



Size: a a a
2021 January 27


Сколько раз в год нужно ходить на собеседования, если вы НЕ в активном поиске? (Я бы ходил раз 8 при хорошей работе)
Анонимный опрос
Проголосовало: 698
Update по #datalearn:
1. Мне осталось 2 видео для модуля 4:
- 4.7 Fancy ETL для on-premise, в котором я хочу рассказать популярные решения на рынке (очень кратко) - Airflow, NiFi, dbt, Luigi, Dagster + попоулярную на отечественном рынке аналитическую БД Clickhouse. Так как у меня опыт с этим инструментами из разряда МНТ (метод научного тыка), то постараюсь импровизировать, впрочем как обычно. Но с удовольствием проведем вебинар по любому из этих инструментов.
- 4.8 Обзор вакансии ETL разработчик. Я хочу еще раз пройти про разницу (которая иногда отсутствует) между вакансиями ETL разработчик. Потом посмотрим требования, примеры вакансий на hh и за границей. Для опытных коллег, я хочу заметить, цель DataLearn дать необходимый минимум знаний для позиции ETL разработчик или для дополнительные знания для позиций BI разработчик или аналитик. Есть еще много вакансий, где используются классические ETL инструменты, реляционных базы данных и SQL. И чтобы начать шарашить pipeline на питоне, нужно понятно как все работает на более простом уровне, и потом уже можно усложнять. Ну это мое мнение. Как обычно welcome послушать опытных инженеров данных, особенно интересно, с чего они начинали.
Так же для модуля 4, Павел Новичков @eXtr1Mo запишет 3 видео (2 лабораторные работы по работе с Pentaho DI, работа с базой данных и использования техник dimensional modelling и обзор итогового проекта модуля 4)
2. Роман @rspon плотно занимается запуском еще 2х курсов для datalearn, которые крайне полезны для начинающих специалистов и они должны закрыть оставшиеся пробелы в подготовке к поиску первой работы в дата мире. Инструкторы уже себя очень хорошо зарекомендовали в сообществе datalearn. Так же на подходе много крайне интересных вебинаров и спикеров.
3. 5й модуль будет про Cloud Computing (облачные вычисления). Я постараюсь собрать информацию по курсам Azure, AWS, примеры лабораторных работ и сделаю его независимым от прошлых 4х модулей. Он поможет нам сделать переход из on-premise решения по аналитики к Cloud. Yandex и Mail вкладывают огромные ресурсы в развития отечественного облака, так что через какое-то время мы увидим большой спрос на таких специалистов. Даже сейчас есть спрос на AWS или GCP специалистов по аналитике на том же hh. И после модуля 5 мы уже перейдем к моей любимой теме - аналитическое хранилище в облаке, spark, озеро данных, Delta Lake и рассмотрим много облачных инструментов AWS и Azure, после чего вы сможете понять всем мои презентации и проекты, которые я делал в облаке.
1. Мне осталось 2 видео для модуля 4:
- 4.7 Fancy ETL для on-premise, в котором я хочу рассказать популярные решения на рынке (очень кратко) - Airflow, NiFi, dbt, Luigi, Dagster + попоулярную на отечественном рынке аналитическую БД Clickhouse. Так как у меня опыт с этим инструментами из разряда МНТ (метод научного тыка), то постараюсь импровизировать, впрочем как обычно. Но с удовольствием проведем вебинар по любому из этих инструментов.
- 4.8 Обзор вакансии ETL разработчик. Я хочу еще раз пройти про разницу (которая иногда отсутствует) между вакансиями ETL разработчик. Потом посмотрим требования, примеры вакансий на hh и за границей. Для опытных коллег, я хочу заметить, цель DataLearn дать необходимый минимум знаний для позиции ETL разработчик или для дополнительные знания для позиций BI разработчик или аналитик. Есть еще много вакансий, где используются классические ETL инструменты, реляционных базы данных и SQL. И чтобы начать шарашить pipeline на питоне, нужно понятно как все работает на более простом уровне, и потом уже можно усложнять. Ну это мое мнение. Как обычно welcome послушать опытных инженеров данных, особенно интересно, с чего они начинали.
Так же для модуля 4, Павел Новичков @eXtr1Mo запишет 3 видео (2 лабораторные работы по работе с Pentaho DI, работа с базой данных и использования техник dimensional modelling и обзор итогового проекта модуля 4)
2. Роман @rspon плотно занимается запуском еще 2х курсов для datalearn, которые крайне полезны для начинающих специалистов и они должны закрыть оставшиеся пробелы в подготовке к поиску первой работы в дата мире. Инструкторы уже себя очень хорошо зарекомендовали в сообществе datalearn. Так же на подходе много крайне интересных вебинаров и спикеров.
