



АМ
ни разу не было необходимости повторять строки n раз по значению столбца
Ае!👍🏻🙂
Size: a a a
АМ
ФК
ФК
АМ
groups, зачем нужен append и т.д.АМ
OB
AUTH_HEADER = {'Authorization':'OAuth oauth_token=' + oauth_token + ', oauth_client_id=' + oauth_client_id}ФК
MY
groups, зачем нужен append и т.д.АМ
countАМ
count индексы тех строк, которые соответствуют каждому из уникальных count. А потом через repeat индексы повторяются нужное число разMY
MY
OB
oauth_token = '"*****"'ФК
ФК
ВМ
oauth_token = '"*****"'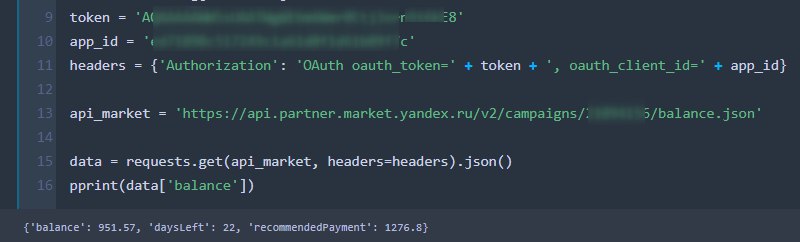
OB
ВМ
OB
ВМ
