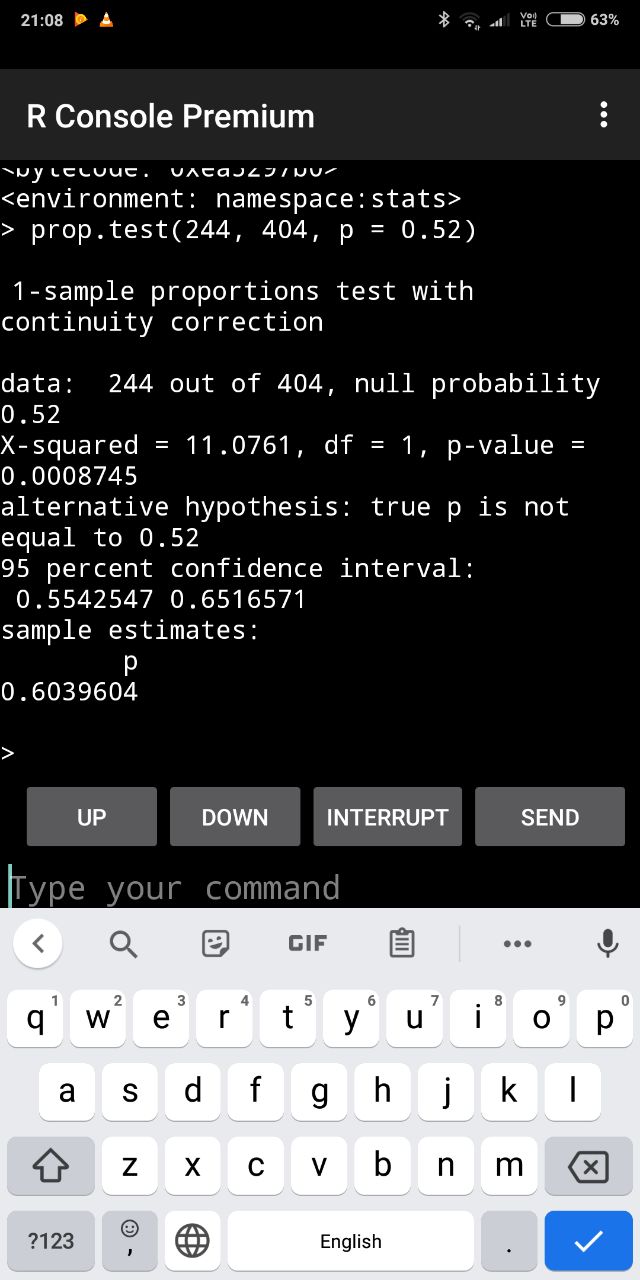
Ну, я хочу перепроверить собственную выборку в магистерской. У меня 404 человека было, из них 244 женщины. Выборка в России набиралась (52% женщин в ней по последним данным). И мне сейчас утверждает один человек, что вероятность набрать случайно такую выборку составляет 0.000001 процент. Я хочу понять, в чём он не прав или прав.
Мне кажется коллега не прав. Если берём перепись 2019 года, то доля мужчин идёт 46,2%. У вас в выборке 49,5%. У нас 95%доверительный интервал получается +- 4,86%...следовательно всё нормально, если я правильно посчитал (просто делал всё быстро руками)