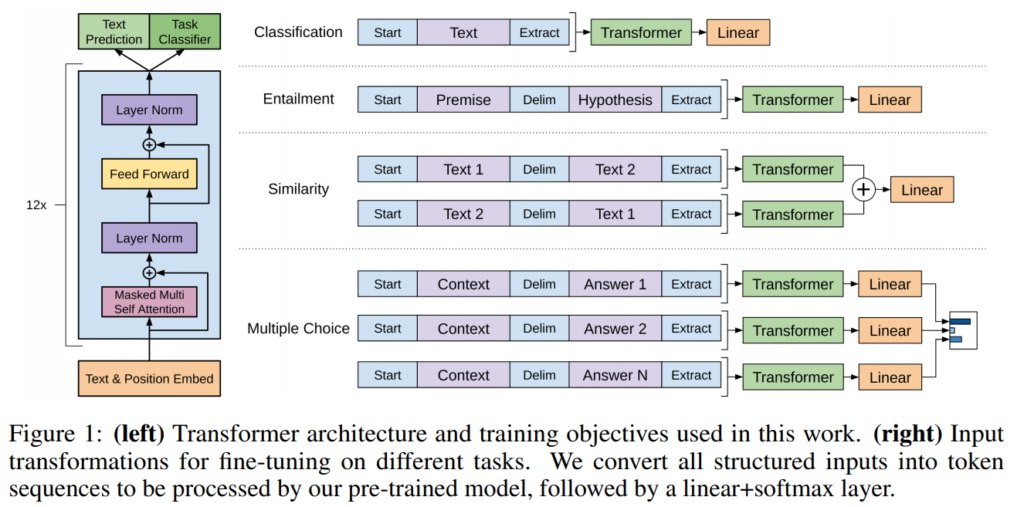
Всем привет Столкнулся с такой задачей. Имеется некоторое предложение. За ним следует другое, и нужно определить: является следующее просто пересказом предыдущего, либо же это "продолжение истории" Как понимаю, первое — это задача paraphrase identification. А второе? И чем лучше решать? Из того, что здесь видел — flair и LASER
Привет. Второе пересекается с задачей поиска анафорических связей.
Добрый день. Есть ли на премете датасеты для сентиментального анализа на русском для деловых переписок, рабочих обсуждений, в которых негатив выражается не в виде явных оскорблений и "постановках диагнозов", а в завуалированном виде?
Всем привет. Кто-нибудь решал тут задачу расстановки ударений в русских ФИО? Пробовал russian_g2p, почти всегда на первый слог ставит. Пока никакого решения, кроме как делать словарь ударений для ФИО не вижу...