



ЕТ
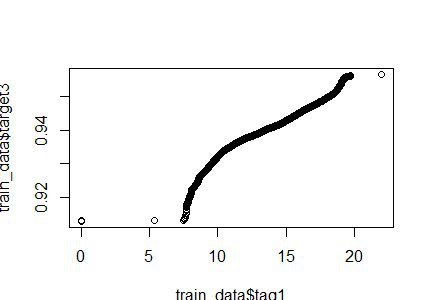
Друзья вот такой график, мне кажется что сюда отлична подошла бы сигмоида для предсказания, и я погуглил и что-то и не нашел ничего, можете подсказать как в R использовать разные функции для предсказания, числовых значений
Можно ещё ввести спрямляющие пространства.

