a a
2021 September 06

2021 September 07

А что вы делали в 12 лет?!😎
У этой специализации очень высокий рейтинг на курсере, кто-нибудь пробовал? https://www.coursera.org/professional-certificates/google-it-automation#courses

Составил себе обязательный план, что нужно прочитать, прежде чем пушить повышение или использовать совет 4 из моей статьи про вредные советы:
1) Закончить книгу Game Analytics (а там 800 страниц)
2) Закончить книгу Learning Spark v2
3) Закончить Python Crash Course v2 книгу
4) Прочитать Designing Data Intense Applications
5) Прочитать Refactoring: Improving the Design of Existing Code
6) Прочитать Missing Readme (недавно обсуждали в канале)
7) Прочитать High Performance Spark
1) Закончить книгу Game Analytics (а там 800 страниц)
2) Закончить книгу Learning Spark v2
3) Закончить Python Crash Course v2 книгу
4) Прочитать Designing Data Intense Applications
5) Прочитать Refactoring: Improving the Design of Existing Code
6) Прочитать Missing Readme (недавно обсуждали в канале)
7) Прочитать High Performance Spark
Начинаем :
https://youtu.be/cq6dUisDeUU
https://youtu.be/cq6dUisDeUU

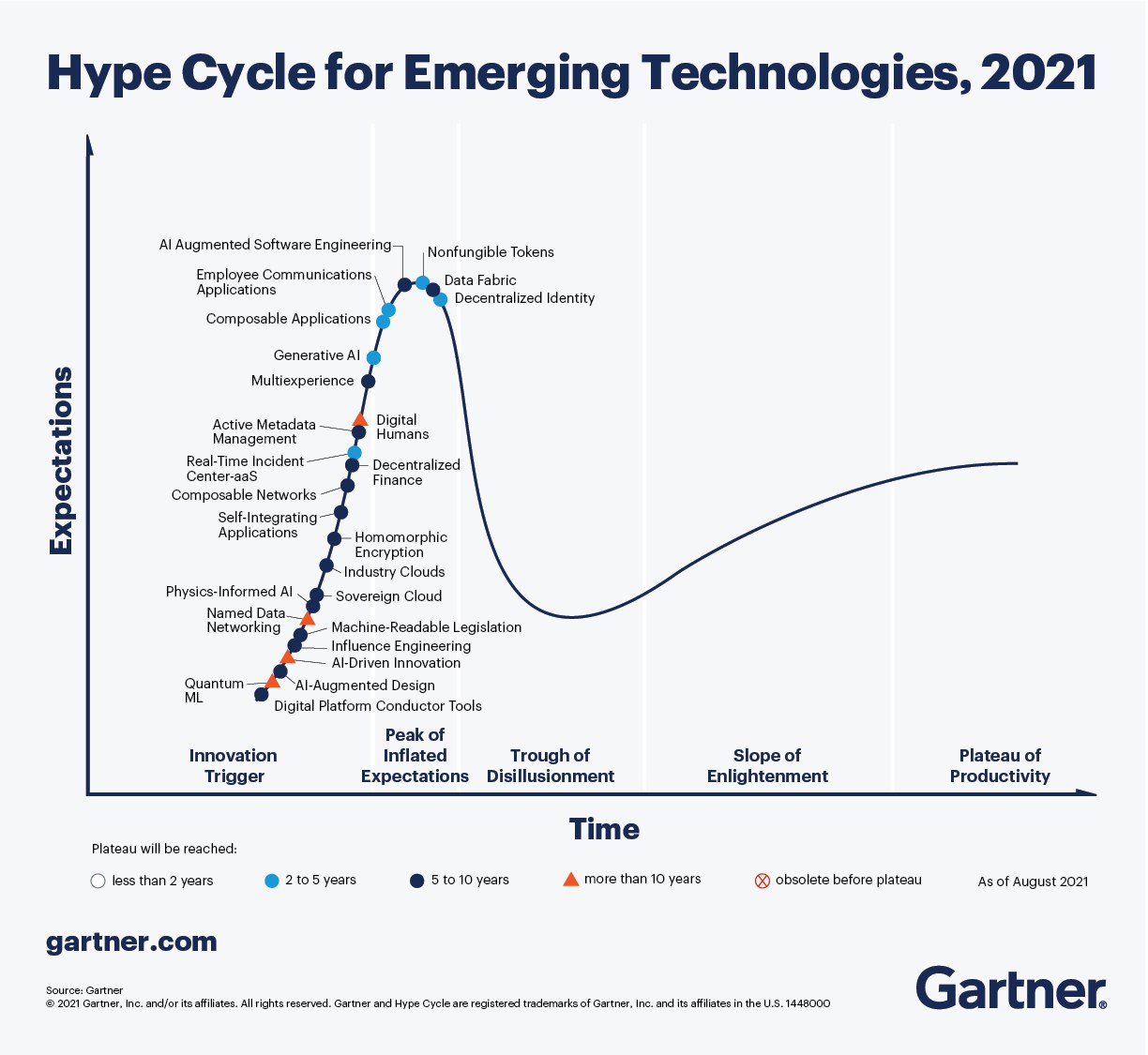
23 Августа Gartner опубликовал ежегодный отчет 2021 Emerging Technologies Hype Cycle.
https://www.gartner.com/smarterwithgartner/3-themes-surface-in-the-2021-hype-cycle-for-emerging-technologies/
Когда-то там была Big Data (аж в 2012 году, она поднималась на пик, а сейчас как excel, затерли до дыр). В это же время in-Memory аналитикс и Cloud Computing, уже скатились, а Predictive Analytics почти пропала с виду.
https://dzone.com/articles/big-data-trough
В 2013 году мы видим подъем Prescriptive Analytics - Prescriptive Analytics is a form of advanced analytics which examines data or content to answer the question “What should be done?” or “What can we do to make ___ happen?”, and is characterized by techniques such as graph analysis, simulation, complex event processing, neural networks, recommendation engines, heuristics, and machine learning.
В 2014 появилась Data Science, а в 2015 есть Machine Learning, который уже прошел пик и которого не было ранее.
В общем целый ребус, но довольно популярный!
https://www.gartner.com/smarterwithgartner/3-themes-surface-in-the-2021-hype-cycle-for-emerging-technologies/