3. 5й модуль будет про Cloud Computing (облачные вычисления). Я постараюсь собрать информацию по курсам Azure, AWS, примеры лабораторных работ и сделаю его независимым от прошлых 4х модулей. Он поможет нам сделать переход из on-premise решения по аналитики к Cloud. Yandex и Mail вкладывают огромные ресурсы в развития отечественного облака, так что через какое-то время мы увидим большой спрос на таких специалистов. Даже сейчас есть спрос на AWS или GCP специалистов по аналитике на том же hh. И после модуля 5 мы уже перейдем к моей любимой теме - аналитическое хранилище в облаке, spark, озеро данных, Delta Lake и рассмотрим много облачных инструментов AWS и Azure, после чего вы сможете понять всем мои презентации и проекты, которые я делал в облаке.
👋 Друзья приветствую всех!
Приготовили для вас интересное событие, я бы даже сказал необычное...
👉 Завтра вебинар (четверг 28.01.2020) в 20:00 (мск).
👉 Тема вебинара: Развитие аналитического мышления.
👉Автор - аноним.
Опережая ваши мысли, скажу, что это не маркетинговый трюк с целью вас заманить, автор предпочел скрыть свои контакты и сказал, чтобы вы лучше вникли в инфу, которую он расскажет, а про него забыли.
👉 О чем будет вебинар:
Развитие аналитического мышления: если мы посмотрим на мозг как на компьютер (вычислительное устройство), то открываются интересные следствия и практические применения - растим переборную мощность, ставим правильный софт и лучшие стандартные библиотеки.
Речь пойдет про то, что было бы неплохо, чтобы аналитик умел думать, так как для аналитика - самое важное мозги.
Лично по мне тема очень интересная и нужная и необходимая...
👉 Что нужно сделать:
👉 Перейти по ссылке и поставить колокольчик, чтобы в четверг не пропустить
👉 Отложить все дела на понедельник
👉В четверг в 20:00 быть на вебинаре
Канал спикера - @antxt
Всех обнял, до встречи в эфире 🥳
🔔 И ПОДПИШИТЕСЬ НА НАШ ЮТУБ
https://youtu.be/7qVJO0-XdL4
Приготовили для вас интересное событие, я бы даже сказал необычное...
👉 Завтра вебинар (четверг 28.01.2020) в 20:00 (мск).
👉 Тема вебинара: Развитие аналитического мышления.
👉Автор - аноним.
Опережая ваши мысли, скажу, что это не маркетинговый трюк с целью вас заманить, автор предпочел скрыть свои контакты и сказал, чтобы вы лучше вникли в инфу, которую он расскажет, а про него забыли.
👉 О чем будет вебинар:
Развитие аналитического мышления: если мы посмотрим на мозг как на компьютер (вычислительное устройство), то открываются интересные следствия и практические применения - растим переборную мощность, ставим правильный софт и лучшие стандартные библиотеки.
Речь пойдет про то, что было бы неплохо, чтобы аналитик умел думать, так как для аналитика - самое важное мозги.
Лично по мне тема очень интересная и нужная и необходимая...
👉 Что нужно сделать:
👉 Перейти по ссылке и поставить колокольчик, чтобы в четверг не пропустить
👉 Отложить все дела на понедельник
👉В четверг в 20:00 быть на вебинаре
Канал спикера - @antxt
Всех обнял, до встречи в эфире 🥳
🔔 И ПОДПИШИТЕСЬ НА НАШ ЮТУБ
https://youtu.be/7qVJO0-XdL4

2021 January 28
Свежий пост, в нем сразу про DataOps, dbt, Snowflake и SCD.

2021 January 29

Ещё одна вакансия от Циан. И они конечно же поддержали vsevsevmeste.ru
Вакансия: Data engineer в Циане
(Москва/Питер/Удаленка)
Циан – крупнейший в России сервис для поиска недвижимости. 18 лет мы помогаем людям найти, сдать, продать жилье по всей России. Циан не просто сайт, это высокотехнологичная компания, которая входит в топ-10 лучших сайтов по недвижимости в мире.
Сейчас мы выводим нашу аналитику на новый уровень с точки зрения эффективности и ценности для Циан.
Используем стек технологий: Python 3.6, Scala, Hadoop-3.1.1, Spark-2.3.2, Spark Streaming, Hive, Kafka, Hbase, Cassandra, Redis.
