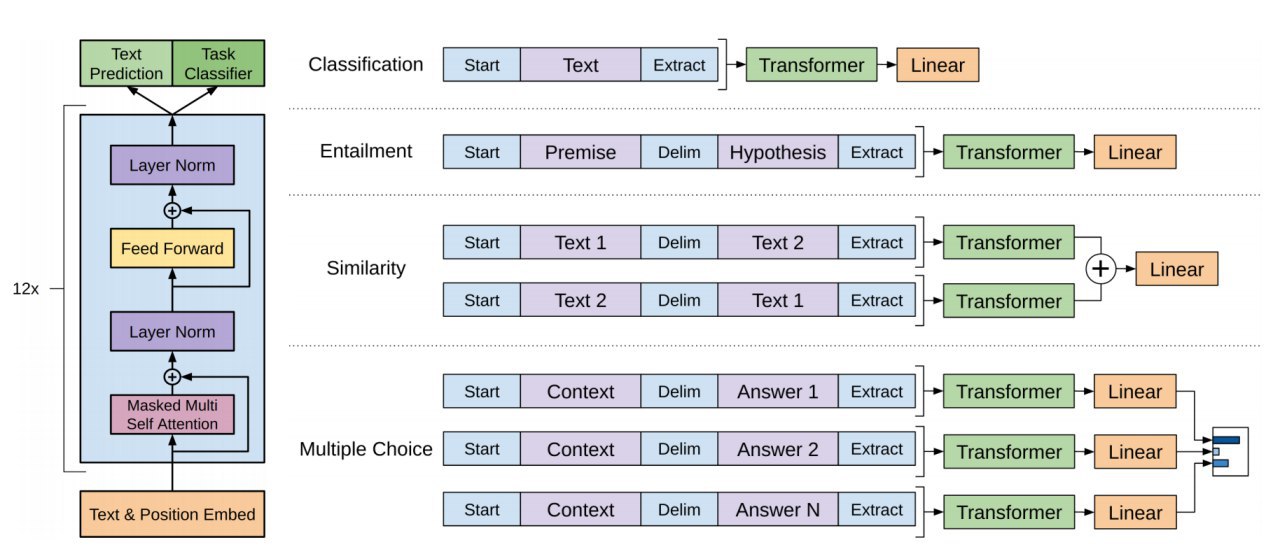
Program Synthesis Through Reinforcement Learning Guided Tree Search
https://arxiv.org/pdf/1806.02932.pdf
🕐 Когда - 8 июня 2018
👓 В чем понт
Модель на основе обучения с подкреплением и поиска по дереву, умеющая писать программный код и обгоняющая остальные SOTA подходы до 400%
🔎 Подробности
С точки зрения RL задачу можно поставить так: у нас есть агент - алгоритм-программист. Действия - это строки программного кода, который он может писать, состояния - память до и после написания кода. Реворд обратно пропорционален сумме действий, которые пришлось совершить агенту (хотим писать короткий код) и расстоянию между желаемым и наблюдаемым состоянием памяти. После того, как мы набираем некий пороговый реворд, программа считается решенной. В результате обучения мы получаем политику - то, с какой вероятностью из текущего состояния памяти нужно писать каждую возможную строку кода. Оптимизируемся мы алгоритмом Q-learning - предсказываем будущий реворд из определенного состояния и действия. Однако процесс решения долгий и, чтобы его ускорить, увеличив количество решенных программ за фиксированное число попыток, применяется поиск по дереву. Сначала мы с учетом политики случайно выбираем следующие состояния, считаем для них реворд, обучаемся на этом, делаем так 100 раз. Затем мы считаем Q-функцию для всех состояний, в которые мы случайно не попали, а потом жадно (сэмплируем из политики не вероятностно, а наиболее оптимально) выбираем следующия состояния, обучаемся на них, делаем так еще 100 раз. Это позволяет не упереться в локальный минимум и быстрее обучиться. Именно поиск по дереву - одна из главных фишек статьи, дающая прирост во всех экспериментах на 70%-100%.
🖋 Что в итоге
Шаг навстречу автоматизации программирования, модель заметно лучшего качества, решает до 400% больше программ, чем ее предшественники(например, MCMC - стохастический поиск, основанный на эвристике), не делает дополнительных предположений о языке программирования, отправлена на NIPS 2018.