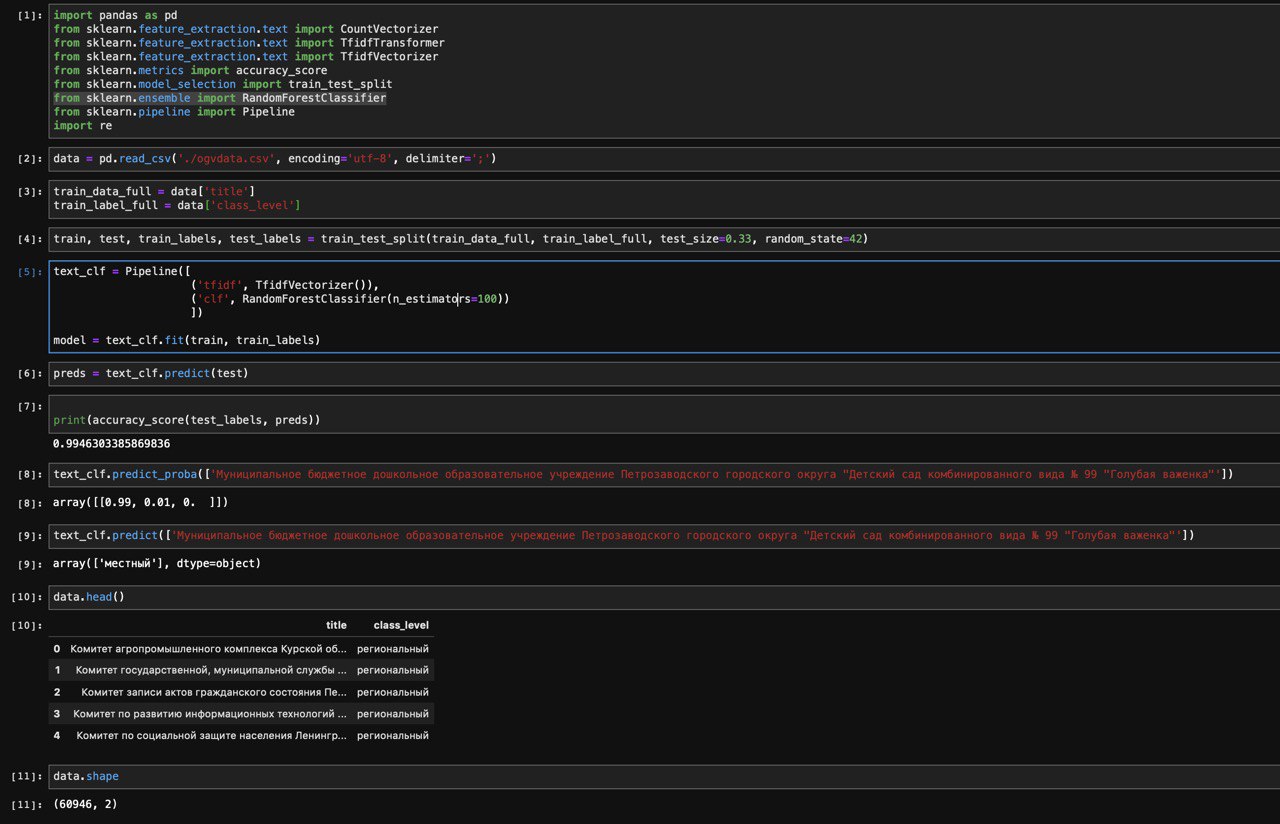
А подскажите в какую сторону копать, RandomForestClassifier accuracy_score=0.994 предсказывает в моем случае лучше, чем GradientBoostingClassifier accuracy_score=0.972, с чем это может быть связано?
Вообще хорошо б теоретическое обоснование услышать в ответе на ваш вопрос.
Штука действительно интересная. Подобная тема уже проскакивала у Дьяконова в статье, посвящённой случайному лесу. Там вроде бы по касательной был затронут вопрос, в 100 ли случаях из 100 бустинг на деревьях обойдёт случайный лес или нет. Кто-то даже приводил в качестве примера какие-то старые соревнования на каггле, где лес действительно выигрывал.