Задачи, которые могут стать твоими:
🔹Real-time обработка и поставка больших данных в различные хранилища для быстрого доступа;
🔹Налаживание регулярных процессов подготовки и поставки данных для продуктовых команд и data scientist-ов;
🔹Разработка микросервисов на python/tornado для внедрения моделей машинного обучения в прод;
Подробнее о позиции и условиях: https://hh.ru/vacancy/38324558 Контакты для вопросов и резюме (Таня): t.lavrenteva@cian.ru, @tankiash - telegram.
(Москва/Питер/Удаленка)
Циан – крупнейший в России сервис для поиска недвижимости. 18 лет мы помогаем людям найти, сдать, продать жилье по всей России. Циан не просто сайт, это высокотехнологичная компания, которая входит в топ-10 лучших сайтов по недвижимости в мире.
Сейчас мы выводим нашу аналитику на новый уровень с точки зрения эффективности и ценности для Циан.
Используем стек технологий: Python 3.6, Scala, Hadoop-3.1.1, Spark-2.3.2, Spark Streaming, Hive, Kafka, Hbase, Cassandra, Redis.
Задачи, которые могут стать твоими:
🔹Real-time обработка и поставка больших данных в различные хранилища для быстрого доступа;
🔹Налаживание регулярных процессов подготовки и поставки данных для продуктовых команд и data scientist-ов;
🔹Разработка микросервисов на python/tornado для внедрения моделей машинного обучения в прод;
Подробнее о позиции и условиях: https://hh.ru/vacancy/38324558 Контакты для вопросов и резюме (Таня): t.lavrenteva@cian.ru, @tankiash - telegram.

2021 January 30

Начинаем нашу серию постов о 3 факторе эффективности работы data team - "Структура".
Подумал, что лучше всего будет провести мини-интервью с опытными специалистами, которые поработали и работают в компаниях разных размеров. Чтобы они рассказали, из каких ролей состоит их команда по работе с данными, и какие функции они выполняют. Пока написал около 6-7 человек. Возможно, ешё кому-то напишу и пообщаюсь:)
Серия постов будет в формате 1-2 мини-интервью на пост, чтобы не было каши.
Первым человеком, с которым я пообщался на эту тему, был Дмитрий Аношин - Role Senior Data Engineer в Microsoft (до этого 5 лет работал в Amazon). Дима дал краткую сводку по тому, на каких проектах он работал в Amazon, над чем сейчас работает в Microsoft, какие роли были в командах проектов и с какими проблемами в структуре он столкнулся.
Цитирую:
"Смотри: Amazon:
1) Amazon Marketplace: Role BI+Data Engineer, работал с BIE
В качестве BI:
- установка Tableau Server
- Миграция SQL+Excel отчетов на Tableau
- Self-Service implementation
- Office Hours + Training (Adoption of BI)
В качестве Data Engineer:
-Миграция on premise Oracle DW + PL/SQL ETL на Amazon Redshift, работал с DBA, SDE
-Поиск и выбор Cloud ETL -> Matillion ETL и миграция всего с PL/SQL на ETL + переработка бизнес логики
-Использование AWS EMR+Spark (PySpark) для решения задачи с обработкой веб логов, так как ETL+DW просто не вывозили объем. Результат Spark был в Parquet в S3 (по сути озеро данных) и доступ к нему был через Athena и Redshift Spectrum
- Streaming данных из DynamoDB в real-time через DynamoDB Streams + Kinesis Firehose + Glue
2) Amazon Alexa BI: Role Data Engineer, работал с Product Managers, SDE и BIE
- Внедрение ETL Matillion ETL
- Создание тестовой/боевой системы в ETL и DW (Amazon Redshift)
- Оптимизация Tableau Data Sources (в среднем по 150млн строк было в одном data source)
- Разработка новой платформы для Alexa c названием Sputnik. С использованием новых нод Redshift RA3. Объем данных планировался 120ТБ в год.
- Работал вместе с Data Science над созданием Alexa Churn модели; моя задача была масштабировать модель и подготовка данных на AWS SageMaker
3) Amazon Customer Behaviour Analytics: Role Data Engineer, работал с ML, Data Science + Product Managers
- создание Big Data системы для ML модели. По сути задача системы была - feature engineering, нужно было процедить 700ТБ данных за год (clickstream + backend). Использовали EMR+Spark, логика была на SparkSQL и иногда Scala.
- моя задача была автоматизация всей этой истории, ее безопасность, privacy (GDPR и тп), и качество данных через Spark библиотеку deeque
- Дальше они уже сами брали данные через GPU EC2 instance и строили нейронную сеть (deep learning)
4) Microsoft Xbox game studios: Role Sr. Data Engineer, работаю с BIE, ML, Producers (вместо Product Managers), Artists (designers) и инженерами (SDE).
