sergeysova
Немного обсуждений в
@effectorjs чате натолкнули меня на мысль изменить подход к описанию логики в effector+react.
Я стараюсь
разделять представление и логику. Если взять в пример страницы, рядом с файлом компонента страницы лежал файл логики на эффекторе.
pages/counter/{index.tsx, model.ts}В файле компонента я напрямую импортировал сторы и ивенты из модели и использовал в компонентах:
import * as React from ‘react’
import { useStore } from ‘effector-react’
import { $counter, incrementClicked, pageMounted } from ‘./model’
export const CounterPage = () => {
const counter = useStore($counter)
React.useEffect(() => { pageMounted() }, [])
// show counter and use events
}И это работало весьма хорошо, тестировать просто (импортируем сторы в тест и
setState(data)). Объявляем контрактом любые экспорты из model.ts и очень осторожно их изменяем.
View-слой (компонент) может независимо меняться от бизнес-логики, и логика может переписываться, если не меняется контракт(экспортируемые сущности).
Но если нужно маппить данные из стора по какому-то ключу или ещё какие операции со списками, то эта логика затаскивалась прям в компонент вместе с useStoreMap и useList. Это мне не очень нравится, ибо тестировать становится сложнее.
И я наткнулся на один антипаттерн, который использовал мой коллега в разработке. Но немного подумав, я понял, что это очень полезный
паттерн разделения логики и представления.
Использовать хуки, для получения данных и ивентов из модели.
Я предлагаю из модели экспортировать реакт-хуки, вместо сущностей и ивентов. Этот подход имеет смысл в первую очередь для моделей страниц. Разделяемые сущности чаще всего не нужно отдельно заворачивать в хуки, так как часто хочется создавать computed от общих сторов.
Как это выглядит и что это дает: модель экспортирует хуки, которые возвращают наборы данных и ивенты. В этих хуках могут быть любые необходимые вычисления.
import { useCounter, useEvents } from ‘./model’
export const CounterPage = () => {
const counter = useCounter()
const { pageMounted, incrementClicked } = useEvents()
React.useEffect(() => { pageMounted() }, [])
// show counter and use events
}
Можно пойти дальше, и унести React.useEffect() внутрь useEvents, чтобы модель сама устанавливала нужные реакции. Но тут спорно и нужно обдумать. Возможно это нужно выделить в отдельный хук.
А теперь зачем это.
1.
Семантика. Теперь, контракт выглядит как независимая сущность. Можем заменять STM как нам захочется, внутри хука может быть React.useReducer, или же Redux.useSelector, или же Effector.useStore. Все равно.
2.
Сокрытие сложности. Всякие useStoreMap могут быть скрыты внутри хука, разработчику компонента теперь не нужно знать детали реализации модели, чтобы разработать компонент. Ведь теперь, чтобы рабоать независимо достаточно спроектировать контракт на хуках, описать типы и вернуть dummy-данные.
3.
Тестирование. Тесты упрощаются, до мока конкретных хуков, а не сторов. Ведь теперь разработчик компонента, может спокойно написать тесты только на вью, не трогая при этом сторы модели. Логика моделей при этом может быть разработана действительно независимо.
Я пока не могу понять, имеет ли смысл разделять контракт и модель? pages/counter/{contract.ts, model.ts, index.tsx}
- contract — импорты из model завернутые в react-хуки
- model — чистая логика, без примесей хуков
- index — компонент, использующий контракт, без примесей STM
Как думаете?
Год назад я описал свои размышления по разделению логики и представления при описании страниц на Effector + React.
Весь 2020 год я искал подход, который позволил бы мне очень сильно упростить разработку и тестирование, при этом имея разделенные слои вью и модели.
Раньше, я импортировал сторы и ивенты из модели прям в файл с компонентом. Такой подход позволяет легко тестировать саму модель — замокал api и внешние сервисы и погнали.
Но вот с тестированием компонента проблема, так просто замокать сторы не получится, придется прибегать к костылям в jest. Казалось бы, почему я не могу тестировать компоненты сразу с запущенной моделью. А ответ кроется в деталях реализации модели: в тест компонента попадают моки апи и фич, что неприемлемо, ведь при модификации модели без изенения апи, упадет тест компонента, а это вообще не то, что хотелось бы.
Второй кейс это независимая разработка компонента и логики. Я такое уже практиковал в разных командах: один разработчик пишет модель по заранее согласованному API, другой разработчик параллельно разрабатывает компонент опираясь только на типы сторов и ивентов.
Но разработать недостаточно, нужно ещё покрыть тестами и тут начинаются проблемы: когда разработчик компонента заканчивает разработку и написание тестов, он уверен в работе своего компонента, но позже свою работу заканчивает разработчик модели. Весь код смерживается и тесты компонента падают, потому что моки апи не были настроены в этом тесте.
Я не хочу разделять свою модель на state, init и index, потому то не люблю, когда логика размазывается по нескольким файлам. Да, мы все помним .h файлы в C++, только вот новые языки не разделяют определение и реализацию, потому что определение это зачастую важная часть логики. В моем случае так же: combine, attach, .map и прочие фабрики сущностей должны быть размещены в state и index по дефолтной рекомендации эффектора, в то время как в них лежит логика.
