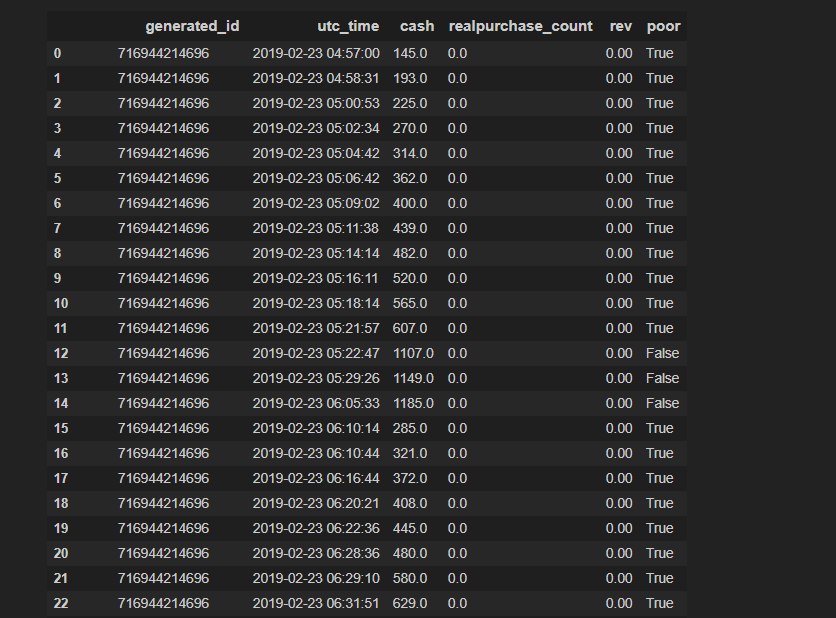
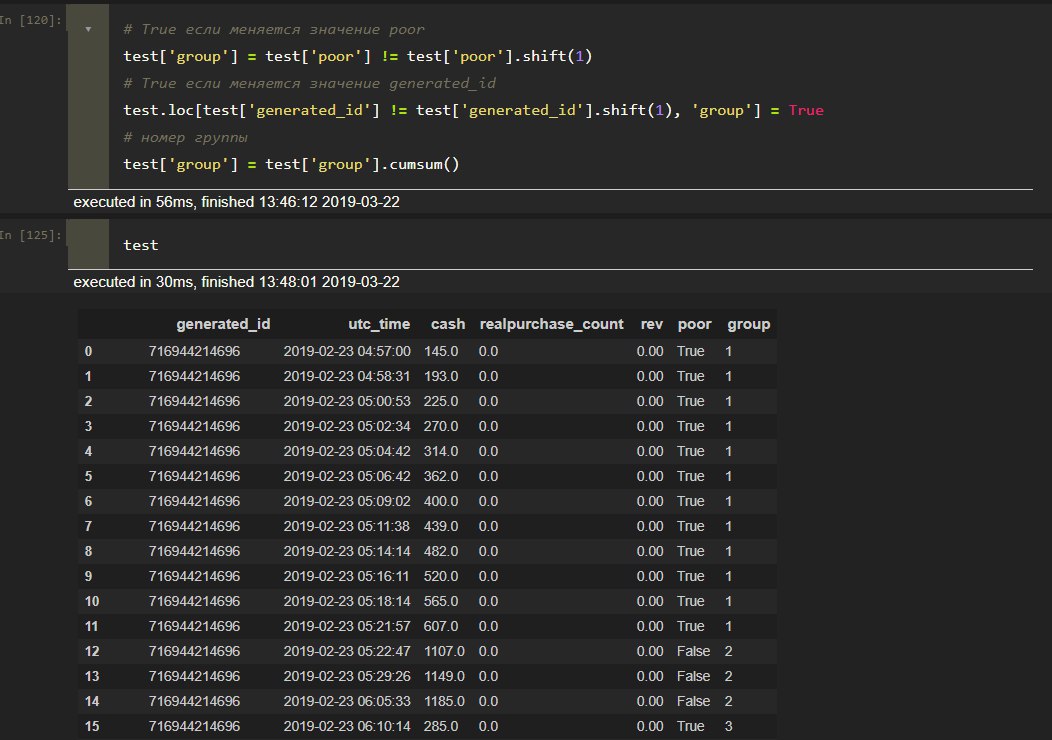
Еще вопрос - как можно сгрппировать таблицу такого вида таким образом, что если в столбце 'poor' идет несколько значение True (или False) подряд, то эти строки аггрегировались и добавлялся столбец с протяженностью периода (то есть максимально utc_time минус минимальное).
При этом groupby['generated_id','realpurchase_count', 'poor'] не подходит, так как нужно группировать именно по идущим подряд непрерывающимся отрезкам True или False.
Писать ли функцию для этого или в чудесном пандасе можно реализовать такую задачу проще?