



Size: a a a
2021 March 02


2021 March 03
С каждым принятым решениям у нас есть выбор, двигаться вперед или оставить все как есть. Очень часто у нас открывается окно возможностей (opportunities), где нужно принять решение, иногда даже рискнуть. Именно из таких возможностей складывается наша жизнь и карьера.
В исходной точке в большинстве случаев у многих равные возможности, но со временем, одни уходят вперед, другие так и остаются на месте. Это касается работы, должности, инструментов мы используем, места жительства и тд. Я много общаюсь с разными людьми, и по привычке начинаю раздавать советы, иногда дельные, иногда не очень. Но по реакции человека, можно сразу понять насколько он/она открыты к возможностям и насколько готовы действовать. В 90% случаев, идеи и советы так и остаются идеями и бесполезными советами, но в 5-10% случаях человек может воспользоваться возможностью и без лишних вопросов “нырнуть” в неизвестное. Хуже не будет, но может стать значительно лучше.
Это у меня просто мысль проскочила, почему одни двигаются быстрей, а другие нет. Не бойтесь принимать решения, мы живем один раз, не откладывайте все на потом, действуйте и получайте все, что хотите! Вселенная вас услышит и направит, но финальный шаг за вами.
В исходной точке в большинстве случаев у многих равные возможности, но со временем, одни уходят вперед, другие так и остаются на месте. Это касается работы, должности, инструментов мы используем, места жительства и тд. Я много общаюсь с разными людьми, и по привычке начинаю раздавать советы, иногда дельные, иногда не очень. Но по реакции человека, можно сразу понять насколько он/она открыты к возможностям и насколько готовы действовать. В 90% случаев, идеи и советы так и остаются идеями и бесполезными советами, но в 5-10% случаях человек может воспользоваться возможностью и без лишних вопросов “нырнуть” в неизвестное. Хуже не будет, но может стать значительно лучше.
Это у меня просто мысль проскочила, почему одни двигаются быстрей, а другие нет. Не бойтесь принимать решения, мы живем один раз, не откладывайте все на потом, действуйте и получайте все, что хотите! Вселенная вас услышит и направит, но финальный шаг за вами.
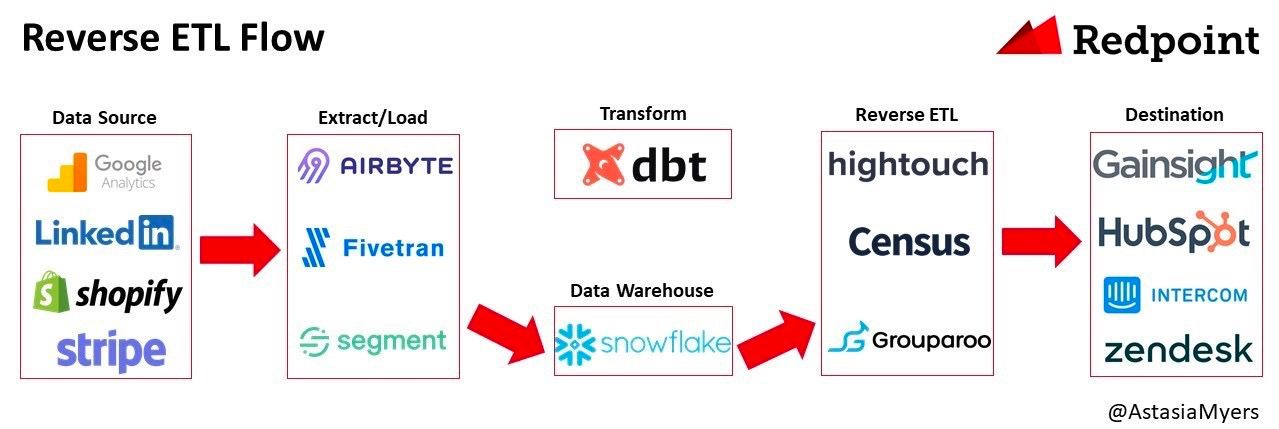
Открыл для себя новый термин - reverse ETL. Это когда нам нужно данные забирать из хранилища данных и загружать их в другие системы. Даже есть иснтрументы специально для этого;
Сегодня общался с командой Minecraft, дважды. Сначала с командой data engineers, о том какое у них решение. В целом практически все крупные студии использую решения “операционной аналитики” (ну это я так называю), к ним относятся решения Splunk, ElasticSearch+Logstash. Это когда инструмент пожирает данные на входе практически в реальном времени, и мы можем их искать. Часто используют слово Spelunking (это значит лазить в пещере с фонариком), как раз Splunk произошёл от этого слова. (Хочу засунуть splunk в курс datalearn обязательно).
