



Size: a a a
2021 December 22

2021 December 23
Небольшое вводное видео к модулю 7 про Apache Spark. В этом видео получилось больше информации про Whistler, BC, чем про сам спарк:)
PS опечатка на скрине, должно быть 7😋
PS опечатка на скрине, должно быть 7😋

Выходит новая книга Data Engineering with AWS, автор книги является Senior Solution Architect в AWS.
Book Description
Knowing how to architect and implement complex data pipelines is a highly sought-after skill. Data engineers are responsible for building these pipelines that ingest, transform, and join raw datasets - creating new value from the data in the process.
Amazon Web Services (AWS) offers a range of tools to simplify a data engineer's job, making it the preferred platform for performing data engineering tasks.
This book will take you through the services and the skills you need to architect and implement data pipelines on AWS. You'll begin by reviewing important data engineering concepts and some of the core AWS services that form a part of the data engineer's toolkit. You'll then architect a data pipeline, review raw data sources, transform the data, and learn how the transformed data is used by various data consumers. The book also teaches you about populating data marts and data warehouses along with how a data lakehouse fits into the picture. Later, you'll be introduced to AWS tools for analyzing data, including those for ad-hoc SQL queries and creating visualizations. In the final chapters, you'll understand how the power of machine learning and artificial intelligence can be used to draw new insights from data.
By the end of this AWS book, you'll be able to carry out data engineering tasks and implement a data pipeline on AWS independently.
What you will learn
-Understand data engineering concepts and emerging technologies
-Ingest streaming data with Amazon Kinesis Data Firehose
Optimize, denormalize, and join datasets with AWS Glue Studio
-Use Amazon S3 events to trigger a Lambda process to transform a file
-Run complex SQL queries on data lake data using Amazon Athena
-Load data into a Redshift data warehouse and run queries
-Create a visualization of your data using Amazon QuickSight
-Extract sentiment data from a dataset using Amazon
Table of Contents
- An Introduction to Data Engineering
- Data Management Architectures for Analytics
- The AWS Data Engineer's Toolkit
- Data Cataloging, Security and Governance
- Architecting Data Engineering Pipelines
- Ingesting Batch and Streaming Data
- Transforming Data to Optimize for Analytics
- Identifying and Enabling Data Consumers
- Loading Data into a Data Mart
- Orchestrating the Data Pipeline
- Ad Hoc Queries with Amazon Athena
- Visualizing Data with Amazon QuickSight
- Enabling Artificial Intelligence and Machine LearningBook Description
Knowing how to architect and implement complex data pipelines is a highly sought-after skill. Data engineers are responsible for building these pipelines that ingest, transform, and join raw datasets - creating new value from the data in the process.
Amazon Web Services (AWS) offers a range of tools to simplify a data engineer's job, making it the preferred platform for performing data engineering tasks.
