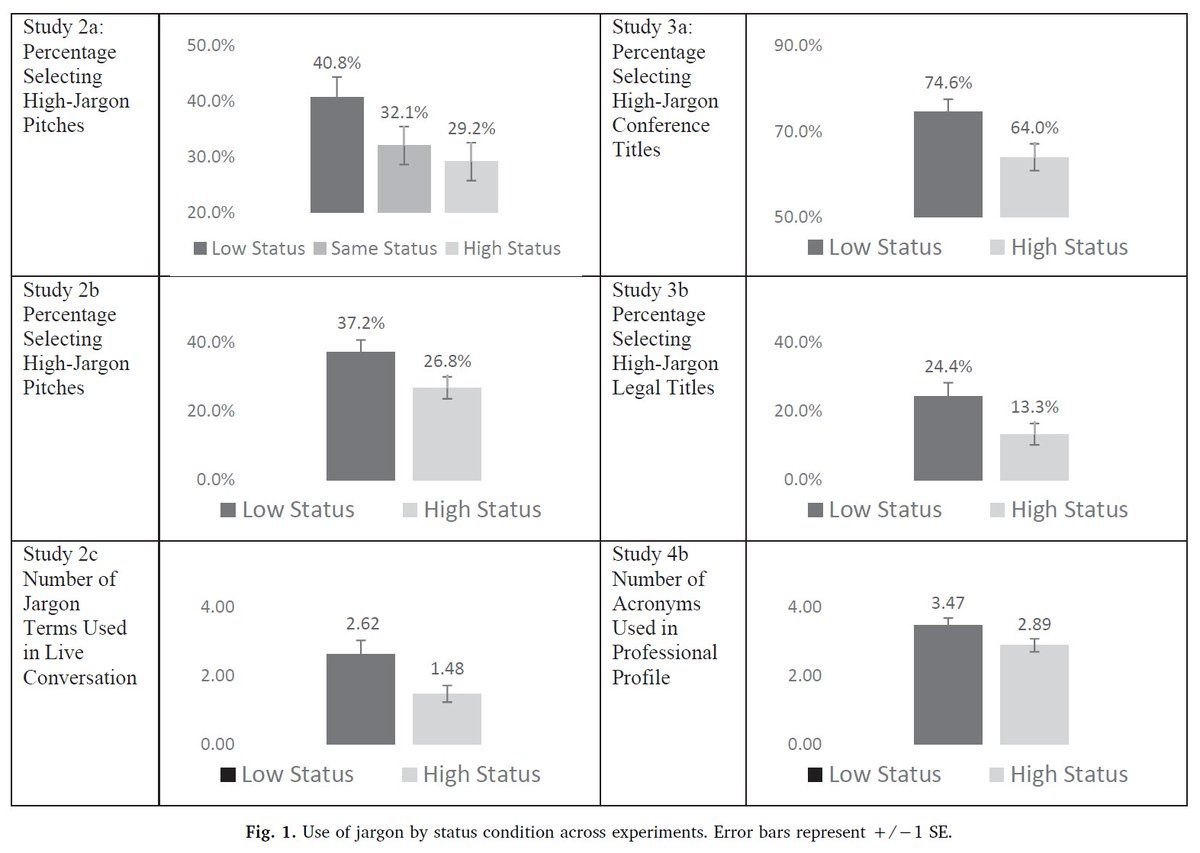
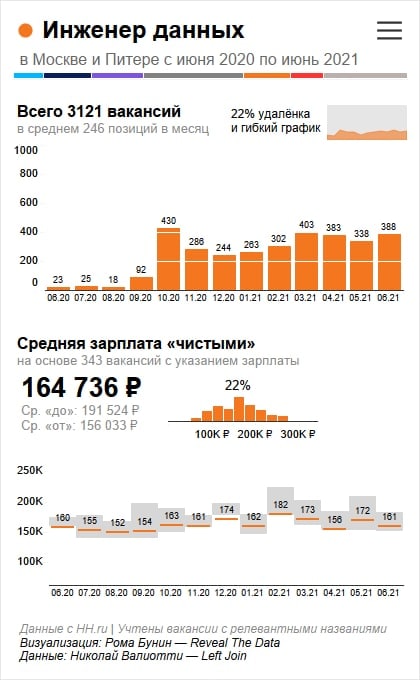
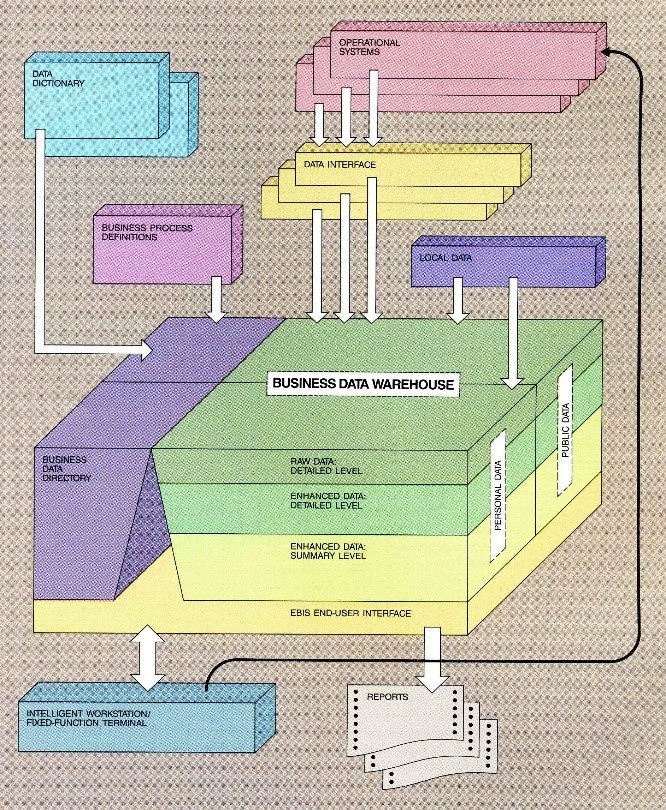
6 сентября стартует новый поток курса о данных в энтерпрайзе. Это первая подобная программа в России. Ее разработали создатели MDM- и CDI-решений из компании HFLabs.
🧑💻 Для кого
Подойдет всем, кто работает или хочет работать с клиентскими данными в крупной компании.
Специальность не имеет значения: полезно аналитикам, архитекторам, тестировщикам, инженерам по данным.
📚 Программа
Пять дней, пять преподавателей, пять модулей:
1. Предпосылки создания MDM-системы. Проектирование модели данных.
2. Построение MDM-системы: структура и правила работы с данными.
3. Добавление новых источников в MDM-систему.
4. Получение данных из эталонной клиентской базы. Обратное распространение.
5. Управление качеством данных в MDM-системе.
🧙♂️ Преподаватели
Эти специалисты работают с клиентскими данными в ВТБ, «Открытии», «Росгосстрахе», МТС. Каждый «закрыл» десяток проектов для крупного бизнеса.
🏃♀️ Студенты уже регистрируются
Мест всего 16, разбирают быстро. Лучше не медлить.
Узнать больше https://bit.ly/3moXQfe
PS Это #реклама, которая поддержала фонд #vsevsevmeste#реклама, которая поддержала фонд #vsevsevmeste
🧑💻 Для кого
Подойдет всем, кто работает или хочет работать с клиентскими данными в крупной компании.
Специальность не имеет значения: полезно аналитикам, архитекторам, тестировщикам, инженерам по данным.
📚 Программа
Пять дней, пять преподавателей, пять модулей:
1. Предпосылки создания MDM-системы. Проектирование модели данных.
2. Построение MDM-системы: структура и правила работы с данными.
3. Добавление новых источников в MDM-систему.
4. Получение данных из эталонной клиентской базы. Обратное распространение.
5. Управление качеством данных в MDM-системе.
🧙♂️ Преподаватели
Эти специалисты работают с клиентскими данными в ВТБ, «Открытии», «Росгосстрахе», МТС. Каждый «закрыл» десяток проектов для крупного бизнеса.
🏃♀️ Студенты уже регистрируются
Мест всего 16, разбирают быстро. Лучше не медлить.
Узнать больше https://bit.ly/3moXQfe
PS Это #реклама, которая поддержала фонд #vsevsevmeste#реклама, которая поддержала фонд #vsevsevmeste