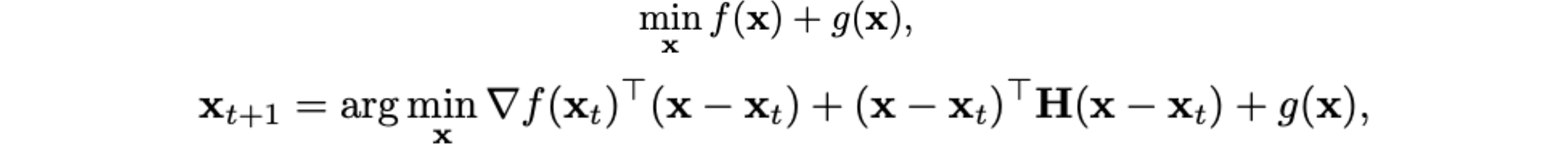
Simulating Emergent Properties of Human Driving Behavior
Using Multi-Agent Reward Augmented Imitation Learning
https://arxiv.org/pdf/1903.05766.pdf
⌛️ Когда - 14 марта 2019
🍾В чем понт?
Для того, чтобы проводить эксперименты с системой из большого количества автомобилей (например, планировать совместное движение беспилотных машин), нужно уметь создавать правдоподобные симуляции такого движения - чтобы автомобили не проезжали сквозь друг друга, не катались по обочине, не носились на неадекватных скоростях по странной траектории и соответствовали нашему пониманию приемлимого вождения. Авторы статьи улучшили подход к генерации треков автомобилистов и даже выложили код своих экспериментов на github (!).
🔦 Подробности
🚗 Модель
Авторы поставили задачу следующим образом - нам нужно выучить политику - вероятность оптимального действия, при условии текущего состояния (положения машин в пронстранстве). Авторы исходили из того, что политики разных машин не зависят друг от друга и что все машины находятся в одинаковой среде с одинаковыми параметрами. Награды в этой задаче - то, насколько траектории агентов вероятностно похожи на траектории реальных автомобилей из исторической выборки. Авторы добавили 2 фишки. Первая - шерить параметры разных автомобилей, чтобы было легче тренироваться. Вторая - ввести ограничения на некоторые действия, исходя из априорных представлений о том, как не должна двигаться машина (например, нормальной машине не стоит покидать пределы трассы)
⚖️Эксперименты
В экспериментах авторы мерили три группы метрик. Первая - локальное поведение автомобилиста (RMSE между настоящими и сгенерированными треками). Вторая - экстремальность поведение на дороге (количество таких нежелательных событий, как сьезды на обочину, столкновения). Третья - средние характеристики движения (сколько раз в среднем водители перестраиваются, среднее время между автомобилями, их средняя скорость). Во всех группах метрик алгоритм авторов RAIL обошел предыдущее решение GAIL.
🔎 Что в итоге
Грамотная реализация симуляции движения автомобиля, которая в наш век аггрегаторов такси и беспилотных автомобилей еще не раз пригодится в проведении симуляционных экспериментов. На гифке нарисован пример генерации треков автомобилей, полученный с помощью выложенного на github кода. Красный цвет обозначает сгенерированные машины, зеленый - реально существовавшие на исторической выборке.
Using Multi-Agent Reward Augmented Imitation Learning
https://arxiv.org/pdf/1903.05766.pdf
⌛️ Когда - 14 марта 2019
🍾В чем понт?
Для того, чтобы проводить эксперименты с системой из большого количества автомобилей (например, планировать совместное движение беспилотных машин), нужно уметь создавать правдоподобные симуляции такого движения - чтобы автомобили не проезжали сквозь друг друга, не катались по обочине, не носились на неадекватных скоростях по странной траектории и соответствовали нашему пониманию приемлимого вождения. Авторы статьи улучшили подход к генерации треков автомобилистов и даже выложили код своих экспериментов на github (!).
🔦 Подробности
🚗 Модель
Авторы поставили задачу следующим образом - нам нужно выучить политику - вероятность оптимального действия, при условии текущего состояния (положения машин в пронстранстве). Авторы исходили из того, что политики разных машин не зависят друг от друга и что все машины находятся в одинаковой среде с одинаковыми параметрами. Награды в этой задаче - то, насколько траектории агентов вероятностно похожи на траектории реальных автомобилей из исторической выборки. Авторы добавили 2 фишки. Первая - шерить параметры разных автомобилей, чтобы было легче тренироваться. Вторая - ввести ограничения на некоторые действия, исходя из априорных представлений о том, как не должна двигаться машина (например, нормальной машине не стоит покидать пределы трассы)
⚖️Эксперименты
В экспериментах авторы мерили три группы метрик. Первая - локальное поведение автомобилиста (RMSE между настоящими и сгенерированными треками). Вторая - экстремальность поведение на дороге (количество таких нежелательных событий, как сьезды на обочину, столкновения). Третья - средние характеристики движения (сколько раз в среднем водители перестраиваются, среднее время между автомобилями, их средняя скорость). Во всех группах метрик алгоритм авторов RAIL обошел предыдущее решение GAIL.
🔎 Что в итоге
Грамотная реализация симуляции движения автомобиля, которая в наш век аггрегаторов такси и беспилотных автомобилей еще не раз пригодится в проведении симуляционных экспериментов. На гифке нарисован пример генерации треков автомобилей, полученный с помощью выложенного на github кода. Красный цвет обозначает сгенерированные машины, зеленый - реально существовавшие на исторической выборке.