Наткнулся на статью (
http://bit.ly/2YQHSQE) с перечнем рекомендаций для создания хороших тетрадок в Jupyter Notebook. Под «хорошестью» имеется в виду понятность, простота чтения, воспроизводимость. Это крайне важно, если вашей тетрадью будут пользоваться другие люди, и ещё более важно, когда речь идет о тетрадках-туториалах. Эти правила могут показаться «капитанскими», но полезно о них помнить:
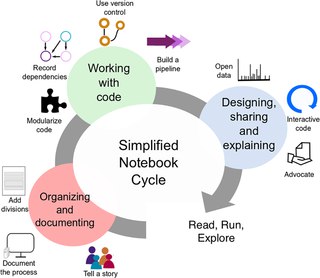
1. Выстраивайте анализ как историю. Комбинируйте код, текст и визуализации в полноценный рассказ. Задумайтесь о том с какой целью вы публикуете тетрадку, кто целевая аудитория, которая будет читать и использовать код.
2. Документируйте процесс, а не только результат. Поэтому не скупитесь на текст, описывайте свои мысли, интересные наблюдения и какие выводы можно сделать из этих наблюдений. Может быть самоочевидным, что делает код, но не всегда из кода очевидно какими соображениями вы руководствовались, какие полезные инсайты получили.
3. Используйте ячейки, чтобы сделать ход алгоритма более ясным. Не пытайтесь запихнуть всё в одну ячейку, но и на каждый чих создавать новую ячейку не нужно. Одна ячейка - это один важный шаг анализа. Полезно давать к каждой ячейке краткий комментарий о том какую функцию она выполняет.
4. Не повторяйте себя. Несмотря на то, что тетрадки очень сильно склоняют к тому, чтобы делать множество почти одинаковых ячеек, создавайте функции для повторяющихся действий, делайте код модульным. Особенно это касается различных функций для вывода визуализаций, однотипных алгоритмов обработки данных.
5. Описывайте зависимости. Давайте исчерпывающее описание необходимых библиотек и их версий. Также можно генерировать файл с конфигурацией окружения, в котором запускался ноутбук. Ну а если вы дружите с докером, то можно даже сделать отдельный контейнер (хотя это существенно усложняет порог использования тетрадки, но если вы публикуете её для технически подкованных людей, то это может иметь смысл).
6. Используйте системы контроля версий. Это позволит отслеживать изменения и эффективнее управлять ими, например, быстро откатываться к предыдущей версии. На эту тему есть хорошая статья «How to Version Control Jupyter Notebooks». (
https://nextjournal.com/schmudde/how-to-version-control-jupyter)
7. Выстраивайте полноценный пайплайн обработки данных. Идеально воспроизводимый анализ должен выполняться от А до Я без необходимости что-то обрабатывать вручную. Например, если вы предобрабатываете данные, то делайте это в ноутбуке. Также полезно делать ноутбуки параметризируемыми, чтобы быстро перезапускать весь процесс с другими входными данными. В этом может помочь Papermill. (загуглите, кто ещё не)
8. Вместе с ноутбуком старайтесь публиковать и данные. Не всегда это возможно из-за того, что датасет большой или содержит конфиденциальные данные. Но можно выложить отдельный кусок или попробовать нагенерить что-то похожее, если датасет непубличный.
9. Постарайтесь сделать так, чтобы ноутбук был читабельным, воспроизводимым и кастомизируемым. Смотри правила 3, 5 и 7.
10. Будьте тем, кто применяет эти правила. Будь то работа, ваша open-source активность или соревнования на Кагле. Чем больше будет воспроизводимых, читабельных и полезных ноутбуков - тем выше уровень открытости данных и компетенций.
Оригинал статьи:
https://doi.org/10.1371/journal.pcbi.1007007. В самой статье есть ссылка на GitHub с парочкой примеров «хороших» тетрадок.
Медиум для шера
http://bit.ly/2YZJym0