В общем, для аналитики вместо традиционного подхода с хранилищем данных или платформой данных/озером данных у многих студий используется решение от Azure (Azure Data Explorer) с похожим принципом как у Splunk.
Но их data science команда уже кайфует от Databricks, и они поделились крутой ссылку по Best Practices для PySpark, которая была создана Palantir. На мой вопрос, хотели бы они, чтобы Databricks был и для Data Science и для Data Platfrom, все дружно закивали, значит, реально DataBricks это вещь💪
Еще оказалось, что аналитик Minecraft, раньше был в Amazon Game Studios, и часто бывал на мои ивентах Amazon Tableau User Groups и BI Tech Talks, за что очень благодарил😇
В общем, для аналитики вместо традиционного подхода с хранилищем данных или платформой данных/озером данных у многих студий используется решение от Azure (Azure Data Explorer) с похожим принципом как у Splunk.
Но их data science команда уже кайфует от Databricks, и они поделились крутой ссылку по Best Practices для PySpark, которая была создана Palantir. На мой вопрос, хотели бы они, чтобы Databricks был и для Data Science и для Data Platfrom, все дружно закивали, значит, реально DataBricks это вещь💪
Еще оказалось, что аналитик Minecraft, раньше был в Amazon Game Studios, и часто бывал на мои ивентах Amazon Tableau User Groups и BI Tech Talks, за что очень благодарил😇
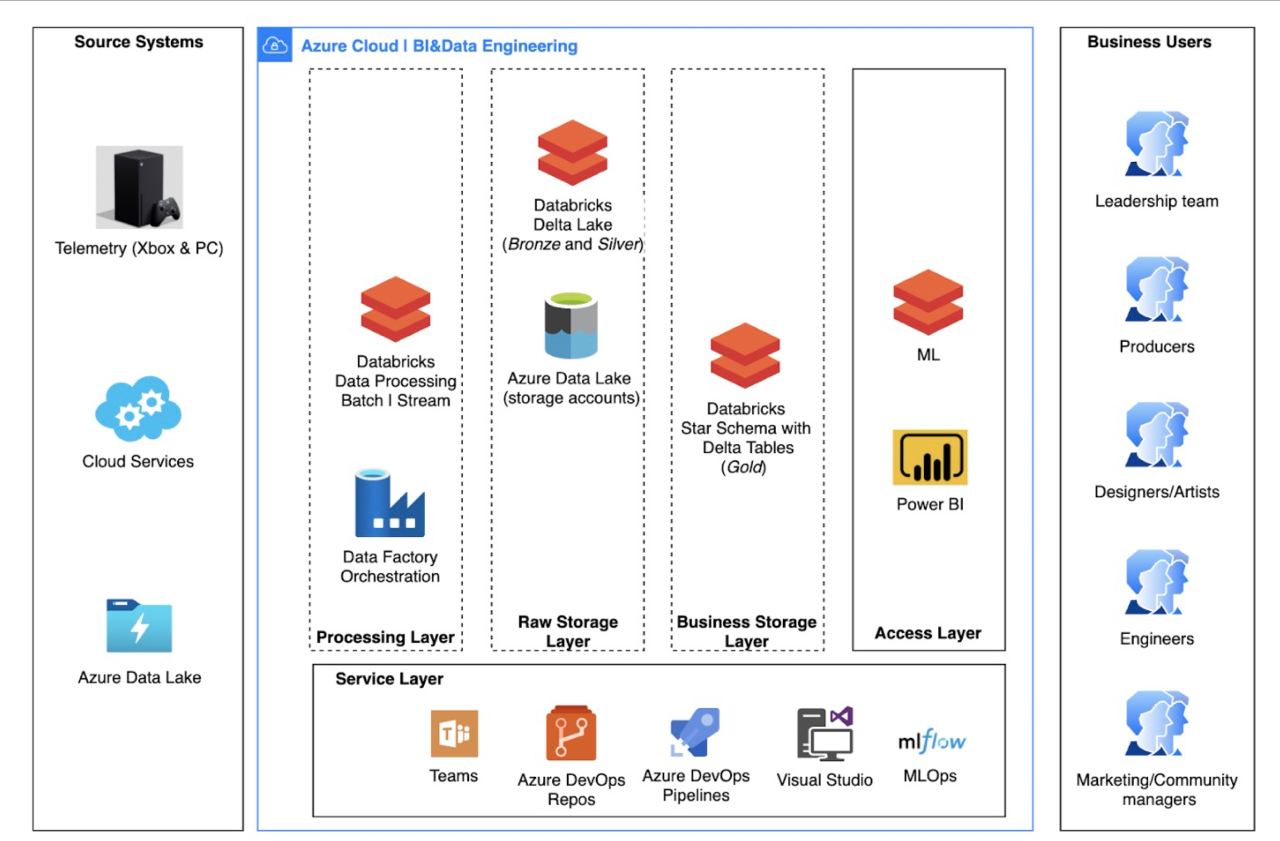
Вот над чем я буду работать следующий год-два
Еще один доклад про data-mesh. На этот раз от JP Morgan. То есть это для очень крупных организаций пока используется.

Основатель dbt в декабре написал длинный блог - The Modern Data Stack: Past, Present, and Future