This book will take you through the services and the skills you need to architect and implement data pipelines on AWS. You'll begin by reviewing important data engineering concepts and some of the core AWS services that form a part of the data engineer's toolkit. You'll then architect a data pipeline, review raw data sources, transform the data, and learn how the transformed data is used by various data consumers. The book also teaches you about populating data marts and data warehouses along with how a data lakehouse fits into the picture. Later, you'll be introduced to AWS tools for analyzing data, including those for ad-hoc SQL queries and creating visualizations. In the final chapters, you'll understand how the power of machine learning and artificial intelligence can be used to draw new insights from data.
By the end of this AWS book, you'll be able to carry out data engineering tasks and implement a data pipeline on AWS independently.
What you will learn
-Understand data engineering concepts and emerging technologies
-Ingest streaming data with Amazon Kinesis Data Firehose
Optimize, denormalize, and join datasets with AWS Glue Studio
-Use Amazon S3 events to trigger a Lambda process to transform a file
-Run complex SQL queries on data lake data using Amazon Athena
-Load data into a Redshift data warehouse and run queries
-Create a visualization of your data using Amazon QuickSight
-Extract sentiment data from a dataset using Amazon
Table of Contents
- An Introduction to Data Engineering
- Data Management Architectures for Analytics
- The AWS Data Engineer's Toolkit
- Data Cataloging, Security and Governance
- Architecting Data Engineering Pipelines
- Ingesting Batch and Streaming Data
- Transforming Data to Optimize for Analytics
- Identifying and Enabling Data Consumers
- Loading Data into a Data Mart
- Orchestrating the Data Pipeline
- Ad Hoc Queries with Amazon Athena
- Visualizing Data with Amazon QuickSight
- Enabling Artificial Intelligence and Machine Learning
Для тех кому предстоит работать в AWS книга будет очень кстати.
Book Description
Knowing how to architect and implement complex data pipelines is a highly sought-after skill. Data engineers are responsible for building these pipelines that ingest, transform, and join raw datasets - creating new value from the data in the process.
Amazon Web Services (AWS) offers a range of tools to simplify a data engineer's job, making it the preferred platform for performing data engineering tasks.
This book will take you through the services and the skills you need to architect and implement data pipelines on AWS. You'll begin by reviewing important data engineering concepts and some of the core AWS services that form a part of the data engineer's toolkit. You'll then architect a data pipeline, review raw data sources, transform the data, and learn how the transformed data is used by various data consumers. The book also teaches you about populating data marts and data warehouses along with how a data lakehouse fits into the picture. Later, you'll be introduced to AWS tools for analyzing data, including those for ad-hoc SQL queries and creating visualizations. In the final chapters, you'll understand how the power of machine learning and artificial intelligence can be used to draw new insights from data.
By the end of this AWS book, you'll be able to carry out data engineering tasks and implement a data pipeline on AWS independently.
What you will learn
-Understand data engineering concepts and emerging technologies
-Ingest streaming data with Amazon Kinesis Data Firehose
Optimize, denormalize, and join datasets with AWS Glue Studio
-Use Amazon S3 events to trigger a Lambda process to transform a file
-Run complex SQL queries on data lake data using Amazon Athena
