c
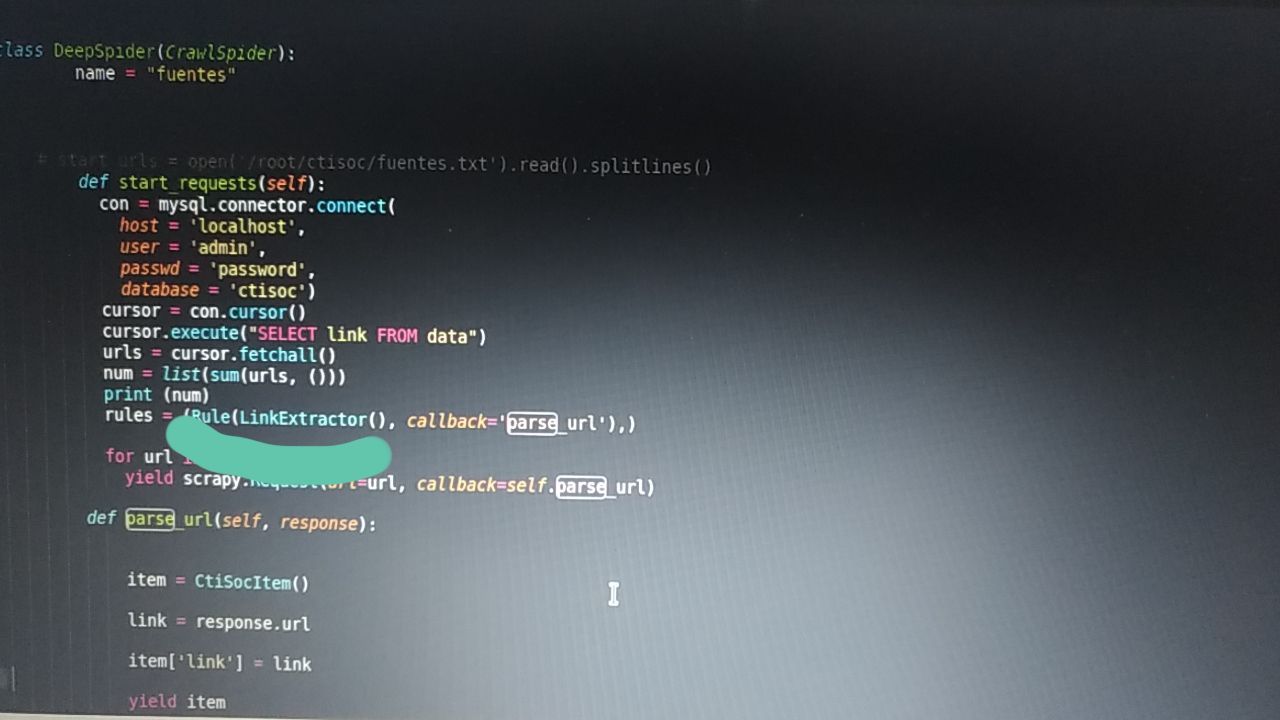
LinkExtractor doesn't work
Size: a a a
c
AR
c
AR
c
AR
AR
c
AR
c
AR
c
AR
c
AC
scrapy_selenium import SeleniumRequest но тогда некоторые домены не парсятся, а вот если напрямую в parse ф-ии обрабатывать урл с помощью selenium webdriver то гораздо больше доменов удается спарсить. Но минус в другом - создается 10к процессов хромаAБ
scrapy_selenium import SeleniumRequest но тогда некоторые домены не парсятся, а вот если напрямую в parse ф-ии обрабатывать урл с помощью selenium webdriver то гораздо больше доменов удается спарсить. Но минус в другом - создается 10к процессов хромаAБ
AБ