В
статье автор сравнивает ETL и ELT. В канале я уже много раз ссылался на эти абреавиатуры. Согласно википедии, ETL уже используется с 1970х. Главное отличие ETL от ELT, что нам нужны вычислительные мощности (computing) чтобы, читать данные и трансформировать, то есть мы все данные пропускаем через приложение ETL. Поэтому это дорого (нужно сервер и нужно его обслуживать), во-вторых это может быть узким местом во времени обработки. Самые популярные решения это Informatica Power Center, MS SSIS, SAP BODI и другие аналоги от IBM, Oracle, SAS.
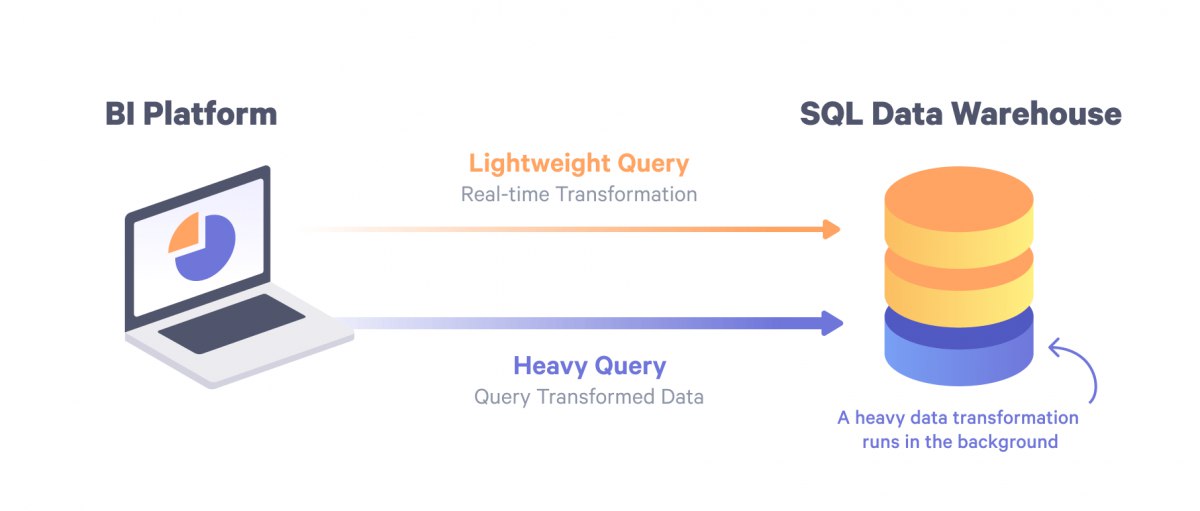
В противовес, есть концепт ELT, когда мы используем вычислительные мощности аналитического хранилища данных (Teradata, Exadata, Netezza, Redshift, Snowflake and so on). По сути все трансформации описаны с помощью SQL, а сам ELT иснтрумент оркестрируют, в какой очереди запускать трансформации и какие зависимости. Как результат, дешевле, быстрее и более гибкий.
В конце концов, не важно, что вы используете, лишь бы работало хорошо, обеспечивало SLA, проверяло качество загруженных данных и сообщало о поломках.
