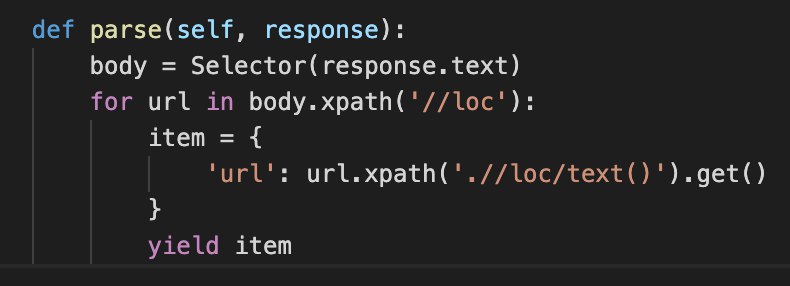
Всем привет. При записывании даных в CSV файл нарушаеться порядок записи, а имено я указывал первым столбцом имя, вторым номер таблици и т.д. Но первым записываеться четвертая позиция. Никак не могу понят в чем дело.
Вот код:
# -*- coding: utf-8 -*-
import scrapy
from ..items import NhlItem
import re
class NhlSpider(scrapy.Spider):
name = 'nhl'
start_urls = [
'
https://www.nfl.com/players/damiere-byrd/stats/logs/'
]
def parse(self, response):
items = {}
reqex = re.compile('(@\w+|\w+)', re.M)
for name in response.css('tbody'):
if name:
for i in range(len(name.xpath('//tr/td[1]/text()').getall())):
items['name'] = response.xpath('//*[@id="main-content"]/div[1]/div/section/div/div/div/h1/text()').get()
items['namber'] = re.findall('\d+', str(name.xpath('//tr/td[1]/text()').getall()))[i]
items['year'] = re.findall('\d+/\d+/\d+', str(name.xpath('//tr/td[2]/text()').getall()))[i]
opp = name.xpath('//tr/td[3]/text()').getall()[i]
items['opp'] = reqex.findall(opp)
items['result'] = re.findall('\w* \d+ - \d+', str(name.xpath('//tr/td[4]/text()').getall()))[i]
items['rec'] = re.findall('\d*', str(name.xpath('//tr/td[5]/text()').getall()))[i]
yield items