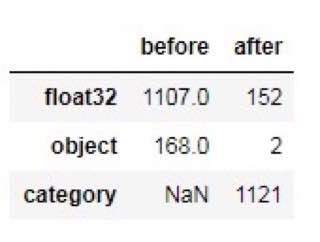
Из занимательных наблюдений: у меня на одной задаче довольно быстро нарастает датасет для обучения. И вот чем он больше, тем бОльший lr хорошо заходит. на примерно 4М строк ставлю lr=0.6 и отлично всё. а на маленьких наборах приходится ставить на порядок меньшие значения, чтобы не было оверфита.