Когда-то там была Big Data (аж в 2012 году, она поднималась на пик, а сейчас как excel, затерли до дыр). В это же время in-Memory аналитикс и Cloud Computing, уже скатились, а Predictive Analytics почти пропала с виду.
https://dzone.com/articles/big-data-trough
В 2013 году мы видим подъем Prescriptive Analytics - Prescriptive Analytics is a form of advanced analytics which examines data or content to answer the question “What should be done?” or “What can we do to make ___ happen?”, and is characterized by techniques such as graph analysis, simulation, complex event processing, neural networks, recommendation engines, heuristics, and machine learning.
В 2014 появилась Data Science, а в 2015 есть Machine Learning, который уже прошел пик и которого не было ранее.
В общем целый ребус, но довольно популярный!
Решил добавить определения из Gartner по нашей тематике. (Не наше там про data engineering).
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation. Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
Business analytics is comprised of solutions used to build analysis models and simulations to create scenarios, understand realities and predict future states. Business analytics includes data mining, predictive analytics, applied analytics and statistics, and is delivered as an application suitable for a business user. Business analytics is comprised of solutions used to build analysis models and simulations to create scenarios, understand realities and predict future states. Business analytics includes data mining, predictive analytics, applied analytics and statistics, and is delivered as an application suitable for a business user.
Business intelligence (BI) platforms enable enterprises to build BI applications by providing capabilities in three categories: analysis, such as online analytical processing (OLAP); information delivery, such as reports and dashboards; and platform integration, such as BI metadata management and a development environment.Business intelligence (BI) platforms enable enterprises to build BI applications by providing capabilities in three categories: analysis, such as online analytical processing (OLAP); information delivery, such as reports and dashboards; and platform integration, such as BI metadata management and a development environment.
