SK
Добрый день.
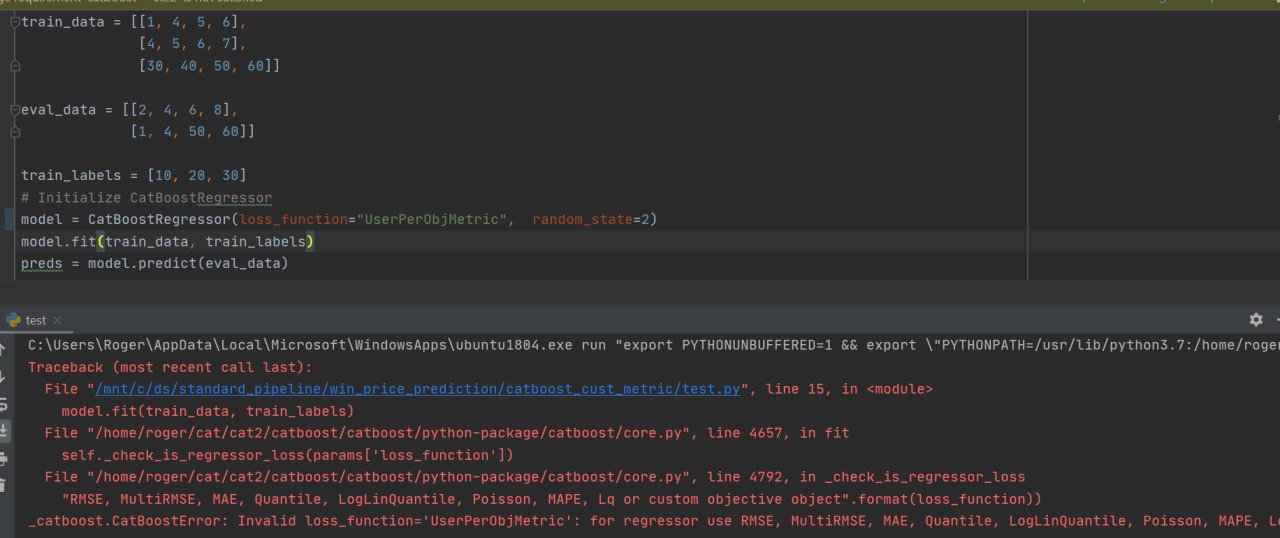
Обнаружил, что при кросс-валидации catboost использует процессор (i5 3550) на 10-20%. Причем нагрузка равномерно распределена на все ядра. При этом при обычном обучении все ядра и процессор в целом используется по максимуму. Нормально ли это, и если нет, то что можно с этим сделать?
Обнаружил, что при кросс-валидации catboost использует процессор (i5 3550) на 10-20%. Причем нагрузка равномерно распределена на все ядра. При этом при обычном обучении все ядра и процессор в целом используется по максимуму. Нормально ли это, и если нет, то что можно с этим сделать?
Это не очень нормально, желательно сделать issue про это, чтоб мы не забыли посмотреть.