



АМ
Тут в чате СА другое мнение у людей)
А что за чатик?
Size: a a a
АМ
AK
К
M
АМ
pivot_table, да groupbyАМ
dd
pivot_table, да groupbyАМ
sn
dd
OB
k
ВЛ
АМ
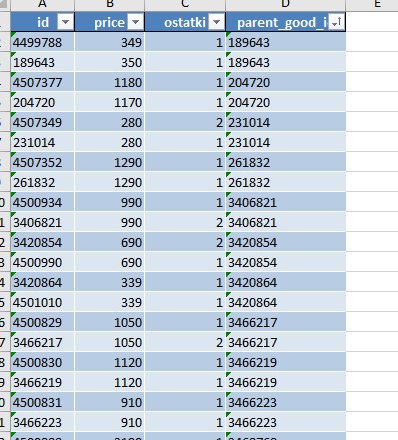
sort_values сначала по нескольким колонкам, by = ['parent_good_id','price','ostatki','id']. Также нужно задать разные ascending = [True, True, False, False]. Вот тут можно посмотреть похожий пример сортировки. А потом уже когда все отсортировано как надо, нужно сделать drop_duplicates(subset=['parent_good_id'])АМ
OB
sort_values сначала по нескольким колонкам, by = ['parent_good_id','price','ostatki','id']. Также нужно задать разные ascending = [True, True, False, False]. Вот тут можно посмотреть похожий пример сортировки. А потом уже когда все отсортировано как надо, нужно сделать drop_duplicates(subset=['parent_good_id'])ВЛ
OB
ВЛ
Е