-Load data into a Redshift data warehouse and run queries
-Create a visualization of your data using Amazon QuickSight
-Extract sentiment data from a dataset using Amazon
Table of Contents
- An Introduction to Data Engineering
- Data Management Architectures for Analytics
- The AWS Data Engineer's Toolkit
- Data Cataloging, Security and Governance
- Architecting Data Engineering Pipelines
- Ingesting Batch and Streaming Data
- Transforming Data to Optimize for Analytics
- Identifying and Enabling Data Consumers
- Loading Data into a Data Mart
- Orchestrating the Data Pipeline
- Ad Hoc Queries with Amazon Athena
- Visualizing Data with Amazon QuickSight
- Enabling Artificial Intelligence and Machine LearningBook Description
Knowing how to architect and implement complex data pipelines is a highly sought-after skill. Data engineers are responsible for building these pipelines that ingest, transform, and join raw datasets - creating new value from the data in the process.
Amazon Web Services (AWS) offers a range of tools to simplify a data engineer's job, making it the preferred platform for performing data engineering tasks.
This book will take you through the services and the skills you need to architect and implement data pipelines on AWS. You'll begin by reviewing important data engineering concepts and some of the core AWS services that form a part of the data engineer's toolkit. You'll then architect a data pipeline, review raw data sources, transform the data, and learn how the transformed data is used by various data consumers. The book also teaches you about populating data marts and data warehouses along with how a data lakehouse fits into the picture. Later, you'll be introduced to AWS tools for analyzing data, including those for ad-hoc SQL queries and creating visualizations. In the final chapters, you'll understand how the power of machine learning and artificial intelligence can be used to draw new insights from data.
By the end of this AWS book, you'll be able to carry out data engineering tasks and implement a data pipeline on AWS independently.
What you will learn
-Understand data engineering concepts and emerging technologies
-Ingest streaming data with Amazon Kinesis Data Firehose
Optimize, denormalize, and join datasets with AWS Glue Studio
-Use Amazon S3 events to trigger a Lambda process to transform a file
-Run complex SQL queries on data lake data using Amazon Athena
-Load data into a Redshift data warehouse and run queries
-Create a visualization of your data using Amazon QuickSight
-Extract sentiment data from a dataset using Amazon
Table of Contents
- An Introduction to Data Engineering
- Data Management Architectures for Analytics
- The AWS Data Engineer's Toolkit
- Data Cataloging, Security and Governance
- Architecting Data Engineering Pipelines
- Ingesting Batch and Streaming Data
- Transforming Data to Optimize for Analytics
- Identifying and Enabling Data Consumers
- Loading Data into a Data Mart
- Orchestrating the Data Pipeline
- Ad Hoc Queries with Amazon Athena
- Visualizing Data with Amazon QuickSight
- Enabling Artificial Intelligence and Machine Learning
Для тех кому предстоит работать в AWS книга будет очень кстати.
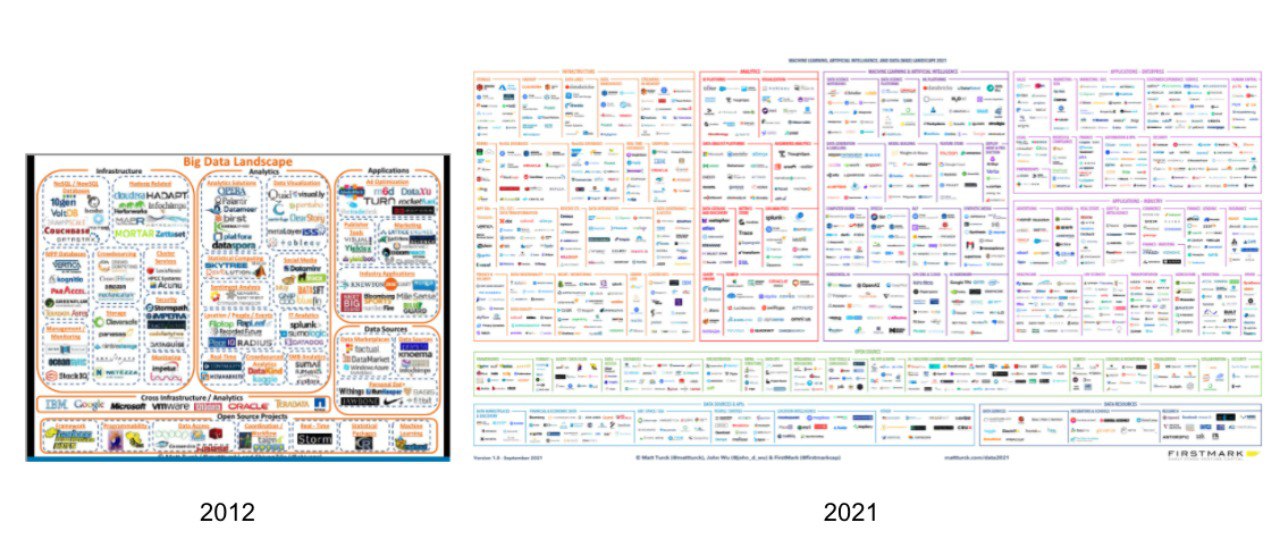
В плохом качестве картинка (можно найти по отдельности в хорошем), но передает всю боль индустрии, когда для одной задачи есть сотня тулов, и какой же выбрать🤪
Jason Brownlee states that “feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data”
2021 December 24