-моя задача создать новую платформу под новую игру, планирую делать Delta Lake на Databricks (активно изучаю)
-сейчас пока все на HDInsight+Hive (процессинг сырых данных) + SQL Server (dimensional model)
-дашборды в Power BI (который я не люблю после Табло)
-также для операционной аналитики Azure Data Explorer (аналог Splunk и Elastic Search)
-активно используем Azure DevOps (Git + Pipelines) и Microsoft Visual Studio в качестве IDE. Разбираюсь в CI/CD, очень крутая тема конечно, но надо время, чтобы въехать."
Главная проблема в структуре, с которой Дима столкнулся - когда в одной команде работают и разработчики программного обеспечения, и дата-инженеры. Он, как дата-инженер, выступал за простоту решения в виде использования ETL-инструментов с графическим интерфейсом, которые при этом полностью решали задачу проекта, а разработчики больше выступали за использование кода. В общем, договориться было сложно)Это тормозило разработку решения и потом было сложно найти, кто прав, кто виноват.
Подумал, что лучше всего будет провести мини-интервью с опытными специалистами, которые поработали и работают в компаниях разных размеров. Чтобы они рассказали, из каких ролей состоит их команда по работе с данными, и какие функции они выполняют. Пока написал около 6-7 человек. Возможно, ешё кому-то напишу и пообщаюсь:)
Серия постов будет в формате 1-2 мини-интервью на пост, чтобы не было каши.
Первым человеком, с которым я пообщался на эту тему, был Дмитрий Аношин - Role Senior Data Engineer в Microsoft (до этого 5 лет работал в Amazon). Дима дал краткую сводку по тому, на каких проектах он работал в Amazon, над чем сейчас работает в Microsoft, какие роли были в командах проектов и с какими проблемами в структуре он столкнулся.
Цитирую:
"Смотри: Amazon:
1) Amazon Marketplace: Role BI+Data Engineer, работал с BIE
В качестве BI:
- установка Tableau Server
- Миграция SQL+Excel отчетов на Tableau
- Self-Service implementation
- Office Hours + Training (Adoption of BI)
В качестве Data Engineer:
-Миграция on premise Oracle DW + PL/SQL ETL на Amazon Redshift, работал с DBA, SDE
-Поиск и выбор Cloud ETL -> Matillion ETL и миграция всего с PL/SQL на ETL + переработка бизнес логики
-Использование AWS EMR+Spark (PySpark) для решения задачи с обработкой веб логов, так как ETL+DW просто не вывозили объем. Результат Spark был в Parquet в S3 (по сути озеро данных) и доступ к нему был через Athena и Redshift Spectrum
- Streaming данных из DynamoDB в real-time через DynamoDB Streams + Kinesis Firehose + Glue
2) Amazon Alexa BI: Role Data Engineer, работал с Product Managers, SDE и BIE
- Внедрение ETL Matillion ETL
- Создание тестовой/боевой системы в ETL и DW (Amazon Redshift)
- Оптимизация Tableau Data Sources (в среднем по 150млн строк было в одном data source)
- Разработка новой платформы для Alexa c названием Sputnik. С использованием новых нод Redshift RA3. Объем данных планировался 120ТБ в год.
- Работал вместе с Data Science над созданием Alexa Churn модели; моя задача была масштабировать модель и подготовка данных на AWS SageMaker
3) Amazon Customer Behaviour Analytics: Role Data Engineer, работал с ML, Data Science + Product Managers
- создание Big Data системы для ML модели. По сути задача системы была - feature engineering, нужно было процедить 700ТБ данных за год (clickstream + backend). Использовали EMR+Spark, логика была на SparkSQL и иногда Scala.
- моя задача была автоматизация всей этой истории, ее безопасность, privacy (GDPR и тп), и качество данных через Spark библиотеку deeque
- Дальше они уже сами брали данные через GPU EC2 instance и строили нейронную сеть (deep learning)
4) Microsoft Xbox game studios: Role Sr. Data Engineer, работаю с BIE, ML, Producers (вместо Product Managers), Artists (designers) и инженерами (SDE).
-моя задача создать новую платформу под новую игру, планирую делать Delta Lake на Databricks (активно изучаю)
-сейчас пока все на HDInsight+Hive (процессинг сырых данных) + SQL Server (dimensional model)
-дашборды в Power BI (который я не люблю после Табло)
-также для операционной аналитики Azure Data Explorer (аналог Splunk и Elastic Search)
-активно используем Azure DevOps (Git + Pipelines) и Microsoft Visual Studio в качестве IDE. Разбираюсь в CI/CD, очень крутая тема конечно, но надо время, чтобы въехать."