Business intelligence (BI) services are offerings to design, develop and deploy enterprise processes and to integrate, support and manage the related technology applications and platforms. These include business and infrastructure applications for BI platforms, analytics needs and data warehousing infrastructure. Business intelligence (BI) services are offerings to design, develop and deploy enterprise processes and to integrate, support and manage the related technology applications and platforms. These include business and infrastructure applications for BI platforms, analytics needs and data warehousing infrastructure.
Predictive analytics describes any approach to data mining with four attributes:
1. An emphasis on prediction (rather than description, classification or clustering)
2. Rapid analysis measured in hours or days (rather than the stereotypical months of traditional data mining)
3. An emphasis on the business relevance of the resulting insights (no ivory tower analyses)
4. (increasingly) An emphasis on ease of use, thus making the tools accessible to business users.Predictive analytics describes any approach to data mining with four attributes:
1. An emphasis on prediction (rather than description, classification or clustering)
2. Rapid analysis measured in hours or days (rather than the stereotypical months of traditional data mining)
3. An emphasis on the business relevance of the resulting insights (no ivory tower analyses)
4. (increasingly) An emphasis on ease of use, thus making the tools accessible to business users.
Prescriptive Analytics is a form of advanced analytics that examines data or content to answer the question “What should be done?” or “What can we do to make ___ happen?”, and is characterized by techniques such as graph analysis, simulation, complex event processing, neural networks, recommendation engines, heuristics, and machine learning.Prescriptive Analytics is a form of advanced analytics that examines data or content to answer the question “What should be done?” or “What can we do to make ___ happen?”, and is characterized by techniques such as graph analysis, simulation, complex event processing, neural networks, recommendation engines, heuristics, and machine learning.
A data lake is a concept consisting of a collection of storage instances of various data assets. These assets are stored in a near-exact, or even exact, copy of the source format and are in addition to the originating data stores.data lake is a concept consisting of a collection of storage instances of various data assets. These assets are stored in a near-exact, or even exact, copy of the source format and are in addition to the originating data stores.
Data literacy is the ability to read, write and communicate data in context, with an understanding of the data sources and constructs, analytical methods and techniques applied, and the ability to describe the use case application and resulting business value or outcome.
Data literacy is the ability to read, write and communicate data in context, with an understanding of the data sources and constructs, analytical methods and techniques applied, and the ability to describe the use case application and resulting business value or outcome.
The discipline of data integration comprises the practices, architectural techniques and tools for achieving the consistent access and delivery of data across the spectrum of data subject areas and data structure types in the enterprise to meet the data consumption requirements of all applications and business processes.
data integration comprises the practices, architectural techniques and tools for achieving the consistent access and delivery of data across the spectrum of data subject areas and data structure types in the enterprise to meet the data consumption requirements of all applications and business processes.
A data warehouse is a storage architecture designed to hold data extracted from transaction systems, operational data stores and external sources. The warehouse then combines that data in an aggregate, summary form suitable for enterprisewide data analysis and reporting for predefined business needs.
data warehouse is a storage architecture designed to hold data extracted from transaction systems, operational data stores and external sources. The warehouse then combines that data in an aggregate, summary form suitable for enterprisewide data analysis and reporting for predefined business needs.
Обычно все sales презентации у вендоров начинаются с цитат из gartner...
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation. Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
Business analytics is comprised of solutions used to build analysis models and simulations to create scenarios, understand realities and predict future states. Business analytics includes data mining, predictive analytics, applied analytics and statistics, and is delivered as an application suitable for a business user. Business analytics is comprised of solutions used to build analysis models and simulations to create scenarios, understand realities and predict future states. Business analytics includes data mining, predictive analytics, applied analytics and statistics, and is delivered as an application suitable for a business user.
Business intelligence (BI) platforms enable enterprises to build BI applications by providing capabilities in three categories: analysis, such as online analytical processing (OLAP); information delivery, such as reports and dashboards; and platform integration, such as BI metadata management and a development environment.Business intelligence (BI) platforms enable enterprises to build BI applications by providing capabilities in three categories: analysis, such as online analytical processing (OLAP); information delivery, such as reports and dashboards; and platform integration, such as BI metadata management and a development environment.
