A
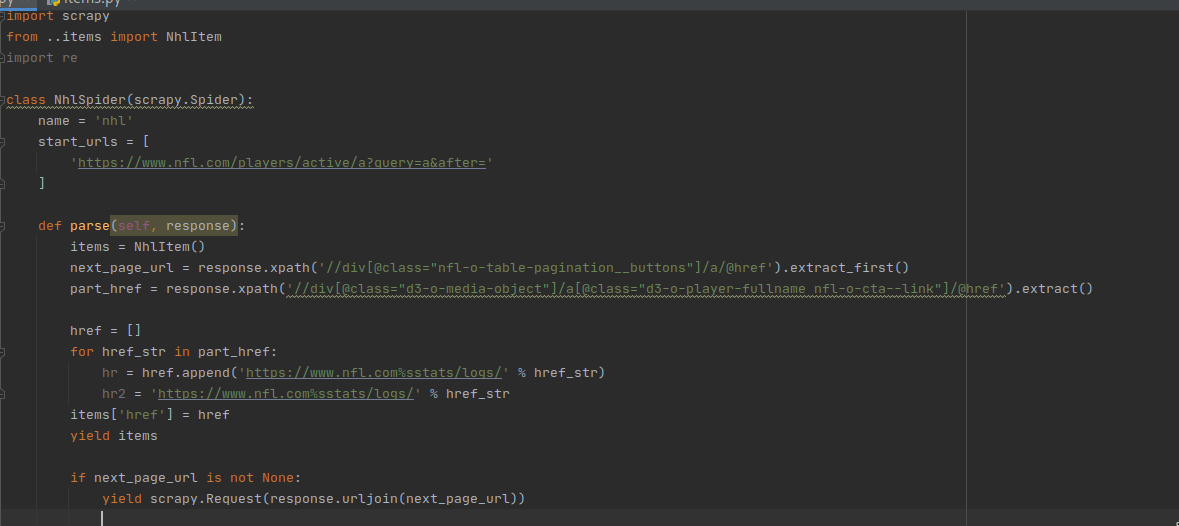
Ребят привет! Пытаюсь через apscheduler запустить паука через CrawlerProcess , использую TwistedSchaduler(), но как бы без разницы все перепробовал - виснет на telnet console listening on port . Никаких багов , ничего. Запускал в ручную паука все собирает и везде рассовывает как надо. Идеи закончились, что полезно показать? Или может кто то сталкивался?