Главная проблема в структуре, с которой Дима столкнулся - когда в одной команде работают и разработчики программного обеспечения, и дата-инженеры. Он, как дата-инженер, выступал за простоту решения в виде использования ETL-инструментов с графическим интерфейсом, которые при этом полностью решали задачу проекта, а разработчики больше выступали за использование кода. В общем, договориться было сложно)Это тормозило разработку решения и потом было сложно найти, кто прав, кто виноват.
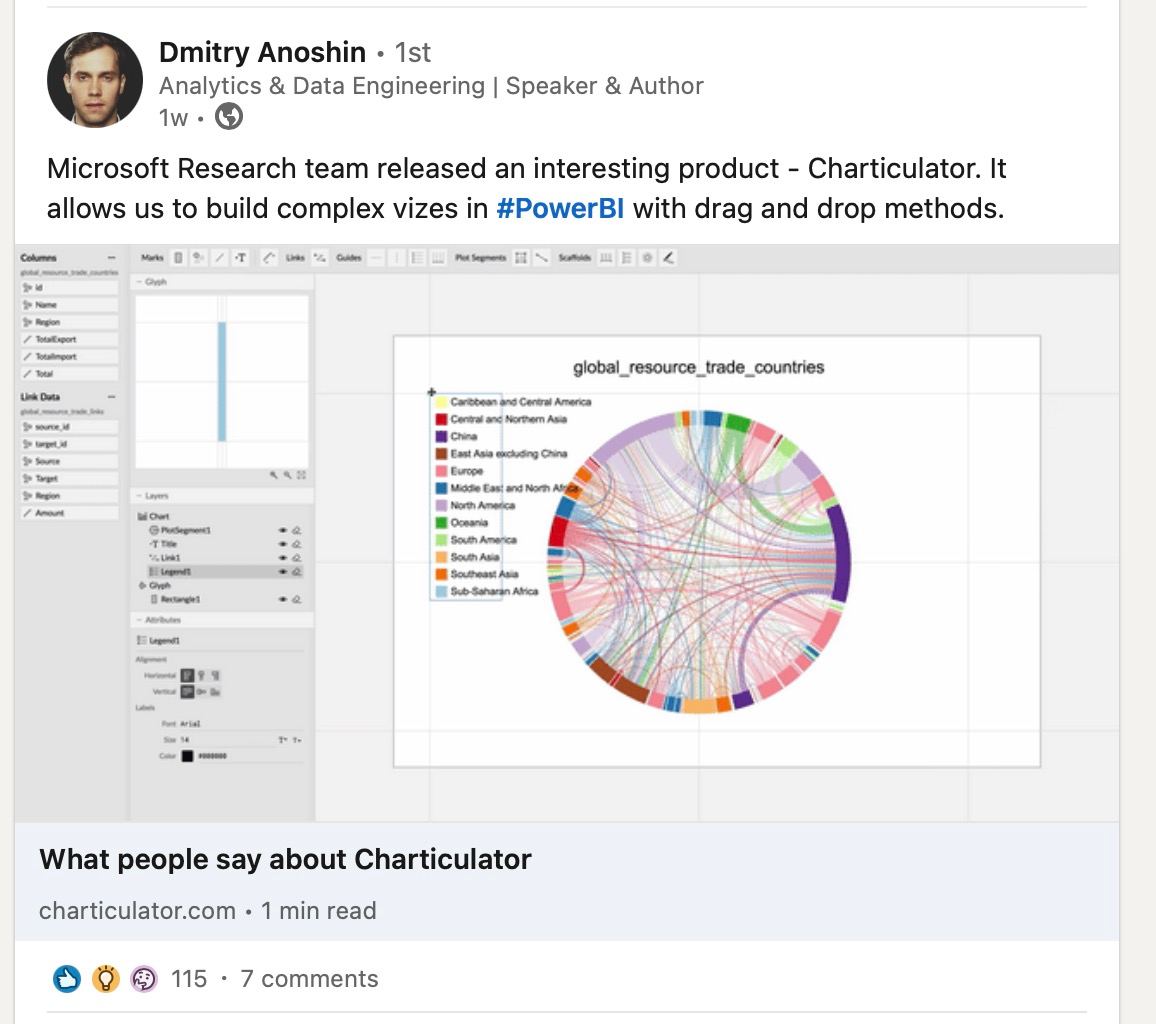
Я часто добавляю что-то в Linkedin. Но только 2 темы набирают больше 100 лайков, это PowerBI и Snowflake. Но Power BI явно популярней. Для сравнения, в среднем посты набирают 10 лайков, иногда 50. Но вот, чтобы 100+ было всего несколько раз. Я вообще склоняюсь, что Linkedin бесполезен.
Пока я пытался научиться кататься на лыжах, Анастасия выложила первый урок своего курса:
📌 Немного информации по курсу: Как проходить курс? Как будет проходить процесс обучения?