Business intelligence (BI) services are offerings to design, develop and deploy enterprise processes and to integrate, support and manage the related technology applications and platforms. These include business and infrastructure applications for BI platforms, analytics needs and data warehousing infrastructure. Business intelligence (BI) services are offerings to design, develop and deploy enterprise processes and to integrate, support and manage the related technology applications and platforms. These include business and infrastructure applications for BI platforms, analytics needs and data warehousing infrastructure.
Predictive analytics describes any approach to data mining with four attributes:
1. An emphasis on prediction (rather than description, classification or clustering)
2. Rapid analysis measured in hours or days (rather than the stereotypical months of traditional data mining)
3. An emphasis on the business relevance of the resulting insights (no ivory tower analyses)
4. (increasingly) An emphasis on ease of use, thus making the tools accessible to business users.Predictive analytics describes any approach to data mining with four attributes:
1. An emphasis on prediction (rather than description, classification or clustering)
2. Rapid analysis measured in hours or days (rather than the stereotypical months of traditional data mining)
3. An emphasis on the business relevance of the resulting insights (no ivory tower analyses)
4. (increasingly) An emphasis on ease of use, thus making the tools accessible to business users.
Prescriptive Analytics is a form of advanced analytics that examines data or content to answer the question “What should be done?” or “What can we do to make ___ happen?”, and is characterized by techniques such as graph analysis, simulation, complex event processing, neural networks, recommendation engines, heuristics, and machine learning.Prescriptive Analytics is a form of advanced analytics that examines data or content to answer the question “What should be done?” or “What can we do to make ___ happen?”, and is characterized by techniques such as graph analysis, simulation, complex event processing, neural networks, recommendation engines, heuristics, and machine learning.
A data lake is a concept consisting of a collection of storage instances of various data assets. These assets are stored in a near-exact, or even exact, copy of the source format and are in addition to the originating data stores.data lake is a concept consisting of a collection of storage instances of various data assets. These assets are stored in a near-exact, or even exact, copy of the source format and are in addition to the originating data stores.
Data literacy is the ability to read, write and communicate data in context, with an understanding of the data sources and constructs, analytical methods and techniques applied, and the ability to describe the use case application and resulting business value or outcome.
Data literacy is the ability to read, write and communicate data in context, with an understanding of the data sources and constructs, analytical methods and techniques applied, and the ability to describe the use case application and resulting business value or outcome.
The discipline of data integration comprises the practices, architectural techniques and tools for achieving the consistent access and delivery of data across the spectrum of data subject areas and data structure types in the enterprise to meet the data consumption requirements of all applications and business processes.
data integration comprises the practices, architectural techniques and tools for achieving the consistent access and delivery of data across the spectrum of data subject areas and data structure types in the enterprise to meet the data consumption requirements of all applications and business processes.
A data warehouse is a storage architecture designed to hold data extracted from transaction systems, operational data stores and external sources. The warehouse then combines that data in an aggregate, summary form suitable for enterprisewide data analysis and reporting for predefined business needs.
data warehouse is a storage architecture designed to hold data extracted from transaction systems, operational data stores and external sources. The warehouse then combines that data in an aggregate, summary form suitable for enterprisewide data analysis and reporting for predefined business needs.
Обычно все sales презентации у вендоров начинаются с цитат из gartner...
2021 September 08
Переслано от Паша Финкельштейн...
Выпустил августовский выпуск https://blog.jetbrains.com/big-data-tools/2021/09/06/data-engineering-annotated-monthly-august-2021/

Сегодня в linkedin увидел картинку бывшего коллеги по Терадате с футболкой:
My wife found my Teradata-Sber T-Shirt. About 10 years ago it was the project. Such projects you need to have experience. "Big deal" for Teradata Russia and lovely experience at my Taradata CPC award in Sydney afterwards!
Time flies so fast. T-shirt remains!
