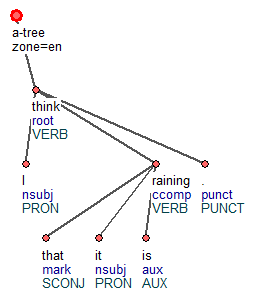
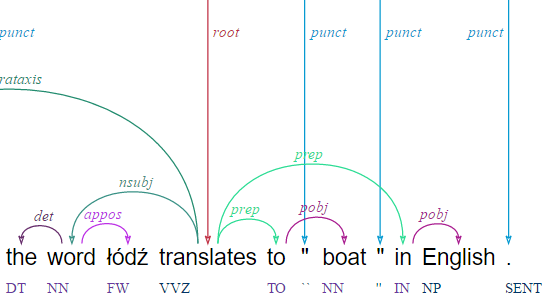
Здравствуйте. Мы (команда исследователей) хотим построить синтаксический анализатор русского языка с использованием текстовых корпусов.
Для каждого предложения из файла CoNLL-U мы берём соответствующее дерево, записываем набор морфологических признаков (НМП) слов в вершины (узлы) этого дерева и помечаем рёбра дерева метками, которые являются universal dependency relations.
Данные X_train - это пары наборов морфологических признаков (то есть пары вершин дерева или, что то же самое, рёбра дерева), а соответствующие y_train - метки рёбер (universal dependency relations).
Так что это проблема многоклассовой классификации, все данные являются категориальными.
Мы хотим использовать классификатор CatBoost для этой задачи разметки рёбер деревьев. Возможно ли это для этой задачи?
https://universaldependencies.org/format.htmlhttps://universaldependencies.org/tools.htmlhttps://arborator.ilpga.fr/q.cgiФактически мы имеем специфический набор данных, состоящий только из категориальных переменных. X_train - это список кортежей из двух кортежей переменной длины внутри них.
X_train и y_train - нечто вроде
X_train = [(('a', 'b', 'c'), ('b', 'd')), (('d', 'c'), ('b', 'a')), (('a', 'c', 'd'), ('a', 'b')), (('a', 'c', 'd'), ('b', 'a', 'c')), (('a', 'b'), ('c', 'a', 'd'))],
y_train = ['p', 'q', 'r', 'q', 'p'].
Я не могу применить CatBoost к своим данным, я не понимаю, как использовать cat_features с моим набором данных.