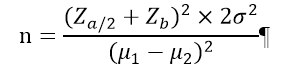PU
угу, я к такой же мысли пришел
Size: a a a
PU
VV
АК
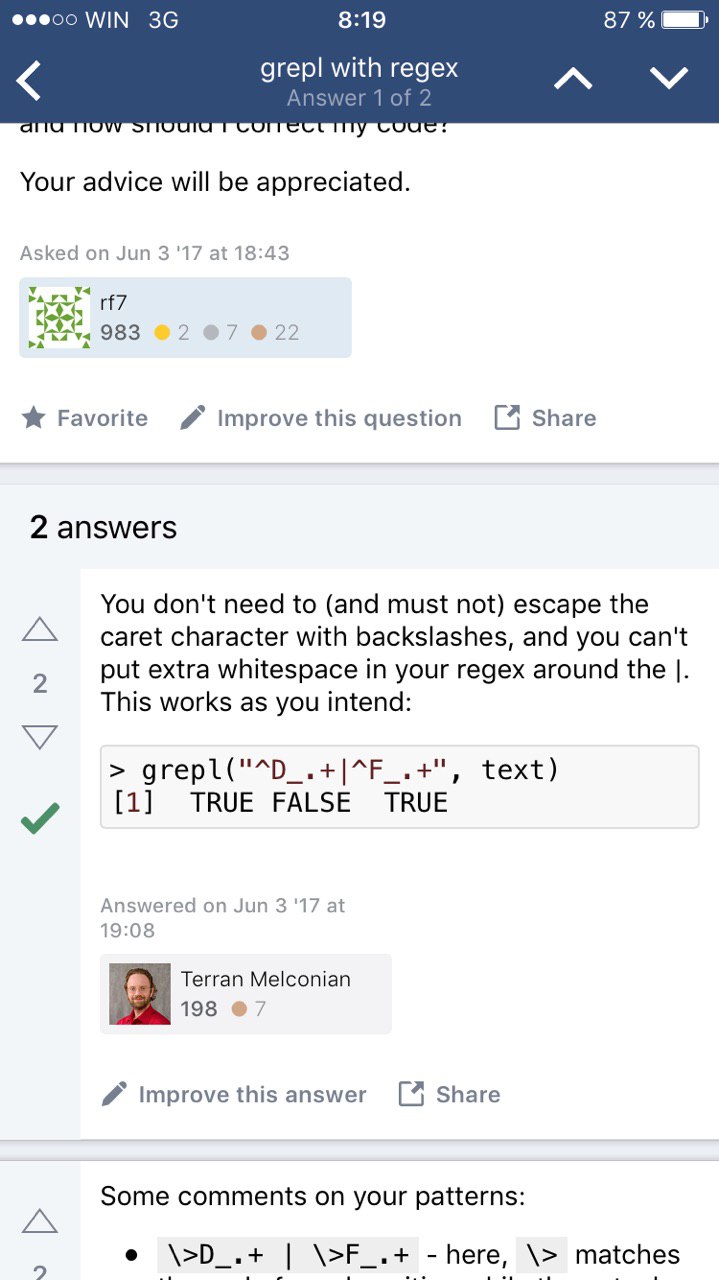
tg_rows <- months_dt[, unique(unlist(lapply(.SD, function(x) grep('r', x))))]
months_dt[tg_rows]months_dt[grep("r", do.call(paste, months_dt))]A
paste0() и ищи в получившейся строке grepl-омA
months_dt[grep("r", do.call(paste, months_dt))]Ю
А[
А[
А[
А[
A
А[
A
A
> n <- TwoSampleMean.NIS(alpha = 0.025,
+ beta = 0.2,
+ sigma = 2,
+ k = 1,
+ delta = 0,
+ margin = 4)
> n
[1] 3.92444
A
power.t.test берут двустороннюю вероятность и для бетыА[