📌 Немного вводной информации про Искусственный Интеллект (AI), Машинное обучение (ML) и Data Science;
📌 AI и его подвиды;
📌 Виды ML (Supervised, Unsupervised, Semi-supervised and Reinforcement Learning);
📌 Data with/without Labels или Размеченные и Неразмеченные данные;
📌 Какие задачи можно решить с помощью ML (Recommendation, Ranking, Regression, Classification, Clustering, Anomaly Detection) ;
📌 Что такое Жизненный Цикл ML (ML Lifecycle) и как он работает.
Если вы не планируете проходить курс и вы очень далеки от темы ML/AI. Я вам очень рекомендую посмотреть это видео, Настя рассказала простым языком, что обозначают термины, и как это дело работает.
https://youtu.be/Cf_Yys2VHS4
📌 Немного информации по курсу: Как проходить курс? Как будет проходить процесс обучения?
📌 Немного вводной информации про Искусственный Интеллект (AI), Машинное обучение (ML) и Data Science;
📌 AI и его подвиды;
📌 Виды ML (Supervised, Unsupervised, Semi-supervised and Reinforcement Learning);
📌 Data with/without Labels или Размеченные и Неразмеченные данные;
📌 Какие задачи можно решить с помощью ML (Recommendation, Ranking, Regression, Classification, Clustering, Anomaly Detection) ;
📌 Что такое Жизненный Цикл ML (ML Lifecycle) и как он работает.
Если вы не планируете проходить курс и вы очень далеки от темы ML/AI. Я вам очень рекомендую посмотреть это видео, Настя рассказала простым языком, что обозначают термины, и как это дело работает.
https://youtu.be/Cf_Yys2VHS4

2021 January 31
Под бизнес-ориентированностью я полагаю умение смотреть на свою работу с точки зрения эффективности бизнеса заказчика и бизнеса компании, в которой вы работаете. Я люблю упоминать именно этот термин, а не "Клиентоориентированность", так как для меня клиентоориентированность - это всегда следовать правилу "клиент всегда прав". Я не согласен с таким подходом, так как заказчик нанимает вас как экспертов, а не рабочие руки, которые просто выполняют то, что он говорит. Если вы не согласны с заказчиком и считаете, что есть более оптимальный вариант решения для его бизнеса, нужно ему об этом сказать, опираясь на цифры, кейсы и лучшие практики рынка. Это и есть бизнес-ориентированность.
Проверить это качество у кандидата можно простым моделированием бизнес-ситуации. Например, вы выступаете в роли заказчика, а кандидат - в роли исполнителя. Вы можете предложить какое-то даже абсурдное решение и сказать: "Вот, я хочу сделать вот так". Вот здесь как раз и раскрывается компетентность и потенциал кандидата. Можно посмотреть, согласится он с вами или предложит другое решение и будет отстаивать его, опираясь на цифры, факты и кейсы, при этом сохраняя к вам уважение.
Я однажды собеседовался в компанию, и как раз на этом посыпался. Директор компании сказал, что мне не хватает критического мышления. Я был очень расстроен тогда сначала, а потом осознал, что мне указали на мой недостаток, и это может быть точкой роста. Это собеседование стало переломным для меня, и сейчас я всегда стараюсь вступать в конструктивную дискуссию, если я с чем то не согласен, и стараюсь искать всегда оптимальные решения для бизнеса.
Теперь о честности. Честность сложно проверить какими-то тестами. Разве что вы владеете психоанализом:))
Чтобы определить, честен с вами человек или нет, нужно обладать большим опытом и хорошей интуицией. Уметь чувствовать людей. Вообще я считаю интуицию - одним из главных качеств хорошего руководителя.
Проактивность. Для меня проактивность - это выход за рамки должностных инструкций. Когда вы не просто выполняете свою работу, а думаете о том, как улучшить продукт, оптимизировать процесс работы (как своей, так и компании).
На собеседованиях можно спросить у человека, как он пытался улучшить продукт или процесс, что он для этого делал, с какими проблемами столкнулся. Обычно проактивный человек будет рассказывать об этом в подробностях и не будет "лить воду".
Стремление к саморазвитию. Очень важное качество, я бы сказал - движущая сила сотрудников. Если люди постоянно стремятся развивать свои софт и хард-скиллы, шансы на рост компании увеличиваются в десятки раз.
На собеседованиях можно спрашивать у кандидата, как он совершенствует свои навыки, какие книги или статьи он читает, какие видео смотрит, как тренирует свои навыки и т.д. При этом вопросы лучше задавать в формате "Какую последнюю книгу вы прочитали? Какие выводы сделали?", "Какую статью прочитали, с чем были не согласны?" Так как есть кандидаты, которые любят врать на собеседованиях:) А такие вопросы могут застать врасплох.
