Deep contextualized word representations
https://arxiv.org/pdf/1802.05365.pdf
за наводку спасибо @annapotapenko
Когда
15 февраля 2018 года
В чем понт
Для того, чтобы решать задачи nlp, надо уметь получать хорошие векторные представления слов, которые будут моделировать семантику, синтаксис и омонимию (например слово ‘лук’ может нести 2 смысла, для которых надо использовать разные вектора). При этом здорово использовать и нагенерированный человечеством массив информации, и уметь быстро приспосабливаться под локальные особенности задачи и текста. Что и сделали авторы, побив state of the art в 6 задачах nlp на 6-20% (например, анализ тональности, выделение частей речи)
Подробности
Для каждого токена (слова или некоторого количества символов) хочется получить несколько векторов, чтобы потом для каждой задачи скомбинировать их оптимальным образом, то есть просто выучить веса, с которыми их нужно складывать (что позволит учесть локальные особенности текста и задачи, омонимию)
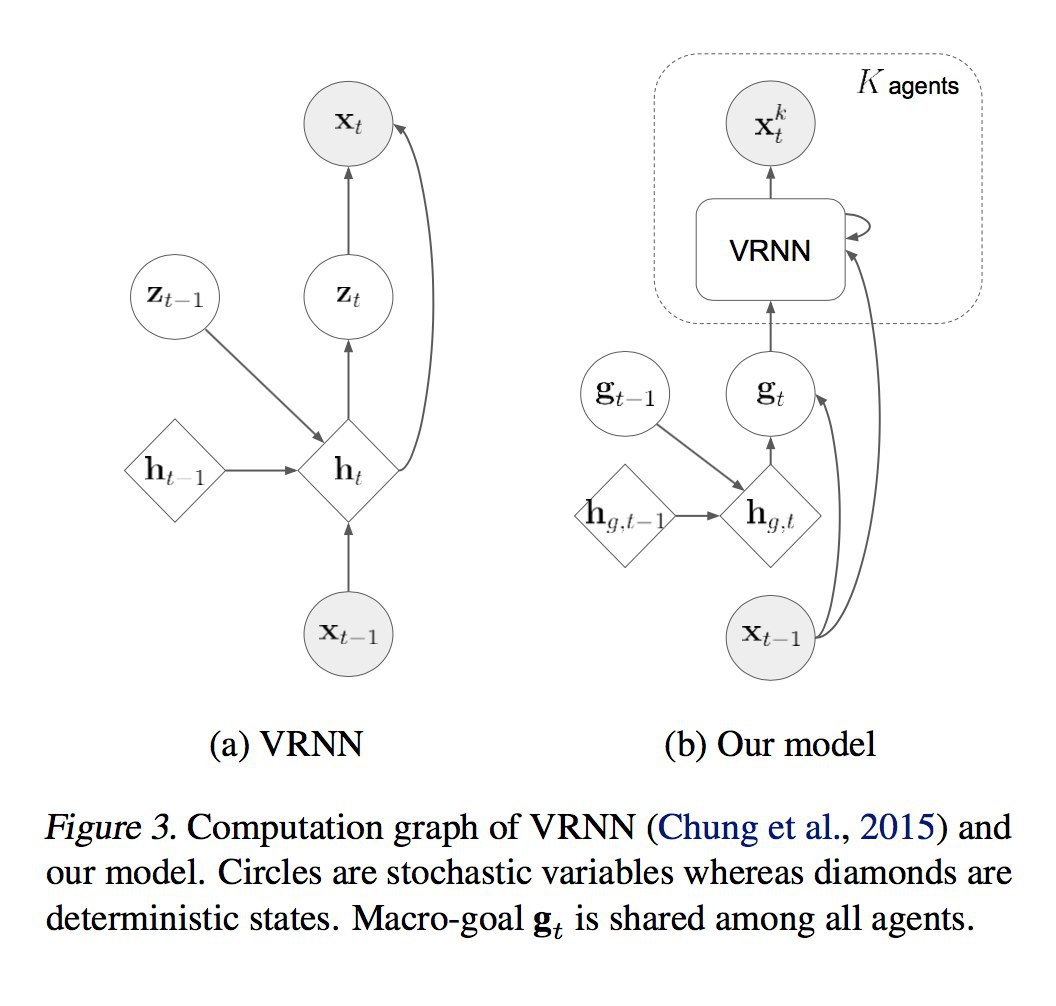
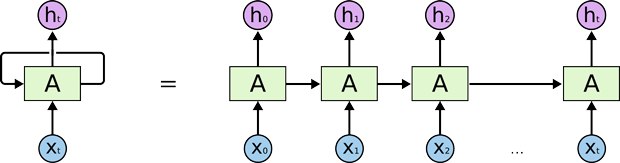
Такие вектора для каждого токена получаются обучением LSTM прямого и обратного распространения. Forward LSTM учится предсказывать вероятность токена при условии предыдущих токенов и скрытых состояний сети, backward - при условии следующих, суммарный лосс получается сложением лоссов forward и backward. Для каждого токена используется такие сети forward и backward LSTM каждая с L слоями, соответственно нулевое состояние - это Glove вектор, который пока не учитывает контекст, последнее состояние используется для предсказания следующего токена. На выходе для каждого токена получим набор векторов, состояний всех слоев forward и backward LSTM, которые осталось только сложить с нужными весами. Веса мы уже учим на конкретной задаче и данных (например, для слова три среди векторов будет часть векторов, близких к слову два и мой, вектора, отражающие глагол это или числительное, вектора, из которых можно понять эмоциональную окраску текста)
https://arxiv.org/pdf/1802.05365.pdf
за наводку спасибо @annapotapenko
Когда
15 февраля 2018 года
В чем понт
Для того, чтобы решать задачи nlp, надо уметь получать хорошие векторные представления слов, которые будут моделировать семантику, синтаксис и омонимию (например слово ‘лук’ может нести 2 смысла, для которых надо использовать разные вектора). При этом здорово использовать и нагенерированный человечеством массив информации, и уметь быстро приспосабливаться под локальные особенности задачи и текста. Что и сделали авторы, побив state of the art в 6 задачах nlp на 6-20% (например, анализ тональности, выделение частей речи)
Подробности
Для каждого токена (слова или некоторого количества символов) хочется получить несколько векторов, чтобы потом для каждой задачи скомбинировать их оптимальным образом, то есть просто выучить веса, с которыми их нужно складывать (что позволит учесть локальные особенности текста и задачи, омонимию)
Такие вектора для каждого токена получаются обучением LSTM прямого и обратного распространения. Forward LSTM учится предсказывать вероятность токена при условии предыдущих токенов и скрытых состояний сети, backward - при условии следующих, суммарный лосс получается сложением лоссов forward и backward. Для каждого токена используется такие сети forward и backward LSTM каждая с L слоями, соответственно нулевое состояние - это Glove вектор, который пока не учитывает контекст, последнее состояние используется для предсказания следующего токена. На выходе для каждого токена получим набор векторов, состояний всех слоев forward и backward LSTM, которые осталось только сложить с нужными весами. Веса мы уже учим на конкретной задаче и данных (например, для слова три среди векторов будет часть векторов, близких к слову два и мой, вектора, отражающие глагол это или числительное, вектора, из которых можно понять эмоциональную окраску текста)