OB
Покажи как код форматировать и я запошу прям сюда
CTRL+SHIFT+M
Size: a a a
OB
k
OB
k
k
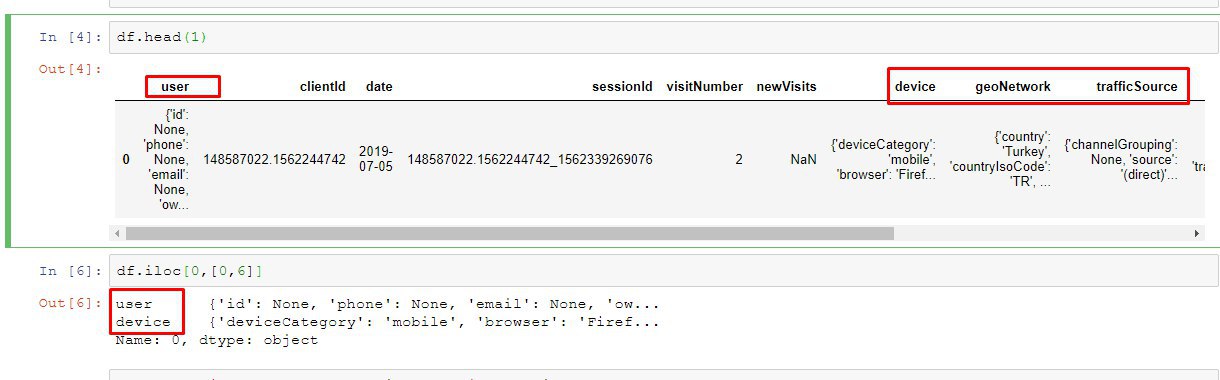
for i in df2['user'].iloc[0]:
df2.insert(len(df2.columns), i, 0)
for i in df2.user.index:
for key in df2.user.iloc[i]:
df2[key].loc[i] = df2.user.loc[i][key]
AR
OB
k
AR
АМ
pd.concat([df.drop(['user'], axis=1), df['user'].apply(pd.Series)], axis=1)АМ
k
pd.concat([df.drop(['user'], axis=1), df['user'].apply(pd.Series)], axis=1)OB
pd.concat([df.drop(['user'], axis=1), df['user'].apply(pd.Series)], axis=1)R
d1 = df['user'].apply(json.loads)
d1 = pd.DataFrame(d1.tolist())
df = df.join(d1, rsuffix='phone')
ВЛ
ВЛ
d1 = df['user'].apply(json.loads)
d1 = pd.DataFrame(d1.tolist())
df = df.join(d1, rsuffix='phone')
R
YP
id value
1 1
1 2
1 3
2 1
2 2
id value max_value
1 1 3
1 2 3
1 3 3
2 1 2
2 2 2
df = df.merge(df.groupby('id').max()['value'].reset_index(), how='left', on='id')