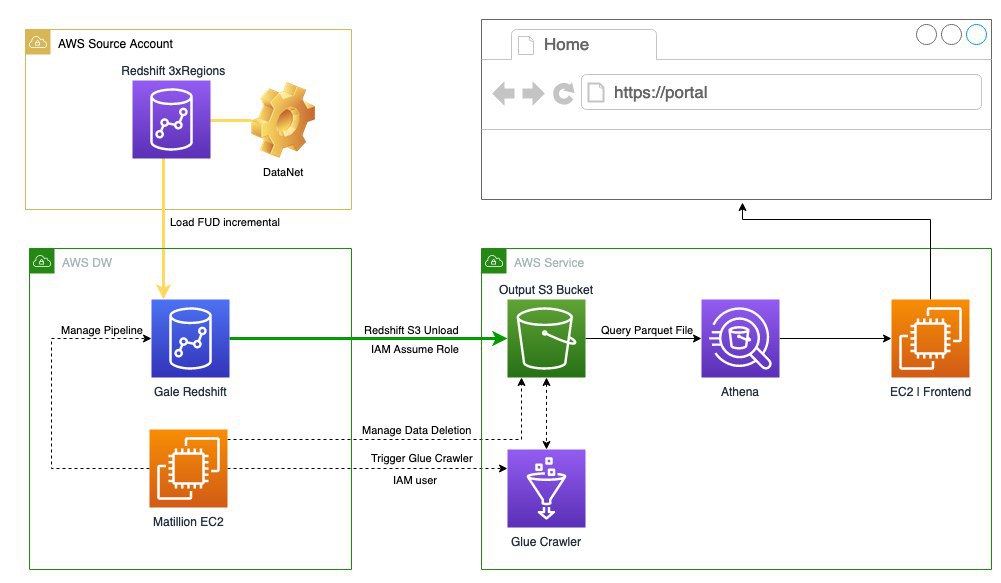
В Alexa я использую Matillion ETL для всех бизнес трансформаций и метрик. Наши product managers очень довольны, так как сами могу делать трансформации. Athena для SQL интерфейса в озеров данных на S3. Так же частично Amazon Glue для сбора метаданных озера данных. Из интересного, хотел бы использовать Apache Airflow, но нет времени с ним ковыряться.
Так же работаю иногна со Spark, когда много данных и нужно Big Data Computing. Причем трансформации описываю на SQL. Данные в озере данных всегда в Parquet формате и обязательно партиционированы. С новой фичей Redshift - UNLOAD to Parquet стало легче выгружать данные из Redshift в озеро данных.
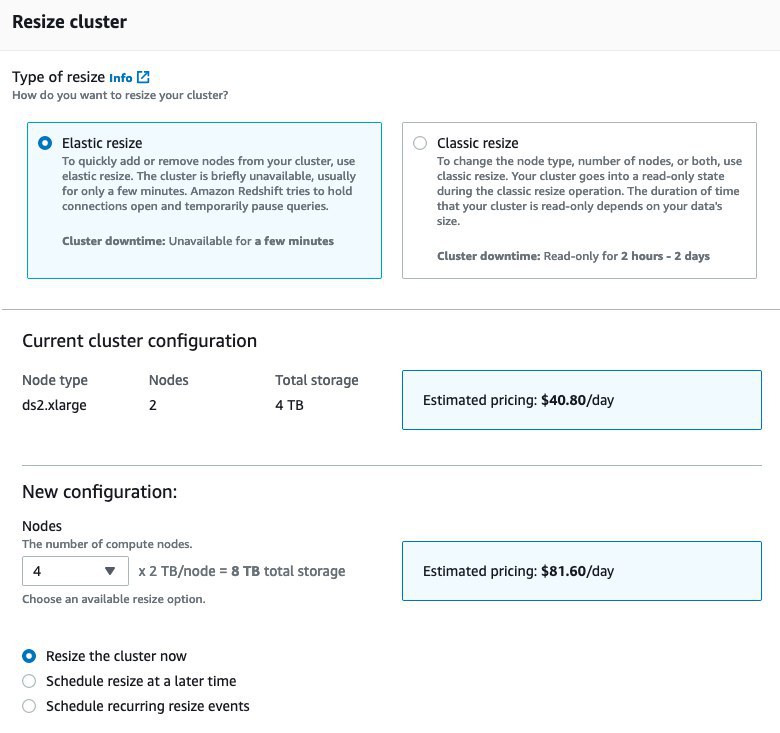
В в Alexa очень итересно с точки зрения данных, в качестве источника дынных для меня это Redshift 128 нод (максимальный размер) и озеро данных, то есть миллиарды строк, все это дело надо соединить и посчитать метрики качества на уровне событий и сохранить результат в своем кластере Redshift. А часть данных нады выгрузить в свое озеро данных для front end сервисов. Главная цель, помочь внутренним бизнес подразделениям выявлять проблемы в поведении Alexa и качества моделей.
PS хотел про ETL/ELT написать, а получась гораздо больше, теперь я точно могу сказать, я работал с большими данными, и они растут по экспоненте.