



A
😁Ага, прям можно вычислять такие штуки.
Size: a a a
A
FF
FF
SM
FF
SM
SM
MK
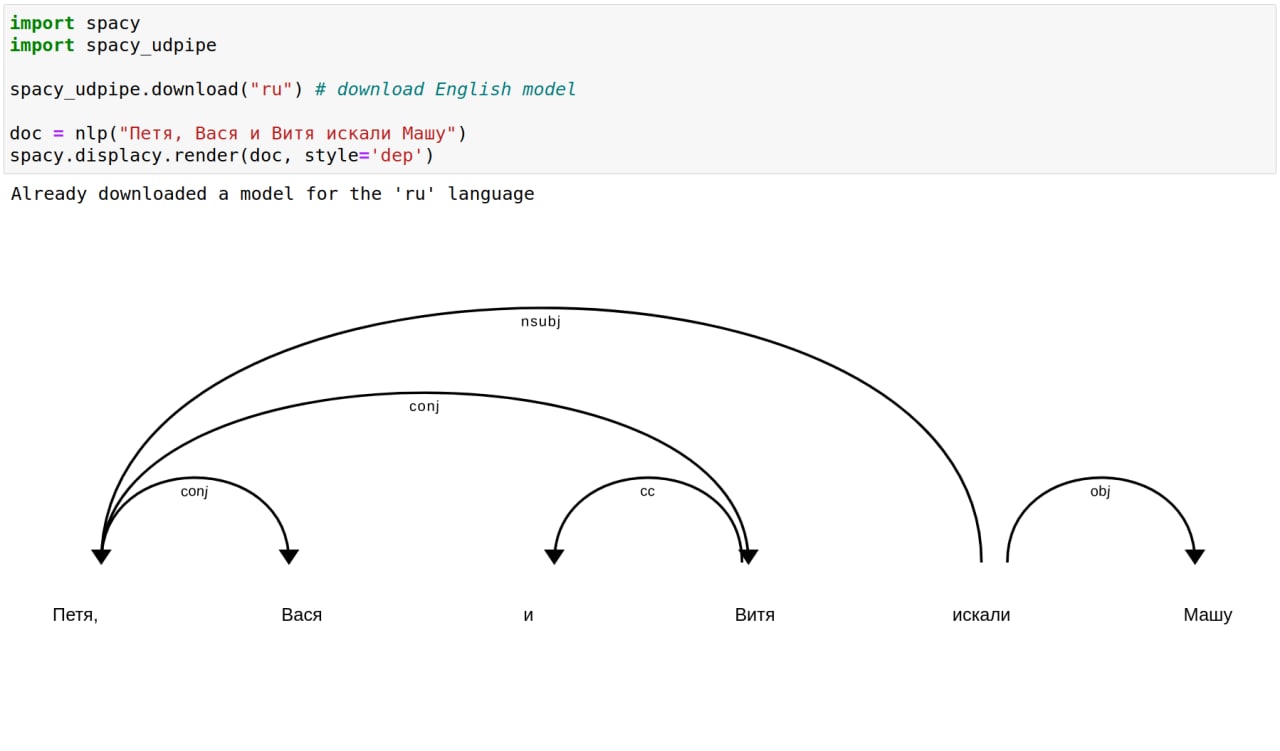
MK
AL
A
MK
AL
from transformers import XLMRobertaTokenizer, TFXLMRobertaModel
import tensorflow as tf
tokenizer = XLMRobertaTokenizer.from_pretrained('xlm-roberta-base')
model = TFXLMRobertaModel.from_pretrained('xlm-roberta-base')
inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
outputs = model(inputs)
last_hidden_states = outputs.last_hidden_state
last_hidden_states - готовые эмбеддинги из последнего слоя роберты, дальше можно их использовать как вход для какой-нибудь модели NERаSM
SM
SM
И
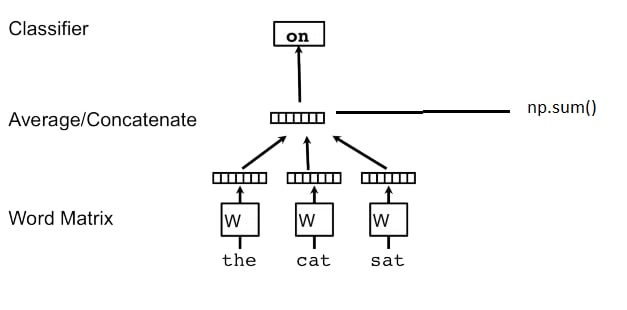
AL