Слышали ли вы про MapReduce? Чаще всего это слово использует при упоминании Hadoop.
SeeMTo - новый канал о рациональности, аналитических инструментах и многом другом. Материалы публикуются на основе исследований, кейсов и мнения практикующего аналитика.
В одном из последних постов обзор «Рациональность: от ИИ до зомби» Юдковского. Автор привел подборку практических инструментов из книги.
На английском: seemto.blog.
PS Пост поддержал приют для собак в Ногинске.
В одном из последних постов обзор «Рациональность: от ИИ до зомби» Юдковского. Автор привел подборку практических инструментов из книги.
На английском: seemto.blog.
PS Пост поддержал приют для собак в Ногинске.
Для сравнения цен. Модуль 5 на data learn у нас был про облачные вычисления - совершенно бесплатно. А вот его цена в местном университете 700$. Так что пройдя модуль 5 вы сэкономите приличную сумму=)
Еще из интересно - университет заключил партнерство с Microsoft, и теперь мне нужно выкинуть все про AWS из курса😅
Еще из интересно - университет заключил партнерство с Microsoft, и теперь мне нужно выкинуть все про AWS из курса😅

2021 December 25
What to Look for in a Great Engineering Leader
the most important trait of an engineering leader is that they must be biased to say “yes”, but willing to say “no”
the most important trait of an engineering leader is that they must be biased to say “yes”, but willing to say “no”

Где-то в комментариях проскакивала информация о замечательном курсе - Distributed Systems in One Lesson. Я собрался силами и прошел его, правда со всеми домашними делами получилось 8 часов, вместо 4х обещанных.
На уроке были рассмотрены базовые вещи для distributed systems и их описание.
В целом курс понравился, несмотря на то, что он 2015 года. Узнал что-то нововое. Наример, не существует понятия "сейчас" и на самом деле все эти привычные вещи systime, now() - очень относительные - There is No Now (Problems with simultaneity in distributed systems)
Его одного конечно не достаточно, надо еще и книжку читать про Designing Data Intensive Application (кстати есть на русском). А еще лучше внедрять решение.
Использование облачных технологий упрощает нашу жизнь, мы как будто outsource решения по дизайну distributed system венндору и сами фокусируемся на бизнес проблеме, но всегда интересно понимать суть происходящего.
На уроке были рассмотрены базовые вещи для distributed systems и их описание.
В целом курс понравился, несмотря на то, что он 2015 года. Узнал что-то нововое. Наример, не существует понятия "сейчас" и на самом деле все эти привычные вещи systime, now() - очень относительные - There is No Now (Problems with simultaneity in distributed systems)
Его одного конечно не достаточно, надо еще и книжку читать про Designing Data Intensive Application (кстати есть на русском). А еще лучше внедрять решение.
Использование облачных технологий упрощает нашу жизнь, мы как будто outsource решения по дизайну distributed system венндору и сами фокусируемся на бизнес проблеме, но всегда интересно понимать суть происходящего.