Так же доступна видео запись с конференции https://youtu.be/1Zj8gTLdf5s
Он точно в теме современных технологий и потребностей.
Так же доступна видео запись с конференции https://youtu.be/1Zj8gTLdf5s
Он точно в теме современных технологий и потребностей.


Согласно автору и его презентации (ссылка выше), он выделил следующие проблемы, которые индустрия должна решить, в видео и в тексте, он рассказал почему так, и какие успехи у индустрии сейчас.
Интересно ваше мнение: Как вы относитесь к современным прививкам?
Анонимный опрос
Проголосовало: 700Не знаю как, но попалась такая статья, и я согласен с автором, особенно как родитель 3х детей https://news.obozrevatel.com/society/fenomen-morgenshterna-debilami-upravlyat-legko.htm
А вот информация по следующему вебинары, который уже будет в четверг (сегодня) в 7 часов вечера по Москве - “ВЫВОДЫ ЗА 10 ЛЕТ РАЗВИТИЯ ПРАКТИКИ QLIK “. Мы познакомились со спикером через мою статью про консалтинг компанию, но в отличие от моего опыта, дела у него обстоят хорошо, о чем он и расскажет.
Александр Гончар - эксперт решений Qlik согласился поделиться опытом и рассказать про возможности аналитического инструмента и своего опыта. Уже более 10 лет он руководит консалтинг компанией А2, которая занимается внедрение решений Qlik и решений бизнес аналитики в СНГ и Северной Америке.
Александр Гончар - эксперт решений Qlik согласился поделиться опытом и рассказать про возможности аналитического инструмента и своего опыта. Уже более 10 лет он руководит консалтинг компанией А2, которая занимается внедрение решений Qlik и решений бизнес аналитики в СНГ и Северной Америке.
2021 March 04

Сейчас начнется!