Это был проект Кредиты Юридических Лиц - Teradata + SAP BusinessObjects. И я сразу вспомнил несколько забавных историй того времени, которых мне не хватает в Северной Америки, коллеги у меня местные, и чувство юмора у нас не совпадает, так что я уже привык быть скучным и серьезным на работе.
Например, когда я только присоединился к проекту, мы работали в бывшем детском садике, переоборудованом под офис сбера (такое советское 2х этажное здание с охранниками на входе, а раньше и телефонов не было повтыкать, в общем они там скучали). В нашей комнате был чайник и печеньки.
Главный challenge это стулья. Стульев (нормальных) меньше, чем людей, поэтому шла борьба за них. Как-то я пошутил не колле, что моя коллега занимается йогой, вместо работы, и никто не понял, что я пошутил😋Она в ответ, сказала, что мы играем в Counter Strike в рабочее время, и она не шутила😣 В этом садики мы (консультанты) часто жили своей жизнью, и было весело.
Если посмотреть на карьеру, то в начале карьеры (мой 2й год) было намного интересней, так как передомной был океан и много неизведанного. Напоминает мне, когда я игра первый раз в Fallout 2, это такая RPG игра. Там была карта и можно ходить, открывать новые города, находить оружие и броню. И это было очень интересно, потому что игра - это как неизведанный мир. Так же и карьера в начале.
А теперь, уже все понятно +/-, тратишь силы на споры про 2% повышение зарплаты и понимаешь, что вся "карта" открыта. 🤔
Зато, когда мы закончили проект, возможно опоздав на годик-другой по срокам, мы должны были отметить это мероприятие в пивнухе. Так сложилось, что наш менеджер попросил помочь выбрать место. Уж я-то знал все места в Москве😎 Я ему предложил Аист (это такой ресторан в Москве, очень дорогой на Патриарших, рядом всегда были бентли, феррари и другие чудеса техники). Мы зашли на сайт, и там почти ничего не было, так небольшое простенькое меню, цены не очень большие (скорей всего за 100г). И столик нашелся на 25-30 человек.
Мне кажется, для одних это место было открытие, а другие не заметили разницы. Пошли заказы на стейки, лобстеры и дорогие вина (были там ценители коллеги). Было так весело и вкусно, что народ, стал заказывать по 2му кругу горячие блюда. Кто-то выпил так много, что прили к фешенебельной раковине в фешенебельном туалете🤢.
Принесли счет, сумма была огого, явно превышала положенный бюджет на 30 человек раз в 5-6. Потом оказалось, что это чек не проходит в expense систему, и никто не может сделать approve, этот чек дошел до HQ Teradata. Такой вод проектик))
Как же не хватает таких историй🥳
My wife found my Teradata-Sber T-Shirt. About 10 years ago it was the project. Such projects you need to have experience. "Big deal" for Teradata Russia and lovely experience at my Taradata CPC award in Sydney afterwards!
Time flies so fast. T-shirt remains!
Это был проект Кредиты Юридических Лиц - Teradata + SAP BusinessObjects. И я сразу вспомнил несколько забавных историй того времени, которых мне не хватает в Северной Америки, коллеги у меня местные, и чувство юмора у нас не совпадает, так что я уже привык быть скучным и серьезным на работе.
Например, когда я только присоединился к проекту, мы работали в бывшем детском садике, переоборудованом под офис сбера (такое советское 2х этажное здание с охранниками на входе, а раньше и телефонов не было повтыкать, в общем они там скучали). В нашей комнате был чайник и печеньки.
Главный challenge это стулья. Стульев (нормальных) меньше, чем людей, поэтому шла борьба за них. Как-то я пошутил не колле, что моя коллега занимается йогой, вместо работы, и никто не понял, что я пошутил😋Она в ответ, сказала, что мы играем в Counter Strike в рабочее время, и она не шутила😣 В этом садики мы (консультанты) часто жили своей жизнью, и было весело.
Если посмотреть на карьеру, то в начале карьеры (мой 2й год) было намного интересней, так как передомной был океан и много неизведанного. Напоминает мне, когда я игра первый раз в Fallout 2, это такая RPG игра. Там была карта и можно ходить, открывать новые города, находить оружие и броню. И это было очень интересно, потому что игра - это как неизведанный мир. Так же и карьера в начале.
