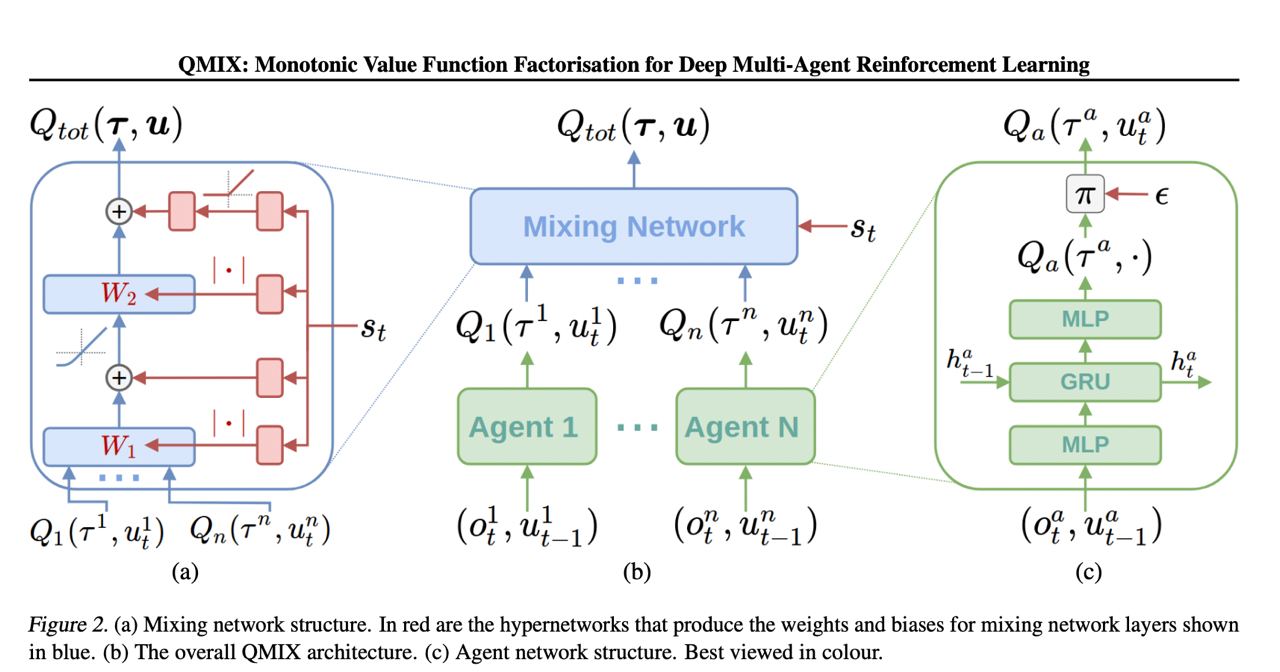
архитектура qmix больше подходит для сеттинга, где количество юнитов постоянно, а не варьируется т.к. 1) mixing network, которая берет на вход q-values юнитов это mlp, и 2) предполагается выучивание q-value для каждого юнита
Мб если модифицировать qmix mixing network в какую то рекурентность, то можно переделать метод для варьирующегося числа юнитов
еще меня чуть смущает, что такой сильный акцент на partial observability между самими юнитами, per unit q-values, которые они как бы фиксят через hypernetwork от state для весов mixing net, чтобы интегрировать оценку q-value на основе всей доступной инфы, как будто есть недостаток в изначальной архитектуре с q-values per unit, а это костыль поверх этого недостатка (относительно их же примеров с игрой в табличку и маленькие файты в старкрафт, где нет этой partial obervability per unit), имхо, мб моя критика от непонимания чего-то
возможно в старкрафт и тд сеттингах (fully cooperative, shared team reward) centralized policy мне кажется лучше, чем decentralized