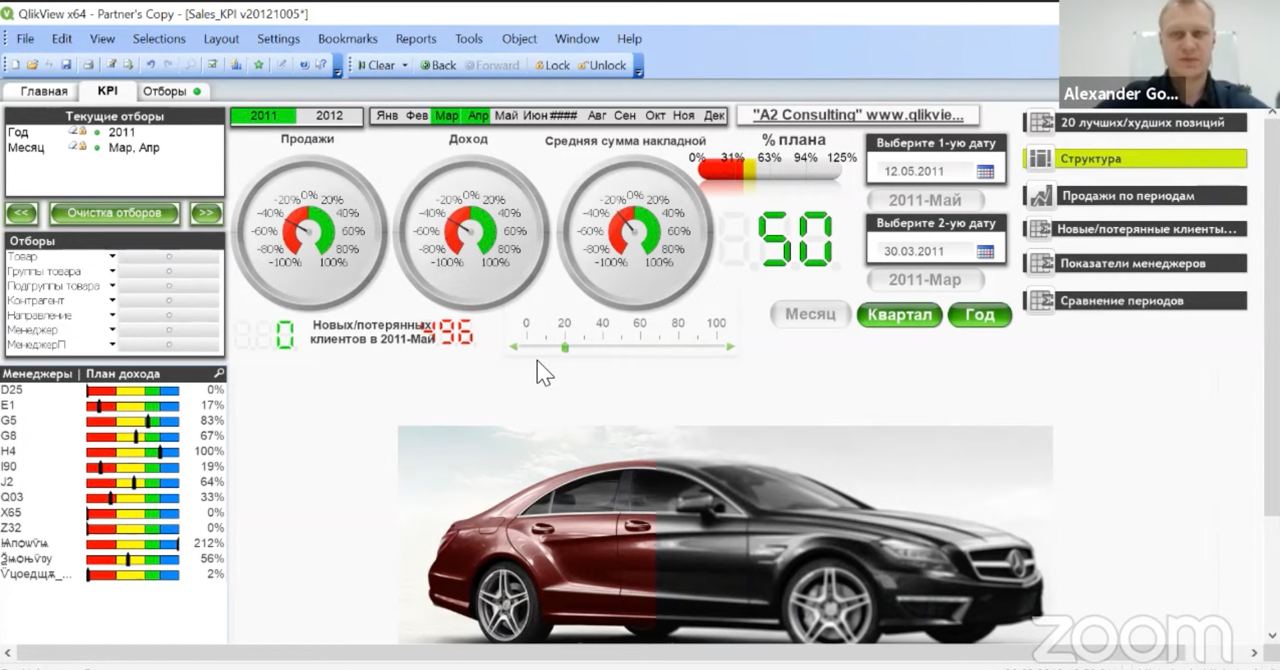
Дашборд Qlik в 2012 года, в котором CLS закрашивался в зависимости от выполнения плана. Мотивация для менеджера по продажам наверное))
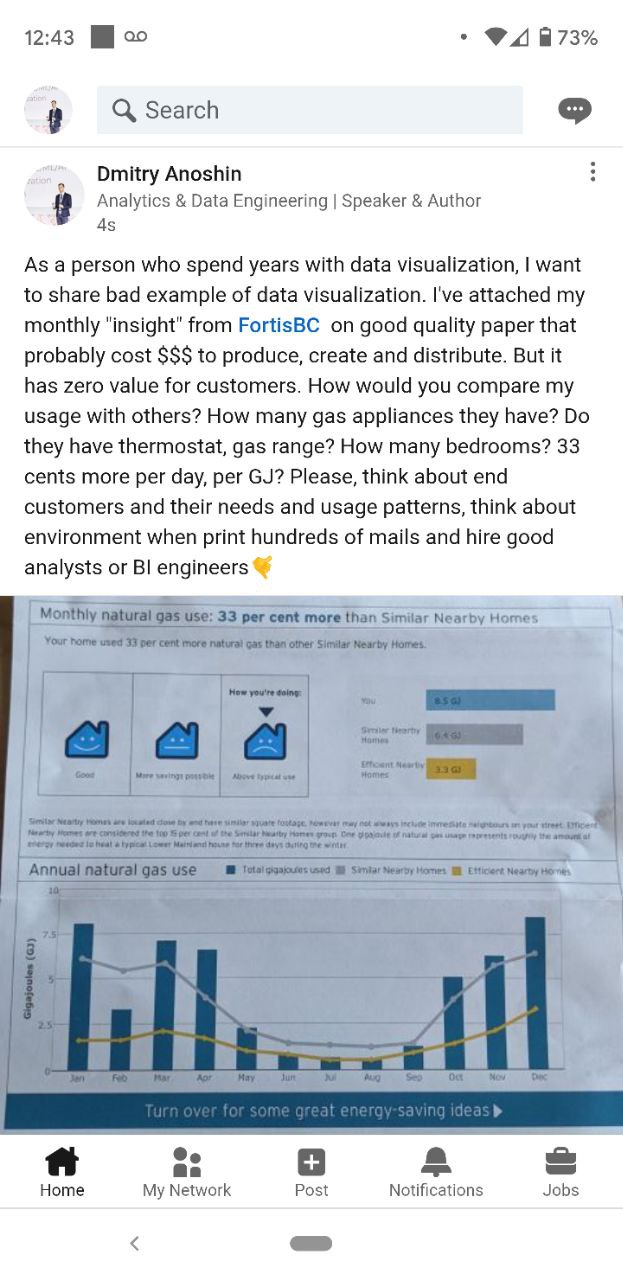
2021 March 05
А вот термин, которые активно развивается в Data Science/Machine Learning - Feature Store. То есть отдельное хранилище для наших атрибутов моделей. Большая статья тут про это.