А теперь, уже все понятно +/-, тратишь силы на споры про 2% повышение зарплаты и понимаешь, что вся "карта" открыта. 🤔
Зато, когда мы закончили проект, возможно опоздав на годик-другой по срокам, мы должны были отметить это мероприятие в пивнухе. Так сложилось, что наш менеджер попросил помочь выбрать место. Уж я-то знал все места в Москве😎 Я ему предложил Аист (это такой ресторан в Москве, очень дорогой на Патриарших, рядом всегда были бентли, феррари и другие чудеса техники). Мы зашли на сайт, и там почти ничего не было, так небольшое простенькое меню, цены не очень большие (скорей всего за 100г). И столик нашелся на 25-30 человек.
Мне кажется, для одних это место было открытие, а другие не заметили разницы. Пошли заказы на стейки, лобстеры и дорогие вина (были там ценители коллеги). Было так весело и вкусно, что народ, стал заказывать по 2му кругу горячие блюда. Кто-то выпил так много, что прили к фешенебельной раковине в фешенебельном туалете🤢.
Принесли счет, сумма была огого, явно превышала положенный бюджет на 30 человек раз в 5-6. Потом оказалось, что это чек не проходит в expense систему, и никто не может сделать approve, этот чек дошел до HQ Teradata. Такой вод проектик))
Как же не хватает таких историй🥳

#dataquality
Хороший пост из 2х частей про роль Program Manager от Microsoft:
In this two-part article series, author describe the unique responsibilities of a program manager (PM) on an ML team, the value that a PM adds, and how to be successful in this new role.
ML program management at scale (Part 1 of 2)
ML program management at scale (Part 2 of 2)
In this two-part article series, author describe the unique responsibilities of a program manager (PM) on an ML team, the value that a PM adds, and how to be successful in this new role.
ML program management at scale (Part 1 of 2)
ML program management at scale (Part 2 of 2)

В общем качество данных это не шутка! Поэтому у бизнеса и у нас должны быть высокие ожидание про качества данных, что есть Great Expectations!
А еще, неплохо бы не изобретать велосипед, а использовать готовый framework для обеспечения качества данных, можно например использовать Deequ для Spark (Scala или Pyspark), а можно посмотреть на новый популярный инструмент, который работает без спарка - Great Expectations.
Вот вам аж целых 3 поста про них!
https://greatexpectations.io/blog/maximizing-productivity-of-analytics-teams-pt1/
https://greatexpectations.io/blog/maximizing-productivity-of-analytics-teams-pt2/
https://greatexpectations.io/blog/maximizing-productivity-of-analytics-teams-pt3/
Great Expectations writes a three-part series on maximizing the productivity of the analytics team, focusing on the debugability of the dashboards, reducing the technical debt on the data pipeline, and the role of Great Expectations in the data engineering process.
А еще, неплохо бы не изобретать велосипед, а использовать готовый framework для обеспечения качества данных, можно например использовать Deequ для Spark (Scala или Pyspark), а можно посмотреть на новый популярный инструмент, который работает без спарка - Great Expectations.
Вот вам аж целых 3 поста про них!
https://greatexpectations.io/blog/maximizing-productivity-of-analytics-teams-pt1/
https://greatexpectations.io/blog/maximizing-productivity-of-analytics-teams-pt2/
https://greatexpectations.io/blog/maximizing-productivity-of-analytics-teams-pt3/
Great Expectations writes a three-part series on maximizing the productivity of the analytics team, focusing on the debugability of the dashboards, reducing the technical debt on the data pipeline, and the role of Great Expectations in the data engineering process.
