У LR есть несколько минусов:
- цена (не так. ЦЕНА!!!)
- долгое открытие отчётов.
- негибкость отчётов: есть набор графиков, новые не построить.
Но: там есть дофига вызовов, которые заметно облегчают работу.
В том числе - хороший парсер ресурсов, который работает не только при воспроизведении, но и при записи (запросы просто не пишутся, если они воспроизведутся автоматом).
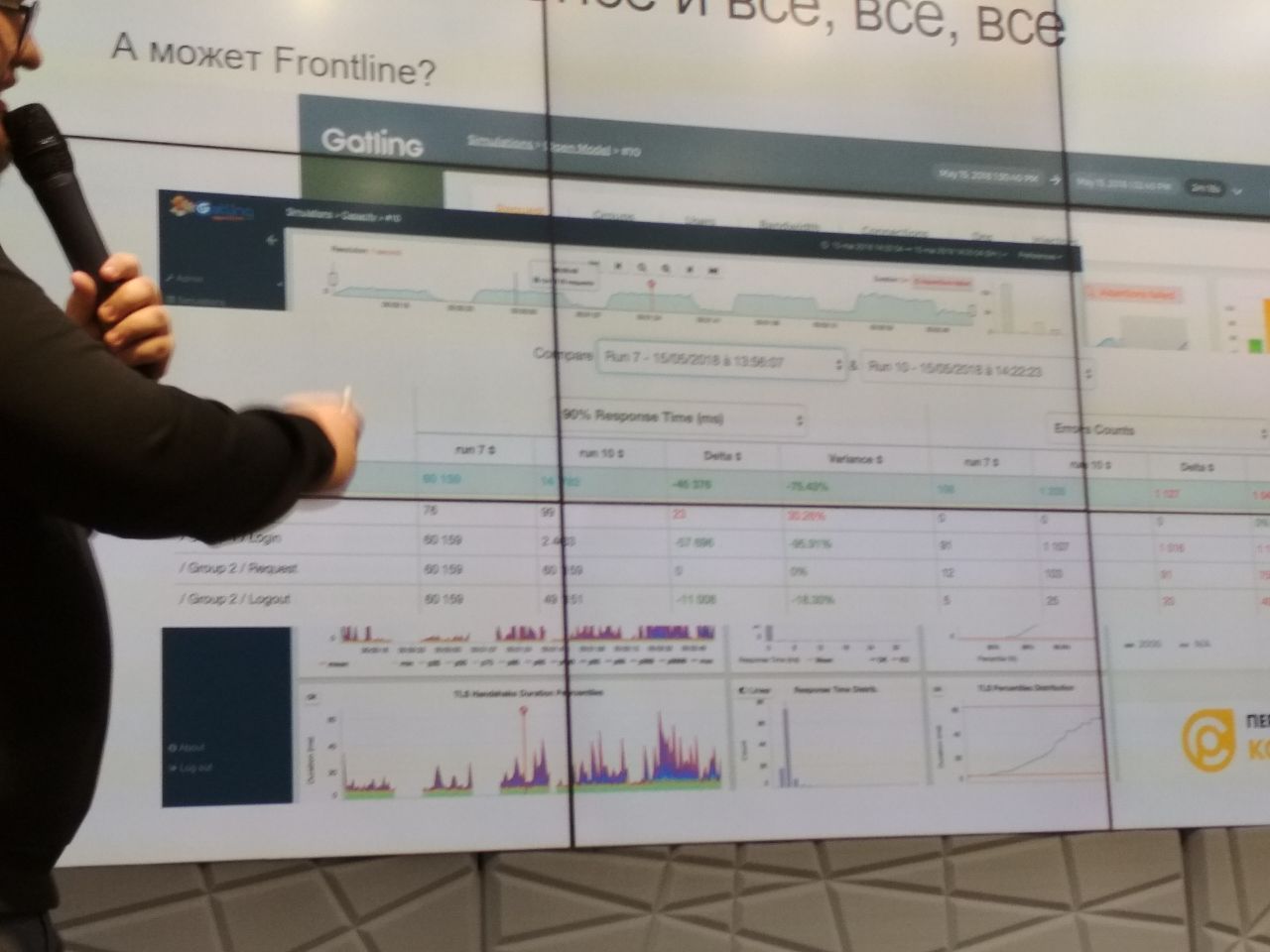
Количество графиков оганичено, но оно огромно, а данные ОЧЕНЬ кастомизируемы.
Их наборы сохраняются в шаблоны и можно строить автоотчёты.
Большое количество протоколов «изкоробки»
Есть свой распределённый запускатор тестов (performance center), который довольно неплох.
про долгое время открытие отчёта, я на сколько помню долго открываются результаты именно из "исходников/сырых данных" но после первого открытия их можно сохранить как "проанализированные" или что-то такое и уже такие данные открываются шустро, вроде бы как-то так.