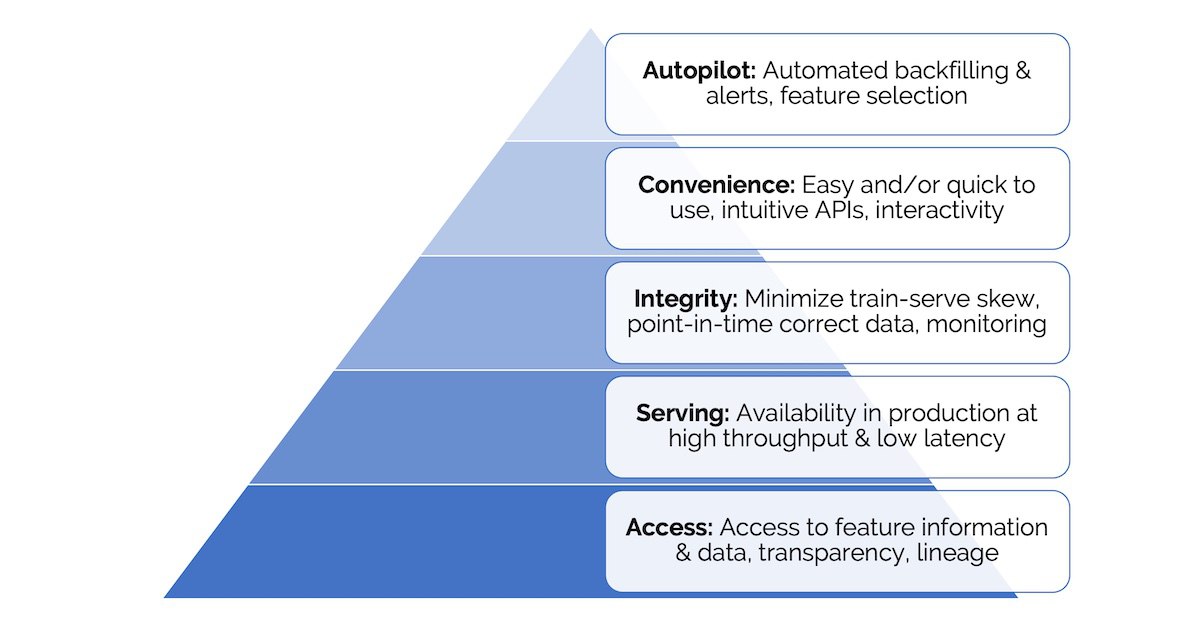
Что почитать на выходных
📄 Статья с основными принципами дизайна Нормана. Полезно и коротко. Где нашёл: Агентство ADN
▶️ Выступления команды DMP/DWH Яндекс Go на конференции Smart Data. Где нашёл: Под капотом Я.Такси
🗂 Подборка визуализаций сделанных в физическом воплощении. Где нашёл: Дата-виз чат
💡Дата-йога и Qlik запускают бесплатный марафон по data-literacy. Где нашёл: Чат Tableau
📄 Небольшая приятная статья про квартет Энскомба. Где нашёл: Настенька и графики
▶️ Выступление Димы Аношина про современный аналитический стек. Где нашёл: Инжиниринг данных
💼 Vizuators из Минска ищут себе разработчиков Tableau. Ребята очень прикольные, присмотритесь к ним. Где нашёл: KZ BI Community
#дайджест
📄 Статья с основными принципами дизайна Нормана. Полезно и коротко. Где нашёл: Агентство ADN
▶️ Выступления команды DMP/DWH Яндекс Go на конференции Smart Data. Где нашёл: Под капотом Я.Такси
🗂 Подборка визуализаций сделанных в физическом воплощении. Где нашёл: Дата-виз чат
💡Дата-йога и Qlik запускают бесплатный марафон по data-literacy. Где нашёл: Чат Tableau
📄 Небольшая приятная статья про квартет Энскомба. Где нашёл: Настенька и графики
▶️ Выступление Димы Аношина про современный аналитический стек. Где нашёл: Инжиниринг данных
💼 Vizuators из Минска ищут себе разработчиков Tableau. Ребята очень прикольные, присмотритесь к ним. Где нашёл: KZ BI Community
#дайджест
2021 March 06
Из нашего slack:
Всем привет! 8 марта будет такая конференция - "Women in Data Science Conference в Санкт-Петербурге"
https://wdl-hse.org/wids2021rus
Описание:
"Приглашаем вас на конференцию Women in Data Science St. Petersburg (WiDS'21 St. Petersburg), которая в этом году пройдет полностью онлайн (на площадке Zoom) в рамках инициативы Глобальной конференции женщин в науке о данных, организуемой в Стэнфордском университете и более чем на 200 площадках по всему миру.
