Добрый день.
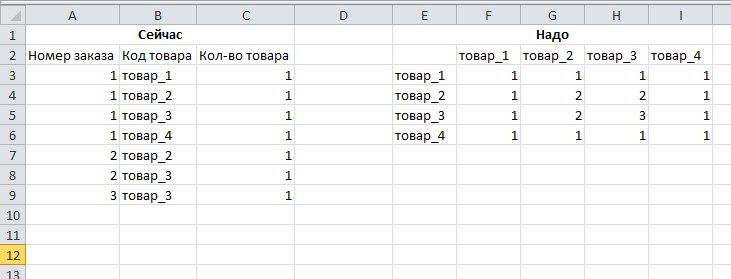
Подскажите пожалуйста, есть таблица с номером заказа, код товара и кол-вом товаров в заказе. Хотел бы это преобразовать в матрицу NxN, где в строках и столбцах были бы все коды товаров, а в ячейках у двух товаров, стояло бы кол-во раз сколько это товары встречаются одних и тех же заказах. Как это преобразование сделать красиво? Циклами как то более менее понятно, но долго и кажется не очень правильно
Я бы сначала представил заказы в виде множеств {SKU1, SKU2, SKU3}. Затем сделал пары через itertools.combinations и преобразовал бы их сразу в множества, то есть одна пара выглядела бы как {SKU1, SKU2}. Потом сделал бы комбинации полученных пар с заказами с помощью itertools.product: [{SKU1, SKU2},{SKU1,SKU2,SKU3}]. И затем в рамках каждой комбинации через функцию issubset определил вы является ли пара подмножеством в заказе. Ну а дальше уже для каждой пары определил бы сколько раз она является подмножеством в заказе