Думаю, тему раскрыл.
P.S. Про все факторы эффективности более подробно можно прочитать в книге "Идеальный руководитель" Ицхака Адизеса. Про общие взгляды и ценности там целых 2 главы)
P.S.S. Следующий пост будет посвящён технологиям и инструментам, которые имеет смысл применять на определённой стадии развития онлайн-бизнеса.
Проверить это качество у кандидата можно простым моделированием бизнес-ситуации. Например, вы выступаете в роли заказчика, а кандидат - в роли исполнителя. Вы можете предложить какое-то даже абсурдное решение и сказать: "Вот, я хочу сделать вот так". Вот здесь как раз и раскрывается компетентность и потенциал кандидата. Можно посмотреть, согласится он с вами или предложит другое решение и будет отстаивать его, опираясь на цифры, факты и кейсы, при этом сохраняя к вам уважение.
Я однажды собеседовался в компанию, и как раз на этом посыпался. Директор компании сказал, что мне не хватает критического мышления. Я был очень расстроен тогда сначала, а потом осознал, что мне указали на мой недостаток, и это может быть точкой роста. Это собеседование стало переломным для меня, и сейчас я всегда стараюсь вступать в конструктивную дискуссию, если я с чем то не согласен, и стараюсь искать всегда оптимальные решения для бизнеса.
Теперь о честности. Честность сложно проверить какими-то тестами. Разве что вы владеете психоанализом:))
Чтобы определить, честен с вами человек или нет, нужно обладать большим опытом и хорошей интуицией. Уметь чувствовать людей. Вообще я считаю интуицию - одним из главных качеств хорошего руководителя.
Проактивность. Для меня проактивность - это выход за рамки должностных инструкций. Когда вы не просто выполняете свою работу, а думаете о том, как улучшить продукт, оптимизировать процесс работы (как своей, так и компании).
На собеседованиях можно спросить у человека, как он пытался улучшить продукт или процесс, что он для этого делал, с какими проблемами столкнулся. Обычно проактивный человек будет рассказывать об этом в подробностях и не будет "лить воду".
Стремление к саморазвитию. Очень важное качество, я бы сказал - движущая сила сотрудников. Если люди постоянно стремятся развивать свои софт и хард-скиллы, шансы на рост компании увеличиваются в десятки раз.
На собеседованиях можно спрашивать у кандидата, как он совершенствует свои навыки, какие книги или статьи он читает, какие видео смотрит, как тренирует свои навыки и т.д. При этом вопросы лучше задавать в формате "Какую последнюю книгу вы прочитали? Какие выводы сделали?", "Какую статью прочитали, с чем были не согласны?" Так как есть кандидаты, которые любят врать на собеседованиях:) А такие вопросы могут застать врасплох.
Думаю, тему раскрыл.
P.S. Про все факторы эффективности более подробно можно прочитать в книге "Идеальный руководитель" Ицхака Адизеса. Про общие взгляды и ценности там целых 2 главы)
P.S.S. Следующий пост будет посвящён технологиям и инструментам, которые имеет смысл применять на определённой стадии развития онлайн-бизнеса.

2021 February 01
Ух, как мы мощно начали 2021! Я всегда говорю, главная цель #datalearn - это достижение результата и трудоустройство. Благодаря Анастасии Дробышевей, профессионального консультант по рынку труда и карьерному развитию и ее инициативы мы добавили еще один убойный курс - Поиск работы для аналитических специальностей в России и за рубежом, сокращенно Job Hunting - 101 (JH - 101).
За 10 лет Анастасия провела более 2 000 карьерных консультаций, специализируется на IT/ digital, internet & e-commerce. Использует лучшие международные практики, полученные в работе с крупными американскими компаниями. В 2017 г. переехала из России в Словению, поэтому не понаслышке знает о поиске работы за границей.
Задача курса ー описать весь процесс поиска работы и дать вам инструменты для самостоятельного джобхантинга в любой стране.
Для кого курс:
📌Для кого этот курс?!Учебный курс подойдёт для аналитиков данных, инженеров данных, Data Scientist и других смежных профессий.
📌Вы узнаете о 5 этапах поиска работы от постановки цели до подписания трудового договора.
📌Разберем алгоритмы действий на каждом шаге поиска, каналы поиска работы и технологии нетворкинга.
📌Рассмотрим примеры формулировок в Резюме и профиле LinkedIn, готовые скрипты и шаблоны для переписки.
📌В финальной части обсудим, как говорить о зарплате и улучшить условия оффера.