Конференция направлена на развитие сообщества Data Science, приглашаются все желающие, без каких-либо ограничений по уровню подготовки, возрасту или полу. За один день конференции вы узнаете, что такое предиктивный анализ и как он используются в анализе сети ресторанов (Яна Одинцова). Также мы познакомимся с процессом семантического поиска на примере из индустрии (Луиза Сайфуллина, SILO AI) и поговорим об оценке качества образования в анализе данных (Ирина Богданова, СПб ЦОКОиИТ). С участницами карьерной панели (Луиза Сайфуллина, SILO AI, Элина Валеева, Meditivity, Ксения Певзнер, Okko, Евгения Ребрикова, Пивоваренная компания «Балтика») обсудим, что нужно, чтобы начать заниматься Data Science, где найти актуальную информацию для развития, обсудим на примерах наших участниц, как стать аналитиком данных. И, конечно, будет живая сессия вопросов-ответов -- не упустите шанс спросить то, что давно вас интересовало в Data Science. И конечно, вас ждет много возможностей узнать что-то новое, поделиться своим опытом и познакомиться с новыми людьми (да, онлайн это тоже делать можно).
Адрес
8 марта, 2021
ссылка в ZOOM"https://wdl-hse.org/wids2021rus
Описание:
"Приглашаем вас на конференцию Women in Data Science St. Petersburg (WiDS'21 St. Petersburg), которая в этом году пройдет полностью онлайн (на площадке Zoom) в рамках инициативы Глобальной конференции женщин в науке о данных, организуемой в Стэнфордском университете и более чем на 200 площадках по всему миру.
Конференция направлена на развитие сообщества Data Science, приглашаются все желающие, без каких-либо ограничений по уровню подготовки, возрасту или полу. За один день конференции вы узнаете, что такое предиктивный анализ и как он используются в анализе сети ресторанов (Яна Одинцова). Также мы познакомимся с процессом семантического поиска на примере из индустрии (Луиза Сайфуллина, SILO AI) и поговорим об оценке качества образования в анализе данных (Ирина Богданова, СПб ЦОКОиИТ). С участницами карьерной панели (Луиза Сайфуллина, SILO AI, Элина Валеева, Meditivity, Ксения Певзнер, Okko, Евгения Ребрикова, Пивоваренная компания «Балтика») обсудим, что нужно, чтобы начать заниматься Data Science, где найти актуальную информацию для развития, обсудим на примерах наших участниц, как стать аналитиком данных. И, конечно, будет живая сессия вопросов-ответов -- не упустите шанс спросить то, что давно вас интересовало в Data Science. И конечно, вас ждет много возможностей узнать что-то новое, поделиться своим опытом и познакомиться с новыми людьми (да, онлайн это тоже делать можно).
