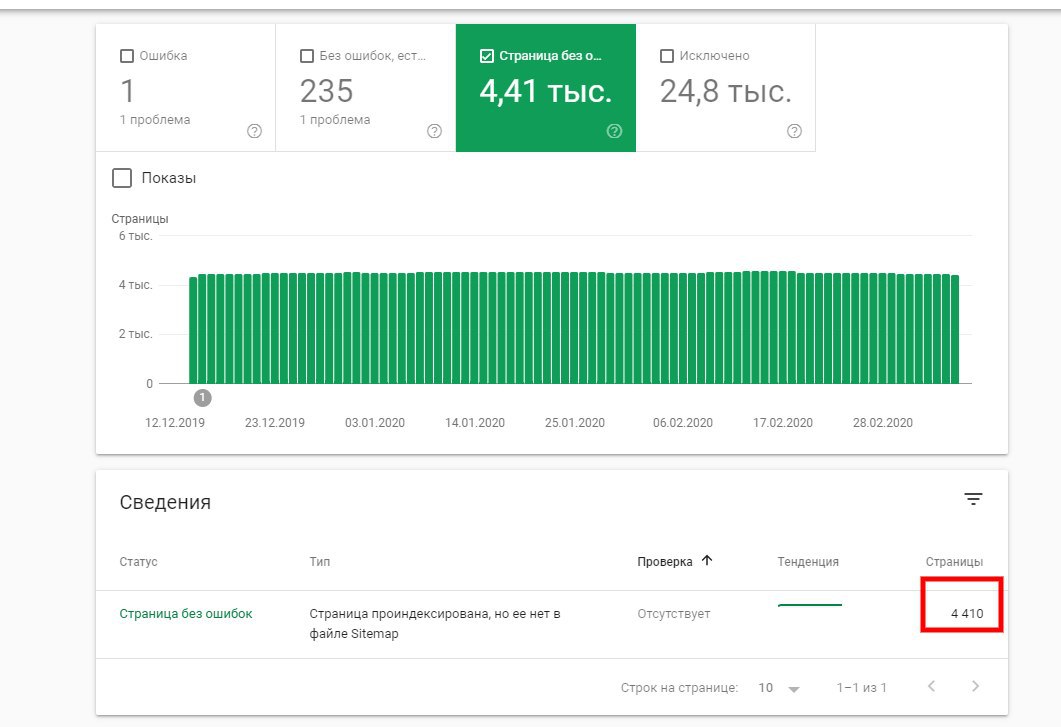
нужно понять какие страницы в индексе уже и исключить мусорные, усложняется тем что сайт большой + старый сайт имел неизвестную мне структуру (т.е. например имел разделы, которых нет на новом) ...при переезде на новый редиректы не настроили.
1. Быстрый и неточный метод.
Загрузить URL, которые получали показы. В Netpeak Spider это можно сделать так →
https://img.netpeaksoftware.com/gravelot/1QFQORG.png . Лучше задать большой период выгрузки.
Так можно получить много страниц, которые были в индексе, но не все.
2. Медленный и точный метод.
Пробивать итеративно выдачу как я описывал выше (используя site: и inurl:), чтобы определить все страницы в индексе. Нужны прокси и антикапча.