Что может быть общего подхода по моделированию данных Data Vault и Python? Оказывается есть - diepvries is the name of a Python library. It automates the data loading process for Data Vault and avoids the maintenance of repetitive SQL queries for ETL jobs.diepvries is the name of a Python library. It automates the data loading process for Data Vault and avoids the maintenance of repetitive SQL queries for ETL jobs.
https://blog.picnic.nl/releasing-diepvries-a-data-vault-framework-for-python-3f01a5d46f84
https://blog.picnic.nl/releasing-diepvries-a-data-vault-framework-for-python-3f01a5d46f84

Через 40 минут начинаем:
https://youtu.be/-ZgzpQXsxi0
https://youtu.be/-ZgzpQXsxi0

2021 September 09
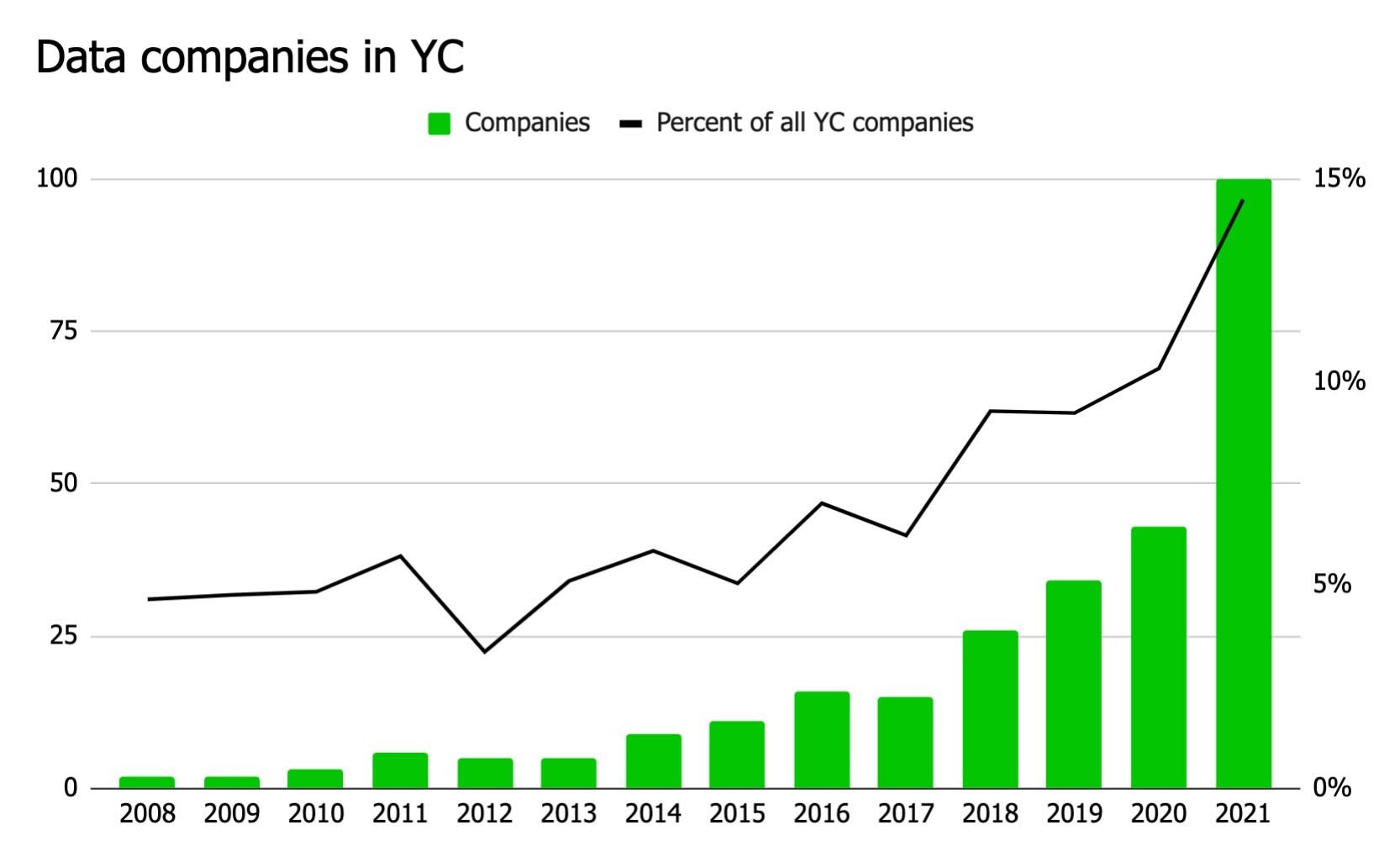
"As data people, we definitely have a lot of tools. In 2017, Y Combinator—an incubator of both startups and the Silicon Valley zeitgeist—funded 15 analytics, data engineering, and AI and ML companies. In 2021, they funded 100.² It’s impossible to make sense of this many tools, much less manage even a fraction of them in a single stack."