📌В результате обучения вы сможете самостоятельно искать работу в любой стране и выстраивать процесс под свои задачи.
Содержание курса:
📌Урок 1. Стратегия поиска работы - Как грамотно спланировать поиск и поставить цель, опираясь на реалии рынка труда и свои сильные стороны.
📌Урок 2. Маркетинговые материалы - Как сделать сильное Резюме, настроить профили на LinkedIn и GitHub.
📌Урок 3. Поиск вакансий и отклики - Где искать вакансии в России и в других странах. Что делать, чтобы работодатель вас заметил.
📌Урок 4. Нетворкинг - Как развивать свой личный бренд, дружить с нужными людьми и укреплять социальные связи для успешного поиска работы.
📌Урок 5. Интервью и обсуждение оффера - Что важно на каждом этапе интервью и как себя лучше продать. Что хотят от кандидата FAANG-компаний.
📌 Bonus Track: Как не выгореть в процессе и Чек-лист готовности к поиску
Теперь у вас будет абсолютно все, чтобы
а) найти свою первую работу
б) сменить деятельность и начать работать с данными
в) подготовиться к собеседование в любой точке мира, включая компании FAANG
Регистрируйтесь, общайтесь в нашем Slack и помогайте друг другу быть успешней и лучше!
За 10 лет Анастасия провела более 2 000 карьерных консультаций, специализируется на IT/ digital, internet & e-commerce. Использует лучшие международные практики, полученные в работе с крупными американскими компаниями. В 2017 г. переехала из России в Словению, поэтому не понаслышке знает о поиске работы за границей.
Задача курса ー описать весь процесс поиска работы и дать вам инструменты для самостоятельного джобхантинга в любой стране.
Для кого курс:
📌Для кого этот курс?!Учебный курс подойдёт для аналитиков данных, инженеров данных, Data Scientist и других смежных профессий.
📌Вы узнаете о 5 этапах поиска работы от постановки цели до подписания трудового договора.
📌Разберем алгоритмы действий на каждом шаге поиска, каналы поиска работы и технологии нетворкинга.
📌Рассмотрим примеры формулировок в Резюме и профиле LinkedIn, готовые скрипты и шаблоны для переписки.
📌В финальной части обсудим, как говорить о зарплате и улучшить условия оффера.
📌В результате обучения вы сможете самостоятельно искать работу в любой стране и выстраивать процесс под свои задачи.
Содержание курса:
📌Урок 1. Стратегия поиска работы - Как грамотно спланировать поиск и поставить цель, опираясь на реалии рынка труда и свои сильные стороны.
📌Урок 2. Маркетинговые материалы - Как сделать сильное Резюме, настроить профили на LinkedIn и GitHub.
📌Урок 3. Поиск вакансий и отклики - Где искать вакансии в России и в других странах. Что делать, чтобы работодатель вас заметил.
📌Урок 4. Нетворкинг - Как развивать свой личный бренд, дружить с нужными людьми и укреплять социальные связи для успешного поиска работы.
📌Урок 5. Интервью и обсуждение оффера - Что важно на каждом этапе интервью и как себя лучше продать. Что хотят от кандидата FAANG-компаний.
📌 Bonus Track: Как не выгореть в процессе и Чек-лист готовности к поиску
Теперь у вас будет абсолютно все, чтобы
а) найти свою первую работу
б) сменить деятельность и начать работать с данными
в) подготовиться к собеседование в любой точке мира, включая компании FAANG
Регистрируйтесь, общайтесь в нашем Slack и помогайте друг другу быть успешней и лучше!
Если у вас есть много времени и вы хотите разобраться в построение распределенных системе, то вы можете ознакомится с лекциями MIT. -> MIT 6.824: Distributed Systems (Spring 2020)

Мне нравятся параллели с прошлым. Многое из того, что используем сейчас было сделано давно, но только сейчас становиться популярным. Ссылка: https://thenewstack.io/apache-iceberg-a-different-table-design-for-big-data/
Кто-то работал с Iceberg?
Кто-то работал с Iceberg?

А это CEO Snowflake на обложке Forbes. Я про него читал, он иммигрант из Нидерландов. Он такой, настоящий ковбой, знает, что хочет и добивается. Явно полная противоположность Сатии CEO Microsoft. Я читал, что до Snowflake он уже был на пенсии, тусил с семьей на яхте, и согласился возглавить снежинку, и теперь миллиардер. Я кстати тоже 1000$ заработал на росте акции, с момента IPO.
https://www.forbes.com/sites/alexkonrad/2021/02/01/the-outsider/
https://www.forbes.com/sites/alexkonrad/2021/02/01/the-outsider/