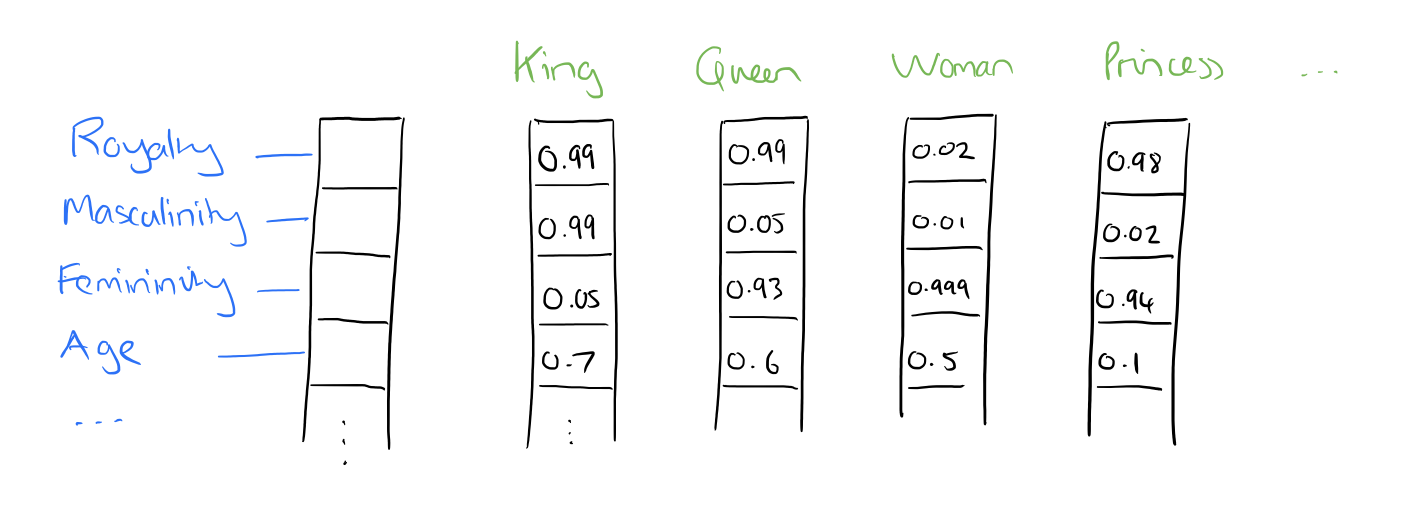
ок, вот тебе задача: закодировать 1М слов 100-мерными векторами так, чтобы а) разным словам соответствовали разные вектора б) рядом были слова, близкие друг к другу по смыслу
просто сколько тебе связей нейронов нужно будет после 1го слоя, чтобы твои полезные свойства выучить? из бинарного разбиения на 1 млн элементов и 1000 свойств — те же 1 млрд, не?
по сути, embedding — это и есть 1-hot представление + преобразование, только развёрнутое в другую сторону и хранящееся не в параметрах нейросети, а в отдельном месте.