2021 December 26
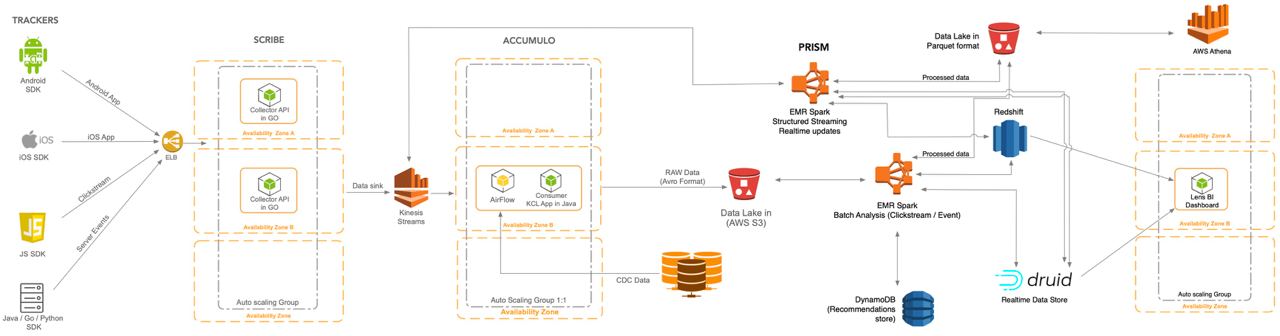
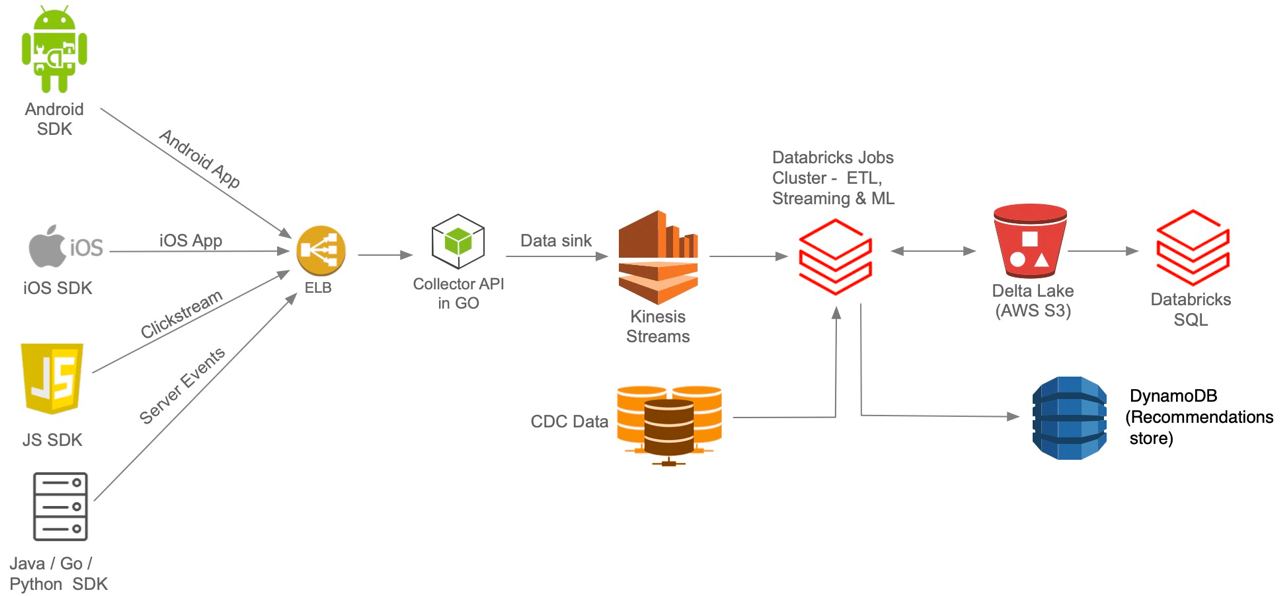
В статье Rethinking Cloud Data Architecture, автор рассказывает как он создавал озеро данных на AWS в 2017 году с использование всевозможных сервисов, достаточно подробно.
А сейчас на диаграмма получилась намного меньше с использование Databricks, там и structured streaming, и data warehouse на базе delta lake и много чего.
PS Автор Solution Architect в Databricks, но все равно он не далеко ушел от правды
А сейчас на диаграмма получилась намного меньше с использование Databricks, там и structured streaming, и data warehouse на базе delta lake и много чего.
PS Автор Solution Architect в Databricks, но все равно он не далеко ушел от правды