Все так - кол-во инструментов (tools) для работы с данными растет в геометрической прогрессии. Свеже испеченным дата профессионалом будет очень сложно понять разницу в инструментах, их назначении и различии. 🙄
Новички, как собираетесь решать проблему? Всего не перепробовать и не выучить, и концов не найти. Как в песне:
Data может, data может
Все что угодно....
Все так - кол-во инструментов (tools) для работы с данными растет в геометрической прогрессии. Свеже испеченным дата профессионалом будет очень сложно понять разницу в инструментах, их назначении и различии. 🙄
Новички, как собираетесь решать проблему? Всего не перепробовать и не выучить, и концов не найти. Как в песне:
Data может, data может
Все что угодно....
Специально нашел soundtracks Tableau Conference 2019, раз уж про песни заговорил, https://open.spotify.com/playlist/5mohLACrVKdX6zxCfagScw

Все помнят что сегодня в 20:00 по мск вебинар :
https://youtu.be/DmqGfdQWP94
https://youtu.be/DmqGfdQWP94

Через пол часа начинаем:
https://youtu.be/DmqGfdQWP94
https://youtu.be/DmqGfdQWP94
Через 2 минуты начинаем кстати гоу в зум кому в кайф:
Подключиться к конференции Zoom
https://us02web.zoom.us/j/89848486805?pwd=THg0UHRGdTBxZml6ZjNtZnF3VFVCdz09
Идентификатор конференции: 898 4848 6805
Код доступа: 996986
Одно касание на мобильном телефоне
+13017158592,,89848486805#,,,,*996986# Соединенные Штаты Америки (Washington DC)
+13126266799,,89848486805#,,,,*996986# Соединенные Штаты Америки (Chicago)
Набор в зависимости от местоположения
+1 301 715 8592 Соединенные Штаты Америки (Washington DC)
+1 312 626 6799 Соединенные Штаты Америки (Chicago)
+1 346 248 7799 Соединенные Штаты Америки (Houston)
+1 669 900 6833 Соединенные Штаты Америки (San Jose)
+1 929 205 6099 Соединенные Штаты Америки (New York)
+1 253 215 8782 Соединенные Штаты Америки (Tacoma)
Идентификатор конференции: 898 4848 6805
Код доступа: 996986
Найдите свой местный номер: https://us02web.zoom.us/u/kd2F7vdGeS
Подключиться к конференции Zoom
https://us02web.zoom.us/j/89848486805?pwd=THg0UHRGdTBxZml6ZjNtZnF3VFVCdz09
Идентификатор конференции: 898 4848 6805
Код доступа: 996986
Одно касание на мобильном телефоне
+13017158592,,89848486805#,,,,*996986# Соединенные Штаты Америки (Washington DC)
+13126266799,,89848486805#,,,,*996986# Соединенные Штаты Америки (Chicago)
Набор в зависимости от местоположения
+1 301 715 8592 Соединенные Штаты Америки (Washington DC)
+1 312 626 6799 Соединенные Штаты Америки (Chicago)
+1 346 248 7799 Соединенные Штаты Америки (Houston)
+1 669 900 6833 Соединенные Штаты Америки (San Jose)
+1 929 205 6099 Соединенные Штаты Америки (New York)
+1 253 215 8782 Соединенные Штаты Америки (Tacoma)
Идентификатор конференции: 898 4848 6805
Код доступа: 996986
Найдите свой местный номер: https://us02web.zoom.us/u/kd2F7vdGeS