Мне поручили разобраться с новой фичей Power BI -
Deployment Pipelines. Разобрался, теперь могу вам рассказать.
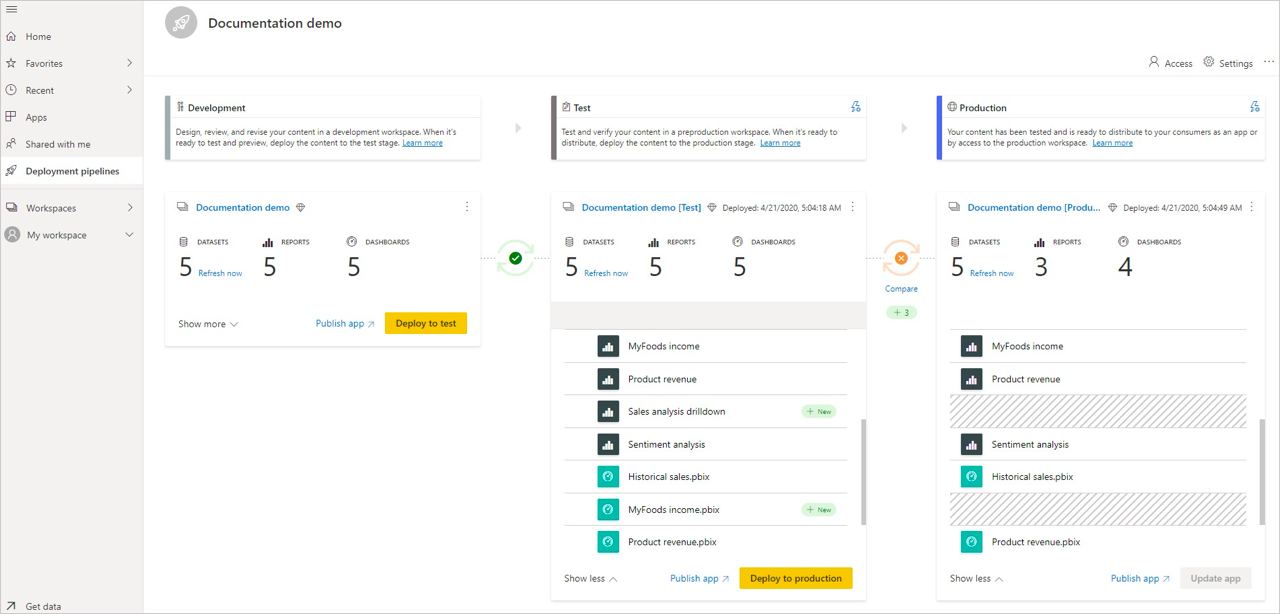
В Power BI Service есть новое меню - Deployment Pipelines. Идея позаимствована из Azure Devopes, там тоже есть Pipeline. Эта фича очень сырая. Она позволяет использовать 3 среды (3 Workspace, все должны быть Premium) - Dev, Test и Prod.
Есть 2 сценария:
1) Наш существующий Workspace мы можем клонировать “назад” в Test и Dev. (При этом среда Test и Dev создадутся для нас).
2) Мы можем создать среду Dev, и с нее начать “deployment” на Test и Prod.
То есть, теперь есть возможность разделить среду разработки, тестирования и боевую. И дальше мы можем promote из одной среду в другую. Power BI будет сравнивать объекты (например отчеты, модели) и говорить нам, если расхождения.
Для каждого workspace мы можем дать права и роли. И наконец, мы можешь иметь разные подключения к базе данных, среда Dev будет подключена к базе данных на dev, а Prod и Test мы подключим к базе данных Prod. Я использовал SQL Server on-premise, и поэтому у нас есть gateway. Для того, чтобы изменить параметры подключения к SQL Server, в Power BI Desktop я заменил Host/database в строке подключения на параметры, которые можно заменить в deployment pipelines.
В целом идея хорошая, но очень сырая. Если отчетов 20-30, то еще нормально, а вот если их несколько сотен, я вообще не представляю, как можно справиться. Так же совершенно непонятно, как сравнивать объекты, но разные и разные, а чем разные не говорит. Версионность объектов тоже не поддерживает.
Но посыл хороший. В других BI я такого не встречал. Думаю доделают, докрутят и будет все чики-пики))) Для меня 2 главных преимущества:
1) BI команда, будет разделять dev и prod базы данных, и это будет обязательным упражнением, больше не будет shortcuts.
2) В боевой workspace у нас не будет мусора, а только актуальные отчеты.
PS вопрос по Power BI, как я могу получить статистику использования отчетов? Сколько просмотров и тп?