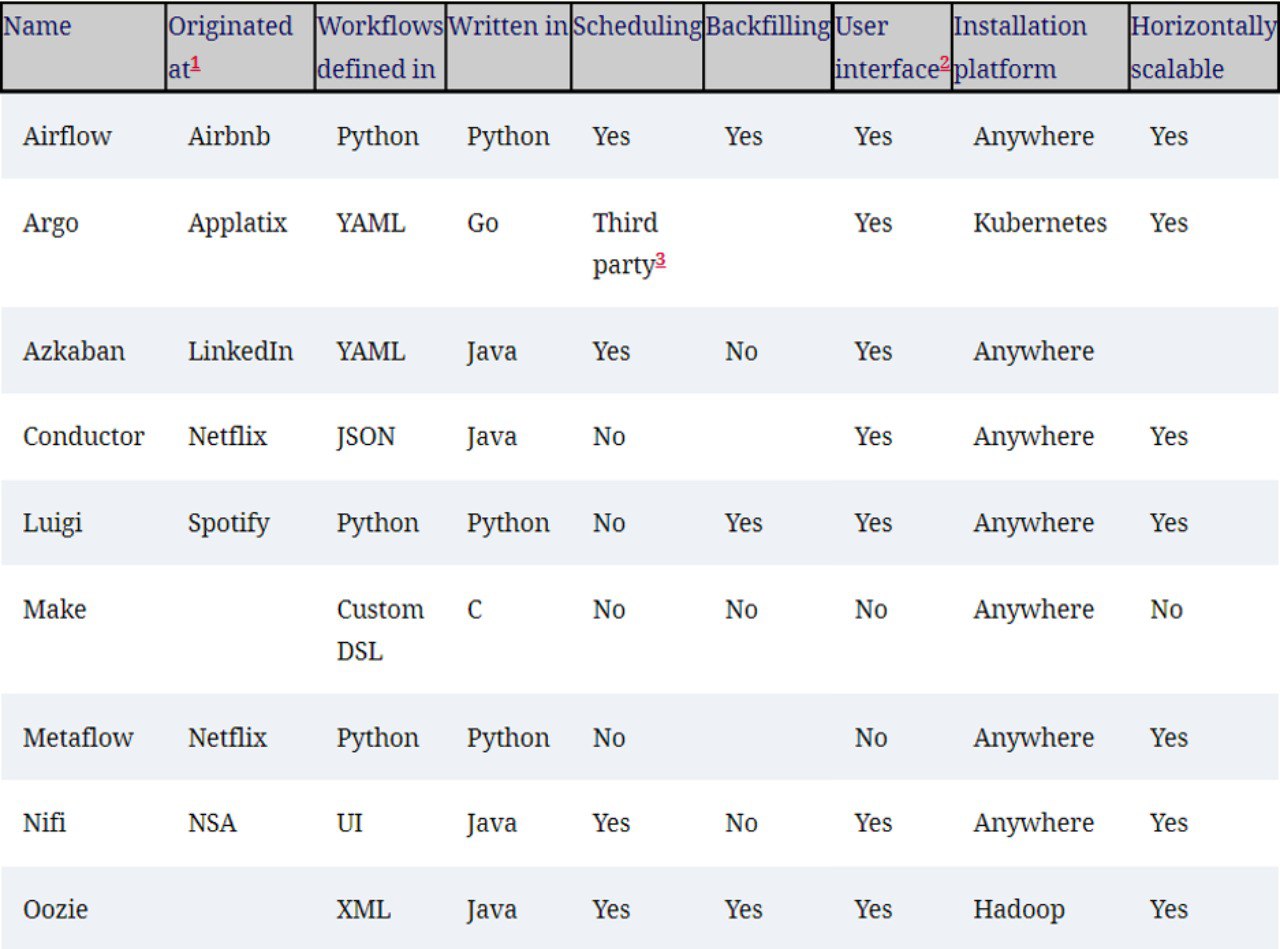
Overview of several well-known workflow managers and their key characteristics. (Из книги https://learning.oreilly.com/library/view/data-pipelines-with/9781617296901/)

Огонь реклама🤣 Интересно это таргетинг такой на меня настроен🤔 Может у них даталерн за 200 рублей можно купить?
2021 December 27
Всем привет!
Завтра (28 декабря) в 21:00 по мск вебинар :)
Тема: Введение в DBT
Что будем делать:
1) кратко поговорим о dbt
2) создадим, запустим dbt проект и построим модельки
3) поговорим, опробуем тесты над данными и поговорим о дополнительных возможностях
4) о документации в dbt
Ссылка на трансляцию:
https://youtu.be/btaH7P0U_2g
Завтра (28 декабря) в 21:00 по мск вебинар :)
Тема: Введение в DBT
Что будем делать:
1) кратко поговорим о dbt
2) создадим, запустим dbt проект и построим модельки
3) поговорим, опробуем тесты над данными и поговорим о дополнительных возможностях
4) о документации в dbt
Ссылка на трансляцию:
https://youtu.be/btaH7P0U_2g

2021 December 28

Через 10 минут начинаем:
https://youtu.be/btaH7P0U_2g
https://youtu.be/btaH7P0U_2g