Например:
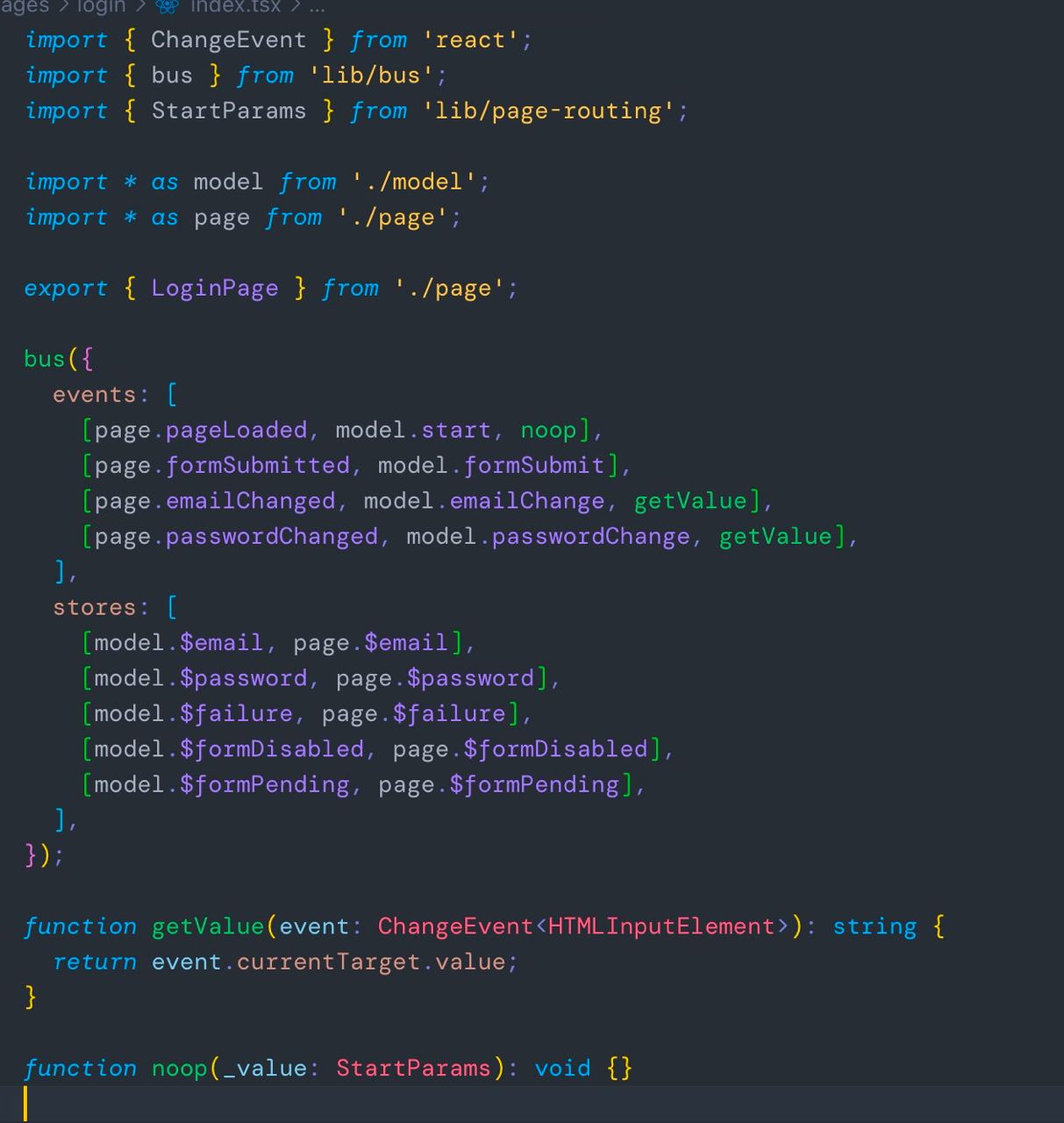
$formPending = combine(fx.pending, email.map(fn), ...)Я продолжаю описывать логику в одном файле соответствуя
описаной ранее структуре, но никто не мешает мне отделить фазу соединения компонента и модели — так называемый init-файл. Да, моё предложение сводится только к объединению идеи init-файлов и логики в едином файле.
А работает это очень просто:
- в модели как и ранее описывается вся логика и все ивенты необходимые для работы. Только полностью удаляются любые упоминания view-слоя, в моём случае React.
- в файле компонента описывается jsx и привязки к сторам и ивентам эффектора, но никаких импортов модели не производится. Все необходимые юниты создаются сразу же в файле компонента и экспортируются. Теперь файл компонента я называю page.tsx
- init-файл я называю index.ts и в нем размещаю связи между сторами/событиями компонента и модели. Фактически производится форвард из сторов модели в сторы страницы и из событий страницы в события модели.
События страницы всегда пересылаются в модель, но не наоборот. Модель не может влиять на страницу через события, react-компонент просто не подписывается на события, ему это не нужно.
А вот сторы всегда пересылаются в обратном направлении — из модели в страницу. Реакт компонент становится функцией от состояния, он умеет только отправлять события и рендериться на основе данных.
Тесты писать крайне просто: импортируем компонент, форкаем root-домен, проставляем нужные значения в сторы компонента и проверяем результат. Аналогично поступаем с событиями, просто проверяем, что они вызываются с правильными ивентами и значениями.