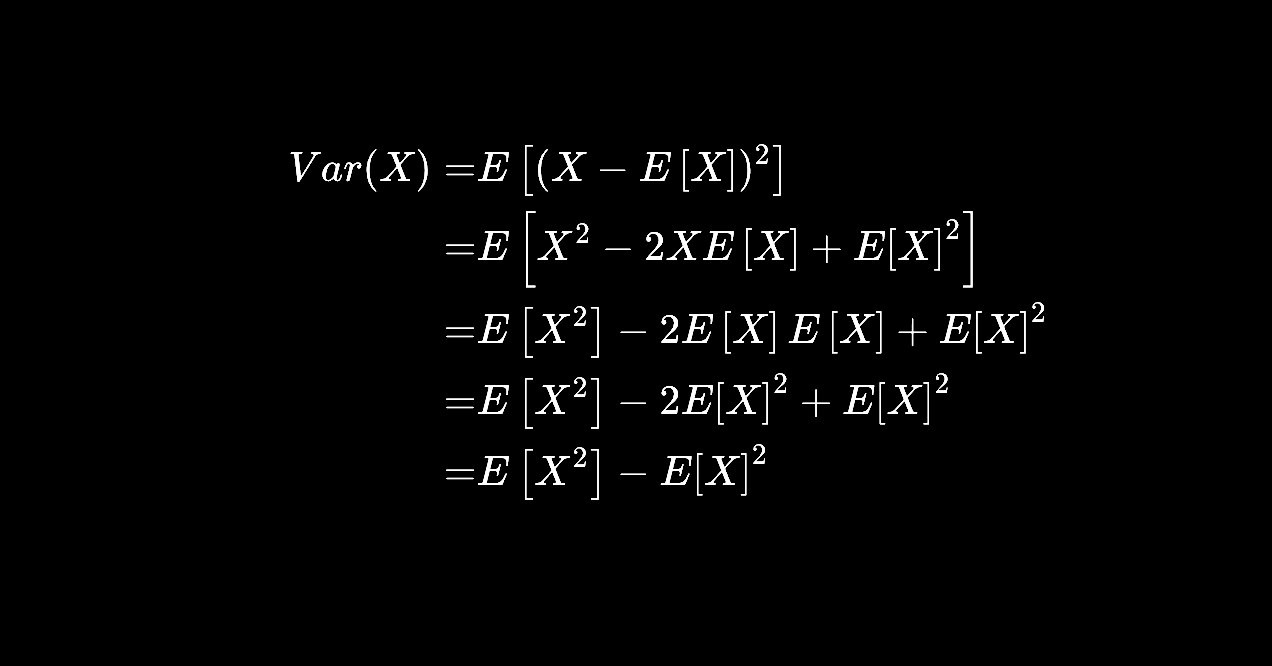ГД
Про статью. Есть интересный кейс, когда агрегирующая функция от нескольких переменных и результат надо положить в переменную с каким-нибудь нормальным именем. Тогда разница между пандас и Р-библиотеками заметна особенно хорошо. В R это выглядит точно так же, как и обычное агрегирование, например, для data.table:
А в пандасе - поля моего телеграмма слишком узки, чтобы написать аналогичный код для пандас
dt_iris[,.(importance = cor(Sepal.Length, Sepal.Width)), by = Species]
А в пандасе - поля моего телеграмма слишком узки, чтобы написать аналогичный код для пандас