укажите верное утверждение: -мощность и ошибка 2-го рода это одно и тоже; - p-value и вероятность ошибки 1-го рода это одно и тоже ; -p-value и вероятность ошибки 2-го рода это одно и тоже; - уровень значимости и вероятность ошибки 1-го рода это одно и тоже.
Я бы сказал, что тут нет верных утверждений вообще. Второе утверждение верно при дополнении "при условии, что в реальности верна нулевая гипотеза", что нам неизвестно.
Я бы сказал, что тут нет верных утверждений вообще. Второе утверждение верно при дополнении "при условии, что в реальности верна нулевая гипотеза", что нам неизвестно.
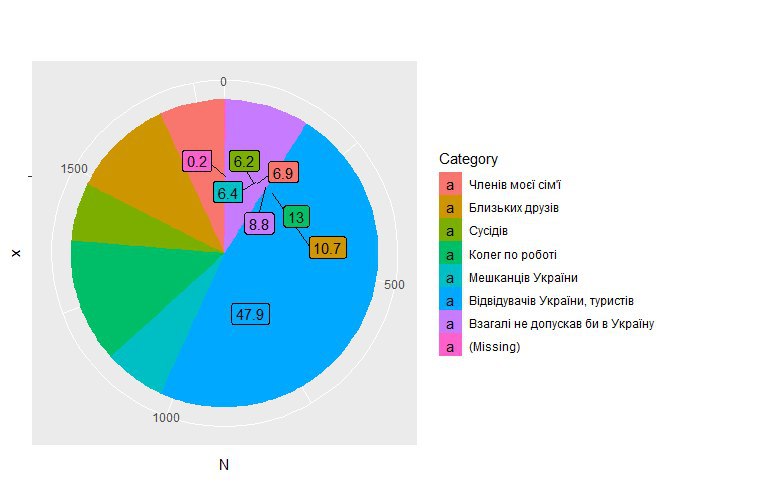
Добрый вечер! ggplot(data = df1, aes(x = "", y = N, fill = Category)) + geom_bar(stat = "identity") + geom_label_repel(aes(label = Percentages)) + coord_polar(theta = "y") Кто может подсказать почему я не могу получить нормальное позиционирование данных?
Добрый вечер! ggplot(data = df1, aes(x = "", y = N, fill = Category)) + geom_bar(stat = "identity") + geom_label_repel(aes(label = Percentages)) + coord_polar(theta = "y") Кто может подсказать почему я не могу получить нормальное позиционирование данных?
Добрый вечер! ggplot(data = df1, aes(x = "", y = N, fill = Category)) + geom_bar(stat = "identity") + geom_label_repel(aes(label = Percentages)) + coord_polar(theta = "y") Кто может подсказать почему я не могу получить нормальное позиционирование данных?
смотрю в интернете – для подписей используют geom_text