Адрес
8 марта, 2021
ссылка в ZOOM"
Всем привет! 8 марта будет такая конференция - "Women in Data Science Conference в Санкт-Петербурге"
https://wdl-hse.org/wids2021rus
Описание:
"Приглашаем вас на конференцию Women in Data Science St. Petersburg (WiDS'21 St. Petersburg), которая в этом году пройдет полностью онлайн (на площадке Zoom) в рамках инициативы Глобальной конференции женщин в науке о данных, организуемой в Стэнфордском университете и более чем на 200 площадках по всему миру.
Конференция направлена на развитие сообщества Data Science, приглашаются все желающие, без каких-либо ограничений по уровню подготовки, возрасту или полу. За один день конференции вы узнаете, что такое предиктивный анализ и как он используются в анализе сети ресторанов (Яна Одинцова). Также мы познакомимся с процессом семантического поиска на примере из индустрии (Луиза Сайфуллина, SILO AI) и поговорим об оценке качества образования в анализе данных (Ирина Богданова, СПб ЦОКОиИТ). С участницами карьерной панели (Луиза Сайфуллина, SILO AI, Элина Валеева, Meditivity, Ксения Певзнер, Okko, Евгения Ребрикова, Пивоваренная компания «Балтика») обсудим, что нужно, чтобы начать заниматься Data Science, где найти актуальную информацию для развития, обсудим на примерах наших участниц, как стать аналитиком данных. И, конечно, будет живая сессия вопросов-ответов -- не упустите шанс спросить то, что давно вас интересовало в Data Science. И конечно, вас ждет много возможностей узнать что-то новое, поделиться своим опытом и познакомиться с новыми людьми (да, онлайн это тоже делать можно).
Адрес
8 марта, 2021
ссылка в ZOOM"https://wdl-hse.org/wids2021rus
Описание:
"Приглашаем вас на конференцию Women in Data Science St. Petersburg (WiDS'21 St. Petersburg), которая в этом году пройдет полностью онлайн (на площадке Zoom) в рамках инициативы Глобальной конференции женщин в науке о данных, организуемой в Стэнфордском университете и более чем на 200 площадках по всему миру.
Конференция направлена на развитие сообщества Data Science, приглашаются все желающие, без каких-либо ограничений по уровню подготовки, возрасту или полу. За один день конференции вы узнаете, что такое предиктивный анализ и как он используются в анализе сети ресторанов (Яна Одинцова). Также мы познакомимся с процессом семантического поиска на примере из индустрии (Луиза Сайфуллина, SILO AI) и поговорим об оценке качества образования в анализе данных (Ирина Богданова, СПб ЦОКОиИТ). С участницами карьерной панели (Луиза Сайфуллина, SILO AI, Элина Валеева, Meditivity, Ксения Певзнер, Okko, Евгения Ребрикова, Пивоваренная компания «Балтика») обсудим, что нужно, чтобы начать заниматься Data Science, где найти актуальную информацию для развития, обсудим на примерах наших участниц, как стать аналитиком данных. И, конечно, будет живая сессия вопросов-ответов -- не упустите шанс спросить то, что давно вас интересовало в Data Science. И конечно, вас ждет много возможностей узнать что-то новое, поделиться своим опытом и познакомиться с новыми людьми (да, онлайн это тоже делать можно).
Адрес
8 марта, 2021
ссылка в ZOOM"

2021 March 07
Еще один пример, когда Data Science берет на вооружение техники из DW - блог про использование Data Vault.
А вот пару статей с Хабр про Data Vault (это альтернатива Dimensional Modelling):
Введение в Data Vault
Основы Data Vault
А вот пару статей с Хабр про Data Vault (это альтернатива Dimensional Modelling):
Введение в Data Vault
Основы Data Vault

2021 March 09
Смелое заявление, что будущее BI это open source! Все бы ничего, но только это написано от имени BI компании, которая создала коммерческий Apache Superset - Preset.
